거대언어모델 기반 로봇 인공지능 기술 동향
Technical Trends in Artificial Intelligence for Robotics Based on Large Language Models
- 저자
-
이준기에너지지능화연구실 jungi@etri.re.kr 박상준에너지지능화연구실 sjpark86@etri.re.kr 김낙우에너지지능화연구실 nwkim@etri.re.kr 김에덴에너지지능화연구실 kimed93@etri.re.kr 고석갑에너지지능화연구실 softgear@etri.re.kr
- 권호
- 39권 1호 (통권 206)
- 논문구분
- 일반논문
- 페이지
- 95-105
- 발행일자
- 2024.02.01
- DOI
- 10.22648/ETRI.2024.J.390109
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- In natural language processing, large language models such as GPT-4 have recently been in the spotlight. The performance of natural language processing has advanced dramatically driven by an increase in the number of model parameters related to the number of acceptable input tokens and model size. Research on multimodal models that can simultaneously process natural language and image data is being actively conducted. Moreover, natural-language and image-based reasoning capabilities of large language models is being explored in robot artificial intelligence technology. We discuss research and related patent trends in robot task planning and code generation for robot control using large language models.
Share
Ⅰ. 서론
최근 인공지능의 발전에 따라 많은 분야에 인공지능 기술이 접목되고 있다. 특히 자연어 처리 분야에서는 수백 기가바이트에서 수백 테라바이트 규모의 텍스트 데이터를 학습해 특정 도메인에 종속되지 않는 거대언어모델(LLM: Large Language Model)의 개발이 활발하게 진행되고 있다. OpenAI의 GPT(Generative Pre-trained Transformer)나 Google의 BERT(Bidirectional Encoder Representations from Transformers)와 같은 거대언어모델은 트랜스포머(Transformer) 구조를 기반으로 사전 훈련된 대규모 데이터 세트를 기반으로 범용적인 자연어 처리 작업에서 뛰어난 성능을 보인다.
이를 기반으로 다양한 자연어 처리 관련 작업에서 별도의 학습이나 파인튜닝 과정 없이도 자연어에 대한 일반적인 상황 추론 능력 및 문제 해결, 프로그래밍 코드 생성 기능 등을 가지고 있다.
이에 Google 등을 필두로 하는 세계적인 대기업에서는 거대언어모델을 기반으로 하는 로봇의 작업 계획, 로봇 행동 제어를 위한 프로그래밍 코드 생성에 관한 연구를 진행하고 있다. 본고에서는 이와 같은 거대언어모델 기반 로봇 인공지능 활용 기술에 관한 최근 기술 동향을 소개한다.
본고의 구성은 다음과 같다. Ⅱ장에서 기존의 로봇 인공지능 기술과 거대언어모델 기반 로봇 인공지능 기술에 대해 소개하고, Ⅲ장에서는 거대언어모델 기반 로봇 인공지능 연구 동향에 대해 소개한다. Ⅳ장에서는 거대언어모델 기반 로봇 행동 코드 생성 연구 동향에 대해서 소개하고, Ⅴ장에서는 거대언어 모델 기반 로봇 인공지능 기술 관련 특허 동향을 살펴본다. 마지막으로 Ⅵ장에서 결론을 제시한다.
Ⅱ. 거대언어모델 기반 로봇 인공지능 기술 개요
1. 기존 로봇 인공지능 기술
로봇 분야에 다양한 인공지능 기술이 적용되고 있다[1-4]. 특히 로봇 인지(Recognition) 분야 인공지능 기술이 많이 연구되고 있다. 로봇 비전, 객체 인식 및 추적, 상황인지, 자율주행 등의 분야에 딥러닝 기술이 접목되어 성능을 높이고 있다.
로봇의 임무 분석, 작업 계획, 로봇 제어를 위한 인공지능 기술은 강화학습을 중심으로 연구되고 있다. 로봇을 제어하기 위한 딥러닝 모델의 학습은 정해진 도메인에서 로봇의 행동에 보상함수 등을 통해서 강화학습을 진행한다. 기존 연구들은 로봇 팔의 그리퍼를 기반으로 하는 픽앤플레이스(Pick & Place), 펙인홀(Peg-In-Hole), 빈 피킹(Bin-picking), 물체 파지(Object Grasping), 스태킹(Stacking), 내비게이션(Navigation) 등 특정 작업 수행에 강화학습 및 딥러닝 기술을 적용하고 있다.
기존 연구는 특정 작업을 수행하는 것에 집중하고 있어, 다양한 로봇의 행동이나 능동적인 작업 계획을 위해서는 더 상위 단계, 즉 임무 분석, 작업 조합, 작업 계획 등에서의 연구가 필요하다. 로봇이 다양한 영역에서 다양한 임무를 수행하기 위해서, 로봇 인공지능은 객체 인식 및 로봇 팔 제어, 로봇 이동 등의 각 요소 기술을 완벽하게 조합하여 자연어로 제시된 여러 가지 명령을 수행할 수 있어야 한다.
2. 거대언어모델 기반 로봇 인공지능 기술
거대언어모델의 일반 상식과 추론 능력을 활용하여 로봇이 수행할 명령을 이해하고, 로봇이 수행할 명령을 요소 기술로 나누는 작업 계획, 로봇의 요소 기술을 수행하는 제어 코드 생성을 수행하여 로봇의 모든 과정을 자동화하는 것이 가능하다.
로봇의 작업 계획(Task Planning)은 로봇이 수행하고자 하는 특정 임무를 명확하게 정의하고, 이를 수행하기 위해 필요한 요소 행동들을 최적의 순서대로 나열하여 계획하는 것이다. 기존 로봇 작업 계획을 효율적으로 수행하기 위해서 헝가리안 알고리즘 등 여러 가지 알고리즘을 사용하거나, 조립계획서와 같은 작업 계획에 대한 데이터 세트를 딥러닝 모델의 학습을 통해서 수행하는 방법이 있었다. 그러나 거대언어모델의 추론 능력을 기반으로 로봇이 수행할 작업을 입력하면 해당 작업을 수행하기 위한 요소 행동들을 계획해 주는 것에 대한 연구가 진행되고 있다.
GPT나 BERT와 같은 거대언어모델에 원하는 답변을 얻기 위해서 입력 시퀀스를 입력하는 것을 프롬프팅(Prompting)이라고 일컫는데, 어떻게 프롬프팅을 하느냐에 따라서 거대언어모델의 답변이 달라지기 때문에 최근에는 프롬프트 엔지니어링이라는 분야가 발전되기도 하였다. 프롬프트 엔지니어링 기법을 통해서 로봇이 수행할 임무에 대한 작업 계획이나 로봇을 구동하는 프로그래밍 코드를 출력으로 얻기 위해서 Chain-of-thought [5]라는 방법이 활용될 수 있다.
