
고광원 (Koh K.W.) 고성능컴퓨팅 SW 연구실 선임연구원
차승준 (Cha S.J.) 미래연구팀 선임연구원
김강호 (Kim K.H.) SW 기초연구센터 책임연구원
김진미 (Kim J.M.) SW 기초연구센터 책임연구원
정성인 (Jung S.I.) SW 기초연구센터 센터장
I. 서론
컴퓨터의 주요 이용 목적은 작업을 빨리 끝내는 것이다. 이를 위해 하드웨어와 소프트웨어는 서로 유기적으로 작동한다. Amdahl의 법칙[1]을 고려해보면, 하드웨어 측면에서는 연산장치의 동작이 더 빨라지고 연산장치의 수가 더 많아지면 된다. 소프트웨어 측면에서는 작업을 잘 분할하여 각 하드웨어 연산장치에 할당하고 연산장치 간에 간섭 없이 병렬적으로 동작하게 하면 된다. 이는 단순하지만 근본적인 발전방향을 의미한다고 볼 수 있다.
컴퓨터 역사의 초기에는 발전방향이 연산장치인 프로세서를 고속화하는 데 있었다. 더 빨라진 프로세서는 배치처리 운영체제를 시분할 방식의 다중처리 운영체제로 변화하게 하였다. 구체적으로 보면 스케줄링, 인터럽트, IO 처리방식 등 모든 면에서 시분할처리 운영체제에 맞게 변화하였다. 결과적으로 시분할 방식의 다중처리 운영체제는 작업의 응답속도를 개선시키고 빠른 프로세서의 동작효율을 향상시켰다.
이와 더불어 다중 프로세서의 출현도 주목할 발전이다. 그러나, 하드웨어 측면에서는 단일 연산장치가 복수의 연산장치로 되는 큰 모멘텀이 있었지만 실제 소프트웨어의 대응은 비교적 적었다. 이는 시스템 내의 물리적인 연산장치인 프로세서 수가 2개, 4개, 혹은 8개 정도로 제한적이었기 때문이다. 제한된 소수의 프로세서는 결국 운영체제에 큰 변화를 이끌만한 촉매제는 되지 않았고 결과적으로 운영체제는 Lock이라는 동기화 도구를 이용하여 약간의 진화만으로도 병렬 다중처리를 실현해 오고 있다.
최근의 프로세서 동향 보고서에 의하면, 몇 년 전까지 프로세서 제조사들은 반도체 집적기술을 주로 프로세서의 연산 최적화와 동작속도 증가에 사용하였으나 최근에는 단일 프로세서 안에 실행 단위를 여러 개 구성하는 멀티코어, 혹은 Manycore 프로세서 개발에 적용하고 있다[2][3]. 이로 인해 하나의 프로세서 안에서 실행 단위라 불리는 코어가 2개, 4개, 8개, 12개 등으로 증가하고 시스템 측면에서는 2개, 4개, 8개 등의 프로세서가 장착되면서 운영체제 입장에서는 병렬 단위 수준이 제한적인 수에서 수십, 수백으로 증가하는 상황이다.
운영체제에서는 이미 병렬화에 대한 대응이 있지만 이러한 프로세서 수의 급격한 증가에서도 동기화 도구만으로 충분한지가 여전히 의문이다. Amdahl의 법칙은 동기화로 인해 일정구간이 직렬화되면, 이를 접근하는 실행 단위가 많아질수록 병렬화의 향상 정도는 점점 낮아짐을 의미한다. 이것은 Lock으로 보호해야 하는 동기화 구간이 많은 지금의 운영체제가 Manycore 환경에서는 실행 단위의 수에 비례한 성능을 유지 할 수 없음을 뜻한다. 다시 말해, 이제 운영체제는 제한된 멀티코어 시스템에서의 대응을 넘어서는, Manycore 시스템의 시대에 맞는 변화가 필요하다.
본고에서는 앞서 언급한 최근의 프로세서 동향에 대해 좀 더 알아 보고, 현재의 운영체제가 Manycore 시스템에서 갖는 성능과 한계에 대해서 알아본다. 그리고 이 한계를 극복하기 위해 진행되는 여러 연구를 알아보고 이러한 연구결과가 의미하는 운영체제 패러다임의 변화를 살펴보고자 한다. 마지막으로 이러한 패러다임의 변화에 대응하는 연구방향에 대해서도 간략히 소개하고 결론을 맺는다.