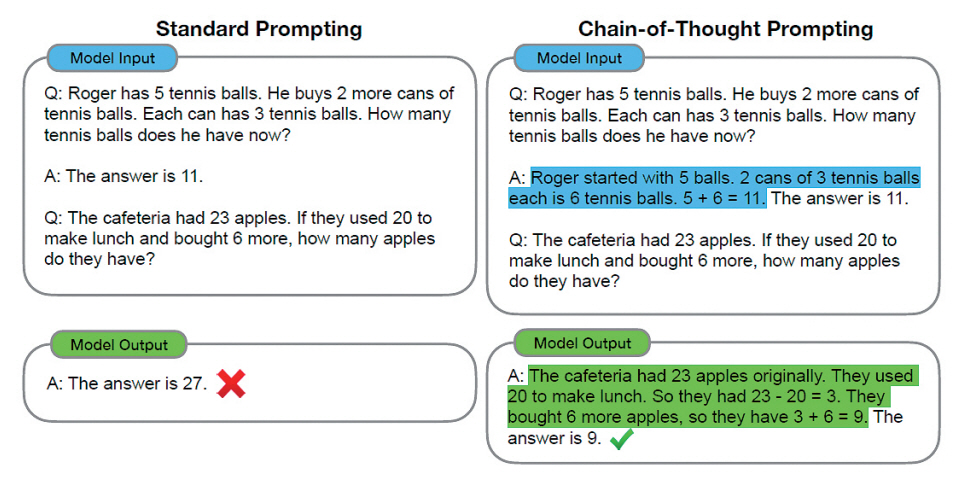
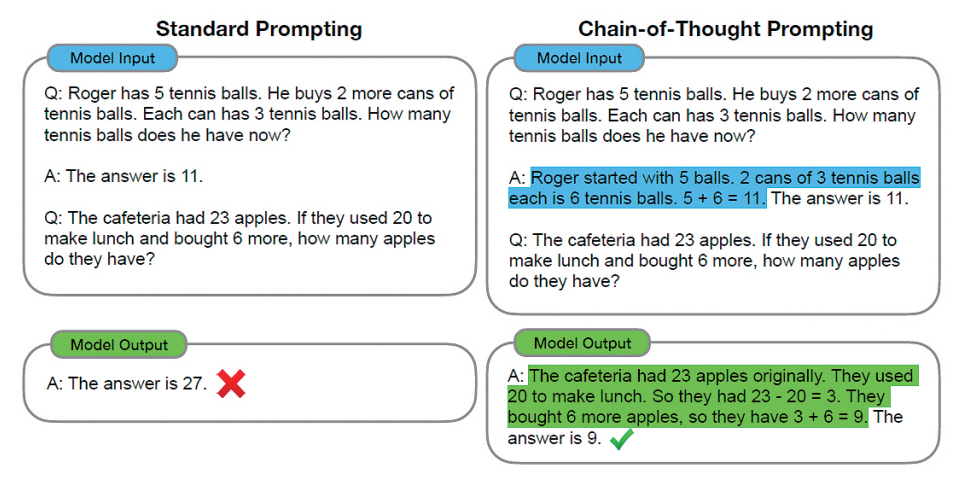
Chain-of-thought 추론은 복잡한 문제를 해결하기 위해서 사람의 사고 과정을 모방하는 거대언어모델의 능력이다. Chain-of-thought 프롬프팅은 거대언어모델에 프롬프팅을 통해 어떠한 문제와 답을 입력하여 유사한 문제에 대한 추론 능력을 부여하기 위한 few-shot learning의 일종이라고 볼 수 있다[6]. 이러한 추론 능력을 부여하는 프롬프팅의 예시로 그림 1에서 왼쪽의 standard prompting의 경우 입력으로 수학 문제와 답변을 제공하고 비슷한 유형의 수학 문제를 질문하였을 때, 거대언어모델이 오답을 출력하는 것을 확인할 수 있다. 그러나 오른쪽의 Chain-of-thought 프롬프팅의 경우 같은 수학 문제를 입력하는데 예시로 제공한 문제의 답변과 함께 해당 수학 문제를 푸는 풀이 과정을 제공하면, 비슷한 유형의 문제를 주었을 때 풀이 과정과 함께 정답을 출력하는 것을 확인할 수 있다. 이러한 Chain-ofthought의 특성은 언어모델의 추론 성능을 향상하기 위하여 특정 분야에 대한 데이터 세트를 추가하고 새롭게 학습하는 방식이 아닌 몇 개의 예제를 통해 원하는 분야의 해답을 도출할 수 있도록 하는 방법이다. 이러한 방식을 로봇 인공지능 기술에 활용할 수 있다.
Ⅲ. 거대언어모델 기반 로봇 인공지능 연구 동향
1. SayCan
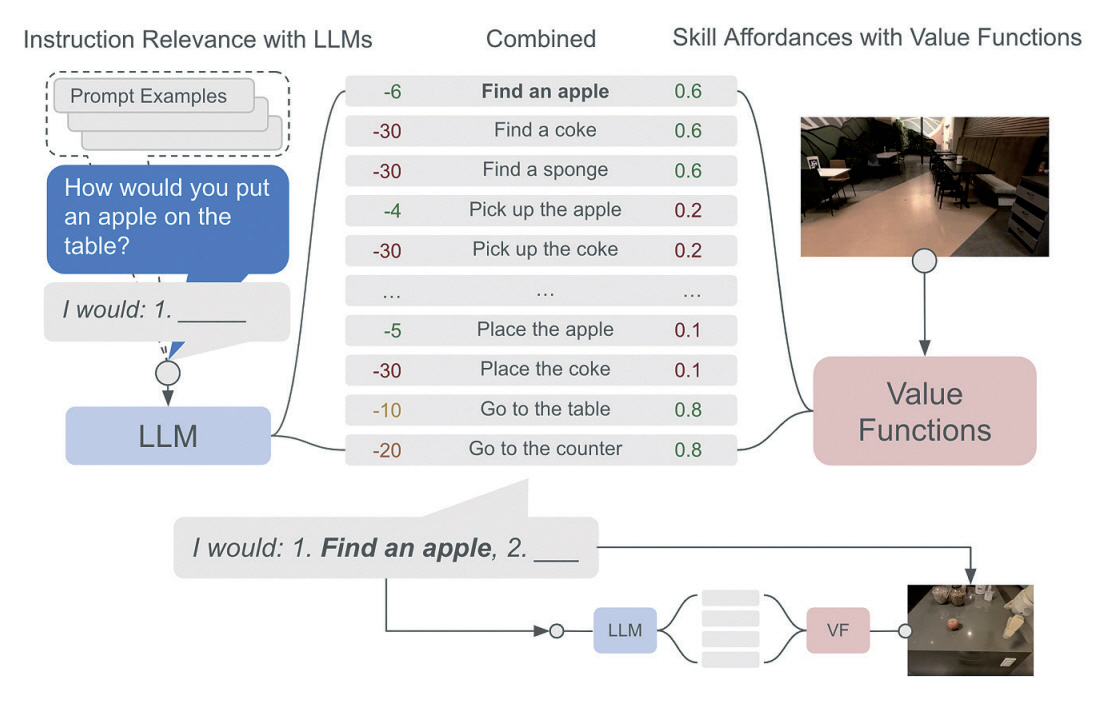
Google에서 개발한 SayCan [7]은 로봇이 자연어 기반의 명령을 수행할 수 있도록 거대언어모델과 로봇의 어포던스(Affordance)를 결합하는 방법이다. 어포던스는 어떤 행동을 유도한다는 뜻으로, 로봇 어포던스는 로봇이 특정 상황이나 물체를 인식하여 어떤 행동을 할 수 있다는 가능성에 대한 것이다.
SayCan은 그림 2와 같이, Say에 해당하는 거대언어모델과 Can에 해당하는 로봇 어포던스 함수로 이루어진다. 거대언어모델은 로봇이 임무를 수행하기 위해 사용이 가능한 스킬들의 연관성을 기반으로 점수를 매기는 역할을 한다. 예를 들어 로봇이 사과를 테이블에 올리는 임무를 받았을 때, 사과를 찾는 행동은 높은 점수를 받게 되고 그와 연관이 적은 콜라를 찾는 행동은 낮은 점수를 받게 되는 것이다.
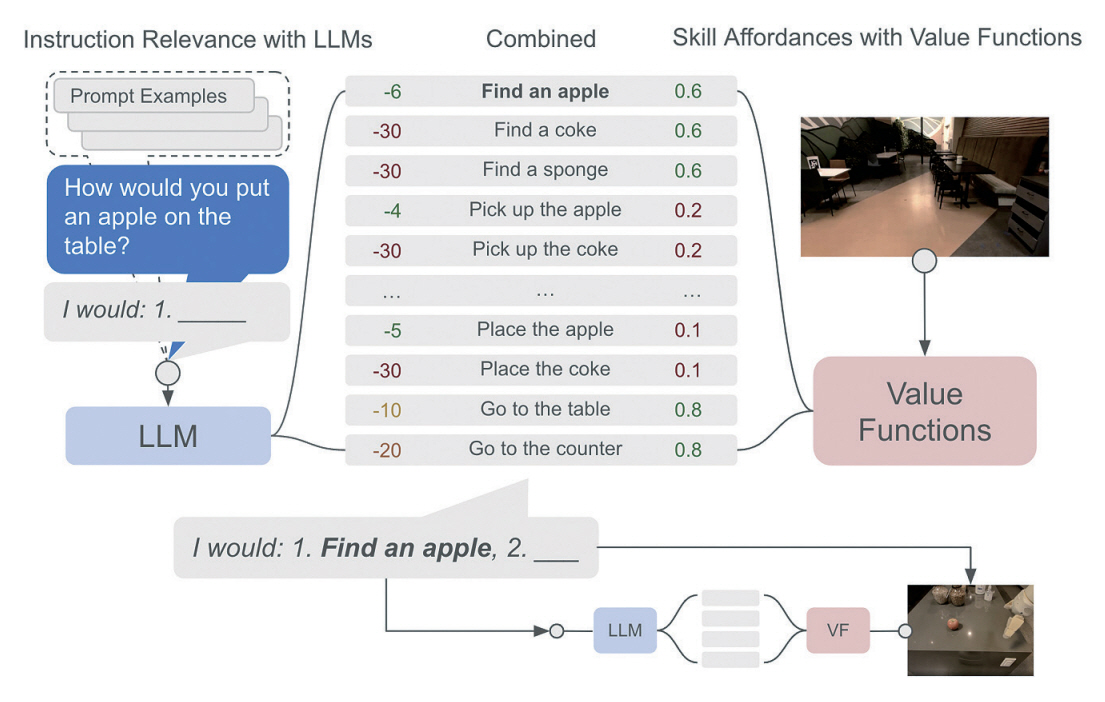
그리고 로봇 스킬(Robotic Skills)은 강화학습(RL: Reinforcement Learning)이나 행동 복제(BC: Behavior Cloning)를 통해서 학습된 정책을 가치함수의 형태로 어포던스를 나타낸다. 이러한 어포던스는 각 상황에서 로봇 스킬이 성공적으로 수행될 확률을 나타내게 된다. 거대언어모델이 추정한 로봇 스킬의 연관성 점수와 가치함수를 통해 계산된 스킬 어포던스의 곱을 통해서 가장 최적화된 스킬을 결정해 수행하는 것을 반복하며 목표를 끝까지 수행할 수 있다.
SayCan은 구글의 언어모델인 PaLM(Path-ways Language Model)과 SayCan을 연결한 PaLM-SayCan 모델을 통해서 현실의 주방과 같은 환경에서도 추상적인 자연어 기반 명령에 대해 높은 수행 능력을 보였다.