II. Manycore 시스템 동향
(그림 1)은 는 지난 35년간의 프로세서의 발전경향[4]을 나타낸 그림이다. 2008년을 기준으로 보면 회로의 집적도를 나타내는 트랜지스터의 수는 지속적으로 꾸준히 증가하고 있으며 이에 따라 동작속도와 단일 쓰레드 성능이 같은 경향으로 증가하고 있다. 하지만 2008년 이후에는 트랜지스터 집적도는 여전히 증가하지만 동작속도(Hz)의 지속적 상승이 어려워 단일 쓰레드 성능은 정체되어 있음을 알 수 있다. 반면에 코어의 수는 2008년을 기점으로 하여 크게 증가하기 시작하는 경향을 볼 수 있다. 이는 프로세서의 기술발전이 최근에는 코어 수를 증가시키는 데 있다고 볼 수 있다.
")
프로세서 시장에서 가장 큰 영향력을 갖는 Intel[2]의 로드맵을 보면 2014년 출시 예정인 서버 프로세서 ‘Broadwell-EP Xeon’에 18개의 코어를 탑재할 것이며, MIC 구조의 Xeon Phi에는 현재 60 코어를 72개 이상의 코어로 확장할 것으로 예상된다. Tilera[3] 역시 현재 TILE-Gx72 모델에 단일 프로세서 기준으로 72개 코어를 탑재하여 시장에 출시한 상태이며 향후 수백개 이상으로 코어 수를 증가시킬 계획이다.
구조적인 측면에서 Manycore를 지원하는 프로세서는 단지 코어의 증가만을 의미하지는 않는다. 코어의 수가 많아짐에 따라 기존의 멀티코어에서 제공되던 캐쉬 일관성 기능이 지원되기 힘들어지고 개별 코어가 갖는 캐쉬의 양도 감소 되고 있다. 코어 간의 데이터 교환의 방법은, 메모리 기반의 공유를 통한 데이터 통신보다는 IPC(Inter-Process communication)를 통한 데이터 통신이 비교 우위를 갖게 될 것이다.
이처럼 2~3년 사이에 Manycore 프로세서는 Multicore 프로세서에서 빠르게 발전하고 있으며, 앞으로도 하나의 시스템 안에 수천개의 코어를 가지는 시스템이 더 이상 새롭지 않을 것이다.
III. Manycore에서 운영체제 현황
Manycore 시스템에서 운영체제의 상태를 알아보고자 한다. 가장 범용적 운영체제인 리눅스에서 성능을 확인하고 이에 관련된 기술과 문제점을 구체적으로 알아보고자 한다.
1. Manycore 시스템에서 리눅스 성능
초기 리눅스는 단일 프로세서용으로 설계 되었으며 커널 2.0에 비로소 SMP(Symmetric multiprocessing) 기능을 갖추었다. 이 때는 커널에 오로지 하나의 쓰레드만 진입 가능한 구현이기 때문에 응용에서는 병렬처리를 지원해도 결국 운영체제에서는 직렬화될 수 밖에 없다. 이후 2.2버전이 되면서 Big Kernel Lock이라는 전역 Spin lock 구현이 적용되면서 다수의 프로세서가 동시에 커널을 실행할 수 있게 되었고 Lock의 범위는 세밀해지게 되었다. 하지만 Big Kernel Lock은 여전히 직렬화 구간이 크며 Lock의 요청순서 역전현상과 여러 커널 버그를 야기하였고 프로세서 수가 많아지면 성능이 많이 저하되었다. 이후, 커널은 2.6.39 버전이 되면서 Arnd Bergmann에 의해 마지막 Big Kernel Lock이 제거되고 비로소 Fine-grained lock이라는 평가를 받게 되어 성능 확장성을 가지게 되었다.
Fine-grained lock이 구현되었다고 평가 받고 있는 리눅스에서의 Lock 성능을 정확히 알아보기 위해 AIM7 벤치마크 도구[5]를 이용하여 성능을 확인해 보았다. (그림 2)는 Intel Xeon 프로세서(15 코어)를 장착한 IBM의 시스템(120 코어: 8 소켓 X 15 코어)에서 성능 테스트를 하였다. 가로축은 코어 수를 나타내며 실험은 2, 4, 8, 15, 30, 60, 90, 120 코어로 설정을 하며 실행하였고 세로축은 결과로써 분당 Job 처리량을 뜻한다.