2. PaLM-E
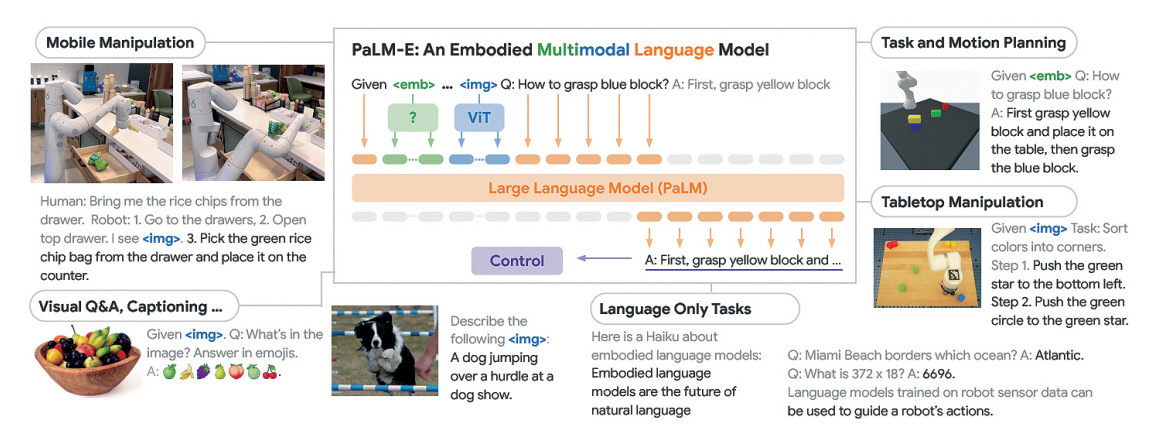
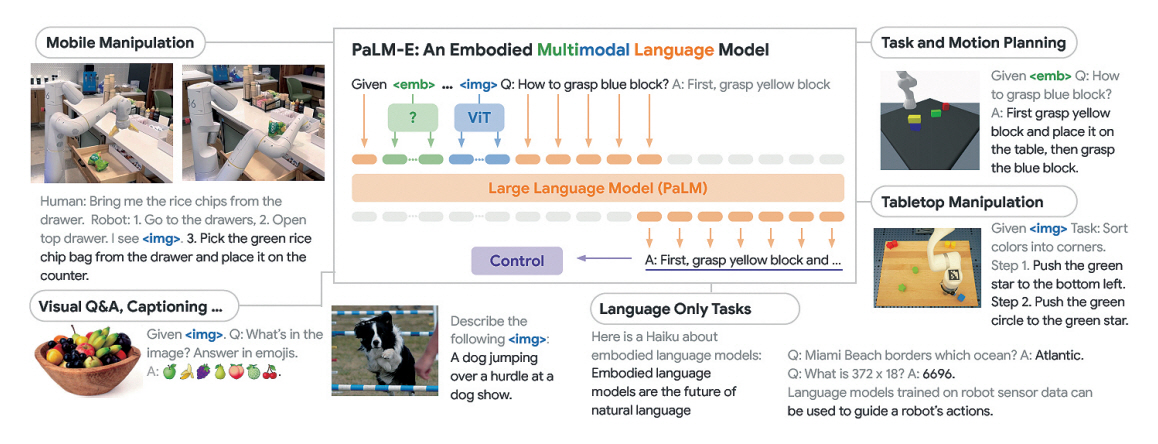
PaLM-E [8]는 Google에서 개발한 텍스트와 이미지를 처리할 수 있는 체화된(Embodied) 멀티모달 시각 언어모델(VLM: Vision-Language-Model)로, Google의 언어모델 PaLM에 로보틱스 관련 데이터를 학습하여 로봇의 추론 능력을 위해 개발된 모델이다.
PaLM-E는 PaLM에 비전 트랜스포머 모델 ViT-22B를 결합하여 여러 가지 비전 작업을 수행할 수 있도록 구현되었다. PaLM-E는 이미지 및 텍스트 입력을 모두 자연어 단어 토큰 임베딩으로 변환하여 이미지 입력과 텍스트 입력이 같은 차원으로 되어 입력의 종류와 무관하게 하나의 모델로 학습 가능하다는 특징을 가지고, 이를 통해서 로보틱스, 비전, 자연어 처리 분야에서 높은 성능을 보였다. PaLM-E는 그림 3과 같이 실제 로봇 플랫폼을 기반으로 시각적 질의응답, 이미지 캡션, 자연어 처리, 그리고 여러 가지 자연어 명령에 대한 로봇 작업 계획을 수립하고, 이를 수행하는 결과를 보였다. 그리고 PaLM-E는 학습 단계에서 본 적이 없는 객체에 대한 명령을 수행할 수 있는 Zero-shot Task에 대한 수행 능력이 있음을 보였다.
3. RT-1
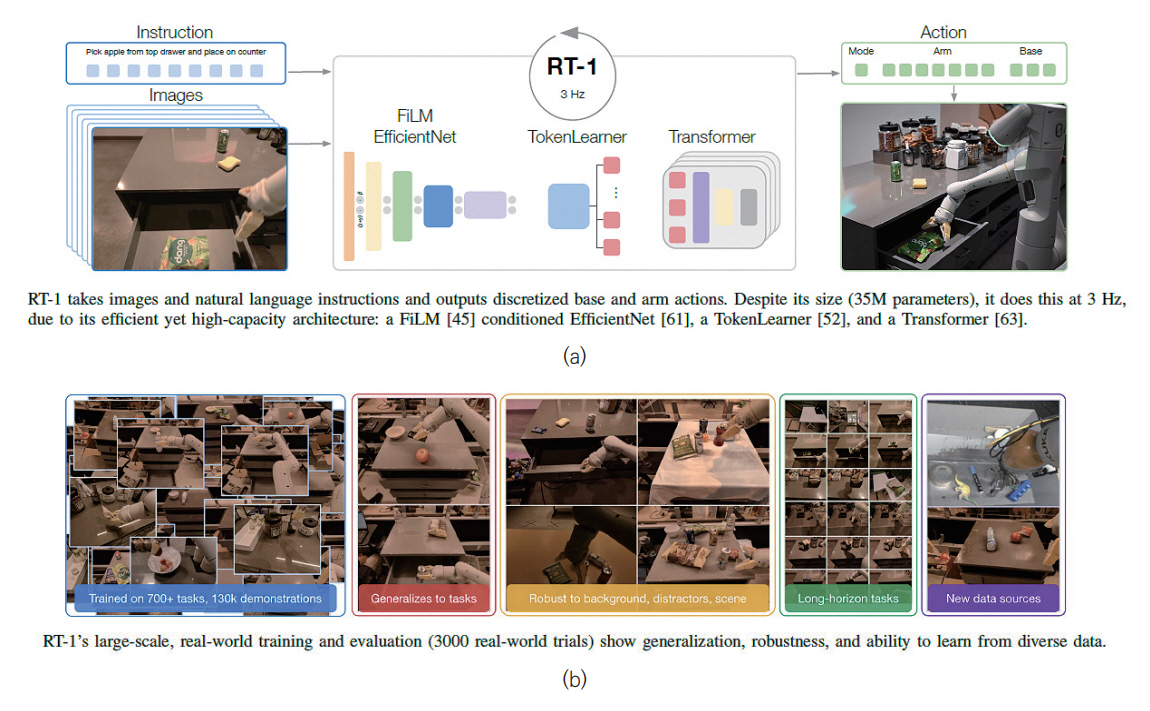
Google의 RT-1(Robotics Transformer)은 트랜스포머 모델을 기반으로 로봇이 상황을 인지하고, 문제를 해결하기 위한 행동을 단계적으로 구분하여 수행하도록 구현한 모델이다[9]. RT-1 모델은 그림 4와 같이 트랜스포머 구조를 기반으로 구축되어 연속적으로 입력되는 이미지 정보 및 자연어에 대해 처리하는 능력이 뛰어나며, 이를 기반으로 로봇이 임무를 수행하기 위해서 적합한 동작을 생성하는 데 최적화되어 있다.
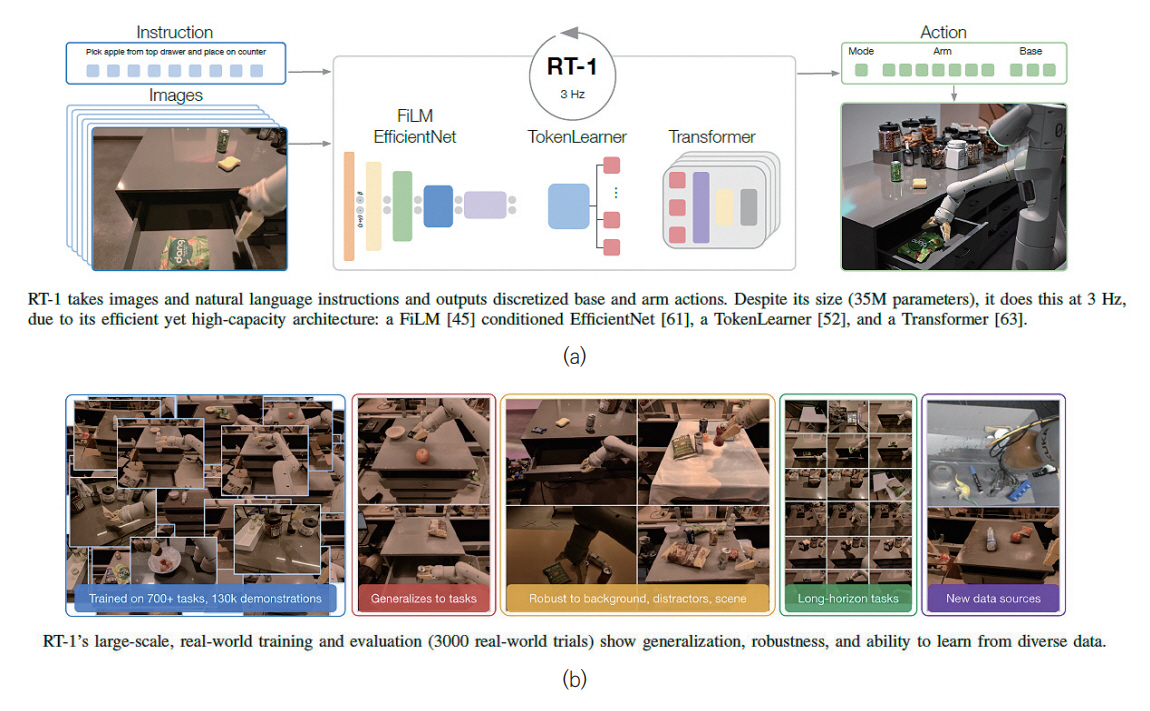
RT-1 모델은 특정 명령과 상응하는 이미지 데이터 세트를 입력으로 받아서, EfficientNet을 기반으로 이를 토큰화하고, Token Learner를 통해서 이를 압축한다. 그 후 트랜스포머 구조를 기반으로 로봇이 수행할 행동에 대한 Action Token을 출력하여 명령을 수행하기 위한 행동을 수행하게 된다.
해당 모델을 구현하기 위해서 Everyday Robots의 로봇 플랫폼 13대를 사용해서 테스트베드에 실제 구축한 부엌 환경에서 700가지 이상의 로봇 작업에 대해 130,000번의 에피소드 분량의 데이터 세트로 훈련을 진행하였다. 그리고 RT-1 모델의 성능을 향상하기 위해서 Kuka 로봇의 빈 피킹 에피소드 209,000개를 학습에 활용하여 RT-1이 다른 로봇 플랫폼의 경험을 학습하여 새로운 작업까지 습득 가능한 것을 확인하였다.
4. RT-2
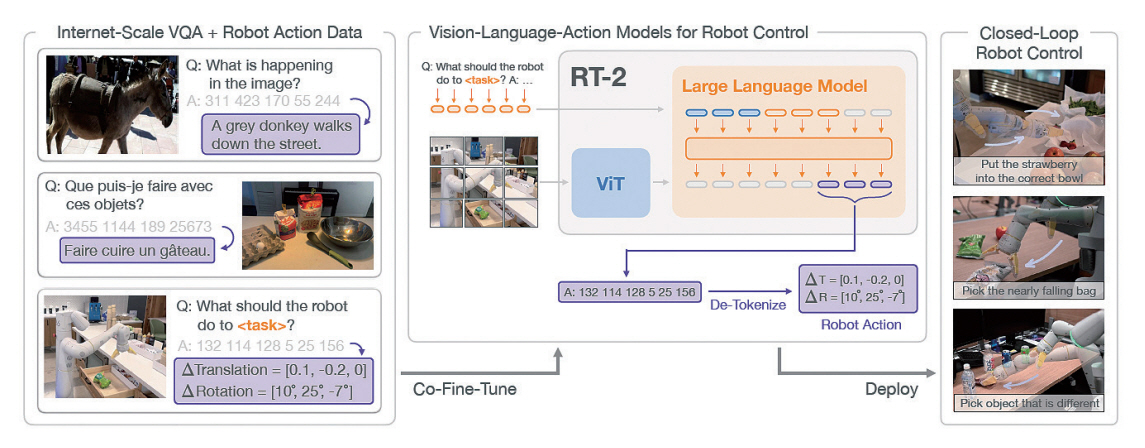
Google Deepmind에서는 기존 RT-1을 기반으로 웹 규모의 VQA(Visual Question Answering) 데이터와 로봇의 행동 데이터를 기반으로 학습한 RT-2 모델을 발표하였다[10]. RT-2는 VLA(Vision-Lan-guage-Action)모델로서, 이미지와 지침을 입력받아 거대언어모델, VLM 및 로봇 컨트롤러 역할을 수행할 수 있다.
기존 RT-1 모델의 경우 Everyday Robots 및 다른 로봇에서 취득한 데이터를 기반으로 학습이 진행되어 학습에 사용된 데이터와 연관된 작업에 특화된 모습을 보여주었으나, RT-2는 그림 5와 같이 웹 규모 데이터가 가진 일반적인 상식 추론 능력과 로봇 제어 데이터를 기반으로 처음 보는 객체에 대한 일반화 능력, 기존 로봇 훈련 데이터 세트에 없었던 새로운 명령을 해석하는 능력, 추상적인 명령에 응답하여 추론 과정을 수행하는 능력을 갖추게 되었다.