")
(그림 2)를 보면 Job 처리량은 코어가 증가함에 따라 점차 증가하다가 90 코어 가량에서 최대치를 달성하고 120 코어에서는 오히려 성능이 떨어지고 있다. 그리고 단위 코어당 처리량을 보면 2~8 코어까지는 1.1만 가량을 유지하다 15부터 서서히 감소하고 90 코어쯤에는 5,000 이하로 감소하고 있다. 이 실험결과는 현재의 리눅스는 비록 Fine-grained lock이 구현되어 있다 하더라도 적은 수의 코어를 가진 시스템에서만 성능 확장성을 가지고 코어가 많아질수록 확장성은 더욱 떨어지며 수백개의 코어가 있는 시스템에서는 오히려 성능을 유지도 못함을 알 수 있다.
따라서, 현재의 리눅스는 Manycore 시스템에서 성능 확장성을 보장하고 있지 못하며, 프로세서의 발전속도를 따라가지 못한다고 볼 수 있다. 이러한 결과를 가져온 이유는 1) Lock의 구현 문제, 2) 프로세서의 캐쉬 일관성 기능의 성능 문제, 3) 코어의 캐쉬 효율 저하 문제 등이 주로 언급되고 있다[6].
2. 확장성 저해 요소들
가. Lock 구현
대부분의 운영체제는 Lock의 구현방법으로 Spin lock 알고리즘을 채택하고 있거나 이를 개선한 알고리즘인 Hybrid spin lock, Ticket-based spin lock 등을 채택하고 있다. Spin lock 계열의 Lock은 비교적 구현이 간단하고 수학적 검증이 되어 있으나 Lock에 대한 경쟁이 낮은 환경에서 효율이 좋은 알고리즘이다.
(그림 3)는 코어 수에 따른 Spin lock의 효율을 MCS lock[7][8]와 비교한 것이다. Spin lock은 코어 수가 4 이하에서는 매우 좋은 성능을 나타내지만 더 많은 수에서는 오히려 성능이 많이 떨어진다.
")
Spin lock의 문제점은 Lock 알고리즘 자체의 문제도 있으나 프로세서의 하드웨어 특성과 맞지 않는 부분도 있다. 최근의 대부분 프로세서는 코어 간에 캐쉬 일관성 기능을 지원하나 Spin lock의 구현에 필요한 Test-and-Set 명령어가 지속적으로 캐쉬 블록 무효화를 야기하여 추가적인 성능 하락을 가져 온다. 이러한 특성으로 인해 Manycore에서 Spin lock의 성능은 더욱더 하락하는 경향을 보인다.
나. 캐쉬 실패(miss)
시분할 스케줄링 방식은 응용의 수가 코어의 수보다 많다는 가정에서 효율적인 구현이다. 이 스케줄링은 응용의 응답시간을 향상 시키고 코어의 사용 효율을 좋게 하는 장점이 있지만 태스크 스케줄링 때마다 프로세서의 TLB가 재설정되는 문제점이 있다. 따라서 스케줄링 주기마다 응용은 캐쉬가 재설정될 때까지 캐쉬의 효과를 얻을 수가 없게 되어 성능 하락이 발생된다.
또한, 운영체제와 응용 간에 코어 캐쉬 경쟁문제도 있다. (그림 4)는 모노리틱 운영체제에서 코어의 캐쉬 크기에 따른 운영체제(OS)와 응용(User) 간의 경쟁현상을 보여주는 그래프[9]이다. OS/User interference라는 영역은 서로의 경쟁으로 인해 캐쉬가 실패(Miss)하는 것을 보여 준다. 캐쉬 크기가 증가함에 따라 경쟁으로 인한 실패 비율은 거의 20%~30%에 육박한다.
")
다. 캐쉬 일관성 기능의 성능
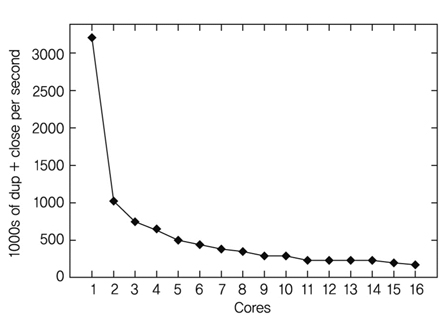
MIT의 Corey[7] 연구팀은 쓰레드를 생성시킨 후 각 쓰레드에서 파일을 생성하고, dup, close 함수만 실행하는 간단한 벤치마크를 실행하여 (그림 5)와 같은 결과를 얻었다.
")
(그림 5)의 결과를 보면, 쓰레드가 늘어남에 따라 dup & close 횟수가 오히려 줄어 들고 있다. 이는 리눅스의 파일 디스크립터 테이블을 쓰레드 간에 공유하고 있고, 이를 각각의 쓰레드가 변경함에 따라 데이터 일관성을 유지하기 위한 오버헤드 때문이다. 하드웨어의 캐쉬 동기화는 개발자에게 자동으로 쓰레드 간에 데이터 일관성을 제공하기도 하지만 필요치 않은 경우에도 동작하여 성능 저하를 초래한다.
라. 기타
위에서 언급한 주요 요인 외에도 성능 확장성을 저해하는 요소는 인터럽트 Masking, 커널/사용자 공간 사이에 빈번한 진입[10] 등을 지적하기도 한다. 이외에도 다양한 요소가 있을 수 있다.
IV. Manycore 운영체제 기술동향
본 장에서는 앞서 연구된 기존 운영체제에서의 문제점을 해결하기 위한 여러 운영체제의 동향에 대해서 알아 보고자 한다
1. 최근 기술동향
가. Corey
Corey[7] 연구팀은 기존 운영체제에서 공유가 필요없는 내부 데이터까지 코어 간 자동 공유하게 함으로써(이로 인해 프로세서 내의 코어 간에 캐쉬 일관성 작업이 빈번해 짐) 시스템의 성능이 저하되는 문제점에 주목하고 있다. 이는 기존 운영체제가 응용의 사용 패턴에 상관 없이 데이터가 코어 간에 공유되고 하드웨어 역시 응용의 패턴에 상관 없이 동기화하는 방식이기에 성능하락을 피할 수 없다는 것이다.
현재의 대부분 운영체제는 응용을 위해 기능을 추상화하고 추상화된 기능을 사용하기 위해 시스템 콜 인터페이스를 제공한다. 그리고 구현은 보편적인 상황에서 최상의 성능이 나오게끔 되어 있으며 응용은 단지 제공된 인터페이스를 통하여 그 기능을 사용할 뿐이다. 즉, OS계층과 응용계층은 서로의 구현 방식에 관여하지 않으며 필요한 기능은 서로가 제공하는 인터페이스를 통해서만 데이터를 전달하거나 제어하는 방식이다. Corey 연구팀은 이러한 계층 간의 독립성이 성능 하락을 가져오는 원인이 될 수 있다는 것에 주목하고 Corey를 제안하였다. Corey 운영체제는 오로지 하드웨어 추상화만 정의하고 OS 라이브러리를 통해 구현이 완성되는 Exokernel[11]의 설계 철학을 바탕으로 한다.
공유 개념을 구체적으로 보면, 기존의 운영체제가 공유를 기본으로 하고 공유의 제어는 응용의 사용패턴에 상관 없이 운영체제가 자동으로 해주는 방식이다. 하지만 Corey는 개별 응용이 운영체제 데이터의 공유 여부까지 결정할 수 있게 허용해 주는 방식을 취하고 있다. 즉, 특정 운영체제 데이터는 코어 간에 공유할지, 공유하지 않을지를 응용이 제어를 하는 것이다.
Corey는 이를 위해 Address range, Kernel core, Share라는 세 가지의 추상화를 제공한다. Address range는 가상 메모리 구조를 표현하는 데이터 구조로써 쓰레드 별로 개별 주소공간을 갖게도 할 수 있고 공유주소공간도 갖게 해 주는 것이다. Kernel core는 특정코드나 OS 서비스가 스케줄링을 받지 않고 지정된 코어를 독점적으로 쓰게 하는 기능이며, 마지막으로 Share는 Address range와 같은 데이터를 쓰레드 간에 공유/비공유를 제어하는 인터페이스이다. 응용은 이 추상화를 통해서 데이터의 공유를 조절할 수 있고 운영체제의 코드를 코어에 스케줄링 되는 방식도 제어하게 되어 Manycore 시스템에서 성능 확장성을 갖게 된다.