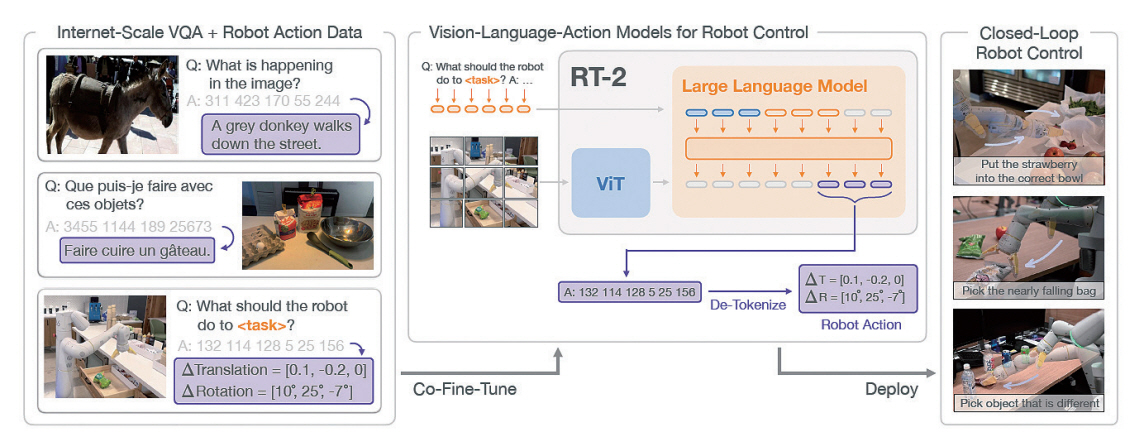
RT-2는 PaLM-E와 PaLI-X [11]를 기반으로 RT-2-PaLM-E, RT-2-PaLI-X 두 가지 모델을 구현하였으며, 두 모델 모두 웹 규모 데이터에서 얻어온 일반적인 상식을 통해서 학습에 사용되지 않은 unseen objects, unseen backgrounds, unseen environments에서 작업 성공률이 RT-1에 비해 월등하게 향상된 것을 확인할 수 있다. 그리고 symbol understanding, reasoning, human recognition과 같은 상황 추론 능력도 향상된 결과를 나타냈다. 이는 인터넷 규모의 데이터를 기반으로 한 모델이 로봇 행동 데이터에 없는 여러 가지 상황에서의 행동 토큰을 출력하고 명령을 수행하는 데 있어 도움을 줄 수 있다는 것을 보여준다.
5. RT-X
RT-X는 Google Deepmind와 33개의 연구소가 협력하여 구축한 Open X-Embodiment 데이터 세트[12]를 기반으로 만든 새로운 로봇 트랜스포머 모델이다. 기존 컴퓨터 비전이나 자연어 처리를 위한 대규모 데이터 세트는 로봇 모델을 위해 활용할 수 있지만, 이는 너무 광범위하고 일반적인 정보를 지니기 때문에 구체적인 로봇의 상호작용을 위한 데이터셋으로 활용할 수 없다는 한계를 가졌다. 이러한 한계를 극복하기 위해 구축된 Open X-Embodiment 데이터 세트는 22개의 로봇 플랫폼에서 500개 이상의 스킬, 150,000개의 작업이 포함된 100만 개 이상의 에피소드를 포함하며 로봇 분야에서 광범위하게 활용될 수 있도록 구축되었다.
RT-X는 Open X-Embodiment 데이터 세트를 RT-1과 RT-2 모델을 기반으로 9개의 로봇 플랫폼에 학습하여 각각 RT-1-X, RT-2-X 모델을 구현하였다. RT-1-X는 문 열기와 같은 특정 작업에서 기존 RT-1에 비해 50% 나은 성능을 보였고, RT-2-X는 응급 기술 분야에서 기존 SOTA 모델인 RT-2에 비해 3배 더 성공적인 결과를 보였다.
이는 같은 로봇 트랜스포머 구조를 기반으로 서로 다른 로봇 플랫폼에서 모델을 학습 후 취득한 다양한 데이터 세트를 기반으로 추가 학습을 진행하였을 때, 개별적인 로봇을 위해 학습한 모델보다 작업 수행 능력을 개선할 수 있다는 것을 시사한다.
Ⅳ. 거대언어모델 기반 로봇 행동 코드 생성 연구 동향
앞서 설명한 Chain-of-thought 프롬프팅을 활용하여 원하는 프로그래밍 코드를 얻어낼 수 있다. 이러한 기법을 활용하여 로봇을 원하는 대로 제어하거나 로봇이 특정 명령을 수행하기 위한 코드를 생성하는 데 활용할 수 있다. 이 장에서는 이러한 특성을 활용하여 로봇의 작업 계획과 그에 대응하는 로봇 행동 코드를 생성하는 연구 동향에 대해 소개한다.
1. Code-as-policies
Code-as-policies(CaP) [13]는 Google에서 개발한 로봇이 명령을 수행하기 위한 작업 계획 및 코드 생성 기법으로, GPT-3의 추론 능력을 기반으로 한다. CaP는 그림 6과 같이, 사용자가 자연어 명령을 주면 LLM을 이용하여 명령을 수행하기 위한 코드를 생성한다.

CaP에서는 거대언어모델에 프롬프팅을 통해서 예시 코드들을 제공하여 few-shot learning을 진행한다. 이때 예시 코드에 대응되는 주석을 제공하여 특정 코드가 어떤 상황에 대응되는 코드임을 거대언어모델이 학습할 수 있도록 한다. 거대언어모델이 생성한 코드를 LMP(Language Model generated Programs) 라고 한다. CaP는 Python 기반의 LMP를 사용하며, 복잡한 로봇 정책을 표현하기 위해서 if/else 조건문과 Python 라이브러리 NumPy, Shapely를 사용한다. 로봇이 명령을 수행하기 위한 LMP를 생성하는 프롬프트는 다음과 같이 구성된다. 먼저 힌트(Hints)는 어떤 API를 로봇의 제어 코드에 사용할 수 있는지 알려주는 import 문과 이러한 API를 사용하는 방법에 대한 내용이다. 두 번째로 examples는 로봇에 내린 자연어 명령을 코드로 변환하는 방법에 대한 few-shot instruction-to-code 쌍으로 이루어진다. 이러한 프롬프트를 GPT-3에 입력한 후에 새로 생성하기를 원하는 명령에 대한 내용을 주석의 형태로 프롬프팅하면 언어모델은 그에 대응하는 코드를 출력하게 된다. GPT-3는 여러 유명 Python 라이브러리에 대한 지식이 사전에 학습되어 있으므로, 힌트로 원하는 Python 라이브러리를 지정하고, 주석으로 원하는 로봇이 수행하길 원하는 명령(Instruction) 에 대한 해답 코드를 예시로 제시하면, 이후에 프롬프팅을 통해 원하는 명령을 입력하였을 때 해당 명령에 대한 작업을 수행할 수 있는 코드를 생성한다.
해당 기법은 GPT-3 모델에게 로봇이 사용할 수 있는 API 등의 정보와 예제 코드를 잘 정의하여 거대언어모델에 입력하면, 부가적인 데이터 수집이나 거대언어모델의 학습 과정이 없이 적절한 로봇 정책 코드를 생성할 수 있다는 장점을 가진다. 그리고 LMP는 새로운 함수를 재귀적으로 정의할 수 있어 LMP를 기반으로 생성된 코드의 구문을 분석해서, 정의되지 않은 함수가 있는 경우에 해당 함수를 또다시 LMP를 활용하여 구현할 수 있어, 프롬프트를 사용하는 엔지니어가 모든 구현 사항을 직접 제공하지 않아도 된다는 장점이 있다.
2. ProgPrompt
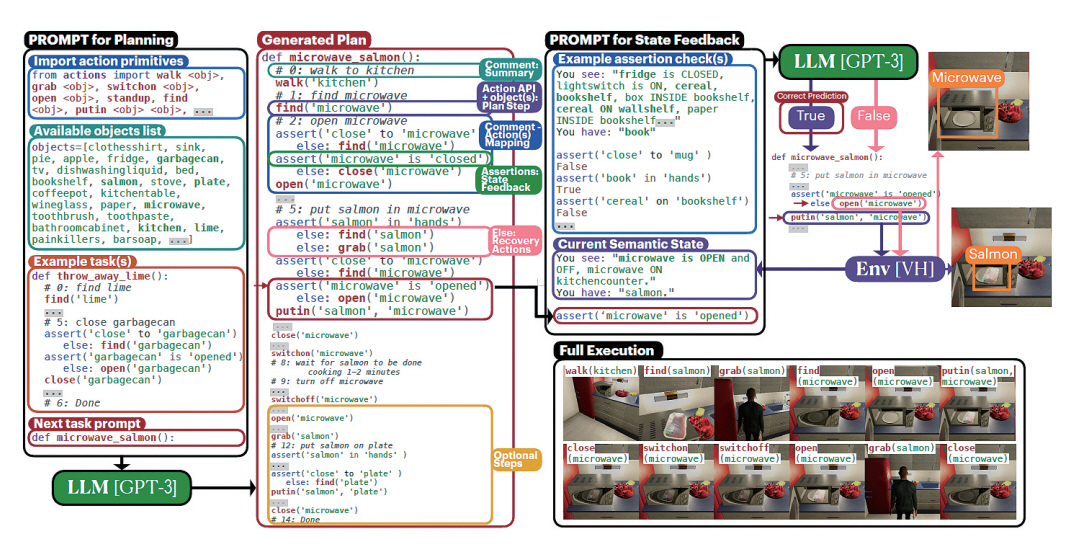
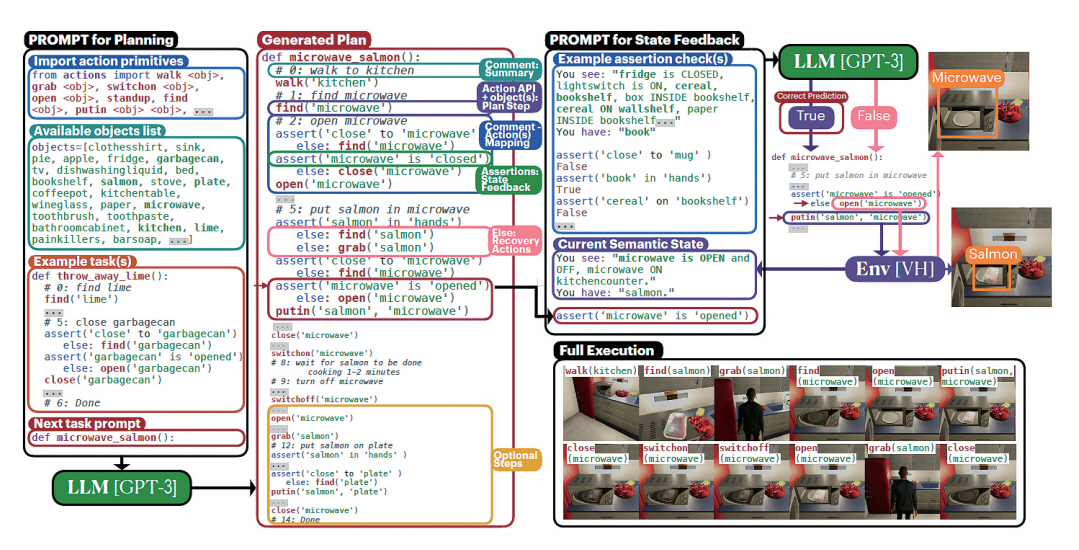
ProgPrompt [14]는 NVIDIA에서 제안한 로봇 작업 계획 및 코드 생성 관련 기법이다. 이 방법은 앞서 설명한 Code-as-policies와 비슷한 방식으로 Python 프로그램의 형태로 로봇의 작업 계획을 표현한다. ProgPrompt는 그림 7과 같이, 로봇에 내려지는 추상적인 명령을 구체적인 환경에 매핑하여 로봇 계획(Robot Plan)을 수립한다. 이때 로봇 계획은 Python 코드의 형태로 표현하게 된다. ProgPrompt의 계획 함수(Plan Function)는 로봇 행동의 기본 요소에 대한 API call, action을 요약하는 주석, action의 실행을 추적하기 위한 assertion으로 구성된다. Robot plan을 위한 프롬프트는 수행할 수 있는 행동들에 대한 요소(Action Primitives), 현재 환경에서 사용할 수 있는 객체 목록(Object list), 수행할 수 있는 로봇의 행동에 대한 함수(Example task)로 구성된다. 해당 프롬프트의 입력 이후에 다음에 수행할 작업에 대한 함수의 이름을 입력하면 GPT-3 모델을 기반으로 해당 작업을 수행하기 위한 함수를 Python 코드의 형태로 출력하게 된다. 본 연구에서는 이러한 방식을 활용하여 Virtual Home 환경 및 실제 로봇 팔을 이용한 실험에서 작업 수행이 가능함을 보였다.
Ⅴ. 거대언어모델 기반 로봇 인공지능 기술 관련 특허 동향
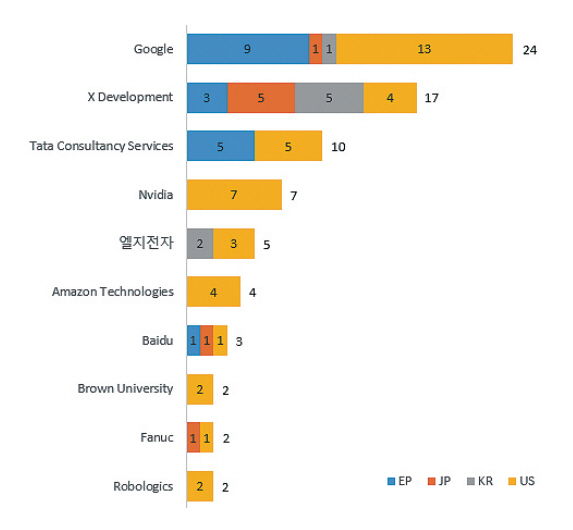
최근 거대언어모델 기반 로봇 인공지능 기술 관련 특허들이 출원 및 등록되고 있다. Google에서는 언어모델을 기반으로 로봇을 학습하는 것과 관련된 특허들을 선점하고 있다. Google에서는 로봇의 자연어 제어에 관한 특허를 출원하면서 거대언어 모델이 자연어 제어에 활용될 수 있다는 점을 명시하였다[15,16]. 그리고 NVIDIA에서는 로봇을 제어하는 것에 LLM을 활용하는 것에 대한 특허들을 출원하였다[17-19]. 그림 8은 언어모델 활용 로봇 행동 적용 분야 관련 다출원인 현황을 나타낸 그림으로, Google과 Alphabet의 자회사인 X development가 가장 많은 특허를 출원한 것으로 파악되며, 국내 업체에서는 엘지전자만이 상위 10위권에 해당 특허를 보유 중인 것으로 파악된다.
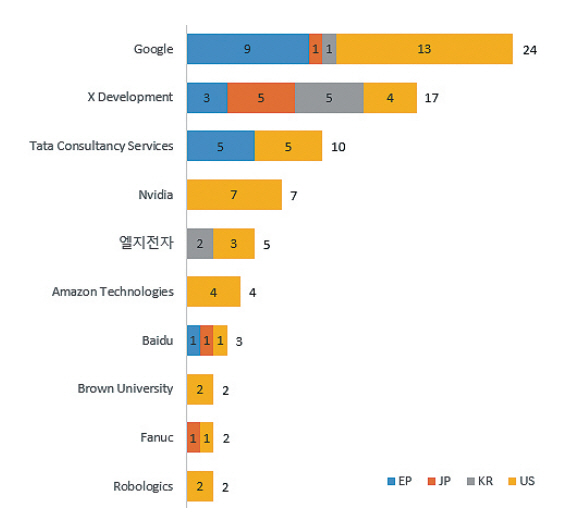
이러한 점으로 미루어 보아 관련한 특허를 선점하는 것이 국외 로봇 시장에서 우위를 점하는 것에 있어서 중요한 요소 중 하나가 될 것을 보인다.
Ⅵ. 결론
본고에서는 거대언어모델 기반 로봇 인공지능 연구 동향에 대해 살펴보았다. 기존의 로봇 인공지능 개발은 특정한 분야의 특정 임무를 수행하기 위해 딥러닝 및 강화학습을 적용하는 연구가 진행되었으며, 최근에는 거대언어모델을 적용하는 로봇 인공 지능 기술 연구가 시작되고 있다. 구체적으로, 거대언어모델 및 거대멀티모달모델(LMM: Large Multimodal Model)을 로봇 인공지능의 임무 분석, 작업 계획, 제어 코드 생성, 자연어 명령 이해 등에 적용하는 연구가 활발히 진행되고 있으며, Google Deepmind를 필두로 NVIDIA 등 세계적인 대기업에서 이 분야를 선도하고 있다.
거대언어모델 기반 로봇 인공지능 연구를 위해서는 인공지능 모델을 학습하고 개발하기 위한 컴퓨팅 환경, 학습을 위한 다양하고 많은 데이터 취득, 다양한 적용 환경에 대한 고해상도 시뮬레이션, 실제 로봇을 운영 및 시험할 수 있는 실증 테스트베드 환경, LLM을 운영 및 개발하기 위한 컴퓨팅 환경 등이 요구된다. 앞으로, 로봇 인공지능용 거대언어모델 및 거대멀티모달모델 연구, 로봇용 경량 멀티 모달모델 연구, 상식을 가진 로봇 인공지능 연구 등이 계속될 것으로 보이며, 우리나라가 로봇 인공지능 분야의 기술을 선도하기 위해서는 많은 투자와 연구가 필요하다.
용어해설
Few-shot Learning 인공지능 모델에 몇 번의 데이터 입력을 통해서 학습이 이루어지게 하는 학습 기법
Prompting 거대언어모델에 원하는 답변을 출력받기 위한 질문이나 문장을 입력하는 것
빈 피킹(Bin-picking) 로봇이 여러 가지 물건 속에서 원하는 물건을 고르는 기술
어포던스(Affordance) 로봇이 수행할 수 있는 행동에 대한 가능성
약어 정리
API
Application Programming Interface
BC
Behavior Cloning
BERT
Bidirectional Encoder Representations from Transformers
CaP
Code-as-policies
GPT
Generative Pre-trained Transformer
LLM
Large Language Model
LMM
Large Multimodal Model
LMP
Language Model generated Programs
PaLI
Pathways Language and Images
PaLM
Pathways Language Model
RL
Reinforcement Learning
RT
Robotics Transformer
ViT
Vision Transformer
VLA
Vision-Language-Action
VLM
Visual Language Model
VQA
Visual Question Answering
L. Kunze et al., "Artificial intelligence for long-term robot autonomy: A survey," IEEE Robot. Autom. Lett., vol. 3, no. 4, 2018, pp. 4023-4030.
M. Brady, "Artificial intelligence and robotics," Artif. Intell., vol. 26, no. 1, 1985, pp. 79-121.
M. Soori, B. Arezoo, and R. Dastres, "Artificial intelligence, machine learning and deep learning in advanced robotics, a review," Cognit. Robot., vol. 3, 2023.
S. Cebollada et al., "A state-of-the-art review on mobile robotics tasks using artificial intelligence and visual data," Expert Syst. Appl., vol. 167, 2021, article no. 114195.
J. Wei et al., "Chain-of-thought prompting elicits reasoning in large language models," in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 24824-24837.
T. Brown et al., "Language models are few-shot learners," in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 1877-1901.
M. Ahn et al., "Do as i can, not as i say: Grounding language in robotic affordances," arXiv preprint, CoRR, 2022, arXiv: 2204.01691.
D. Driess et al., "Palm-e: An embodied multimodal language model," arXiv preprint, CoRR, 2023, arXiv: 2303.03378.
A. Brohan et al., "Rt-1: Robotics transformer for real-world control at scale," arXiv preprint, CoRR, 2022, arXiv: 2212.06817.
A. Brohan et al., "Rt-2: Vision-language-action models transfer web knowledge to robotic control," arXiv preprint, CoRR, 2023, arXiv: 2307.15818.
X. Chen et al., "PaLI-X: On scaling up a multilingual vision and language model," arXiv preprint, CoRR, 2023, arXiv: 2305.18565.
A. Padalkar et al., "Open x-embodiment: Robotic learning datasets and rt-x models," arXiv preprint, CoRR, 2023, arXiv: 2310.08864.
J. Liang et al., "Code as policies: Language model programs for embodied control," in Proc. ICRA, (London, U.K.), May 2023.
I. Singh et al., "Progprompt: Generating situated robot task plans using large language models," in Proc. ICRA, (London, U.K.), May 2023.
P. Shah, Controlling a robot based on free-form natural language input, U.S. Patent 2021-0086353, Mar. 25, 2021.
C.J. Paxton, Interpreting discrete tasks from complex instructions for robotic systems and applications, U.S. Patent 2023-0297074, Sept. 21, 2023.
C.J. Paxton, Semantic rearrangement of unknown objects from natural language commands, U.S. Patent 2023-0073154, Mar. 9, 2023.

- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.