나. FOS
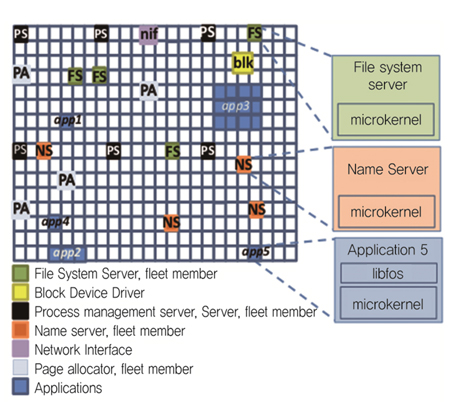
FOS(Factored Operating System)[9]는 Carbon Research Group(MIT)에서 개발되었으며, Manycore(수백~수천 코어) 시스템에서 공유 메커니즘을 삭제함으로써 성능 확장성을 향상시키는 구조이다. 기본적으로 마이크로 커널 구조를 채택하고, 스케줄링 정책은 시분할 스케줄링이 아닌 코어를 분할하여 사용하는 공간 분할 스케줄링 방식을 지원하는 것이 가장 큰 특징이다.
운영체제의 서비스를 제공하는 서버가 공간 분할 스케줄링 정책에 의해 코어에 할당되고 나면 해당 코어에 영구적으로 실행되기 때문에 운영체제의 데이터를 접근함에 있어 직렬화할 필요가 없어져 근본적으로 공유 개념이 없다. 이로 인해 기존 운영체제가 Manycore 시스템에서 갖는 Lock 경쟁에 의한 성능 저하 문제가 없어 코어 수에 따른 성능 확장성을 갖는다.
FOS의 기본 요소 (그림 6)과 동작은 현재 인터넷과 견주어 비교하면 이해하기 쉽다. 하나의 코어는 인터넷의 노드와 같고 운영체제의 기본 서비스를 제공하는 서버와 응용은 인터넷 서버와 클라이언트처럼 노드 여기저기에 존재한다. Name server라는 특수한 운영체제 서비스가 존재하며 이는 마치 DNS와 같다. 응용이 IPC를 통해서 운영체제 서비스를 이용할 때 Name server는 해당 서비스를 제공하는 서버가 어느 코어에서 존재하는지를 알려준다. 그리고 특정 운영체제 서버에 부하가 집중될 경우, 해당 서버를 여러 코어에 다수 생성하고 부하 분산을 해 준다.
")
운영체제의 서비스를 제공하는 서버를 모두 분리하고 개별 코어에서 실행하며 데이터의 공유를 없앰으로써 Lock 경쟁에 의한 성능 저하 문제를 해결하였지만 서버들 간에 공유 캐쉬 기능을 구현하기 힘들기 때문에 운영체제 서버 간에 빈번한 데이터 복사와 IPC가 예상되는 문제점이 있다.
다. Fused OS
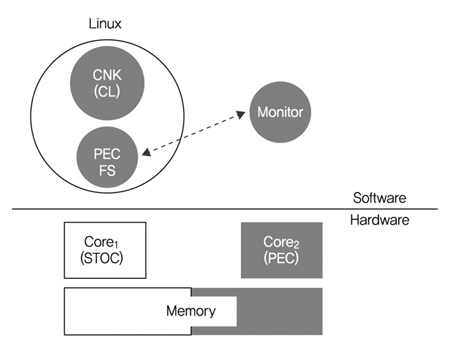
IBM 왓슨 연구소에서 모노리틱 구조의 운영체제와 마이크로 커널 구조의 운영체제의 장점을 혼합한 구조의 운영체제(Fused OS)를 연구[12][13]하였다. IBM Blue Gene/Q 시스템에서 HPC 응용을 성능 확장성이 있고 신뢰성 있게 수행시키는 것이 주목적이지만, 이질적인(heterogeneous) 코어로 구성된 Manycore 시스템의 운영체제 구조 연구가 시작점이었다. 여기서 이질적인 코어란 전력 효율적인 코어(PEC: Power Efficient Core)와 단일 쓰레드에 성능 최적화된 코어(STOC: Single Thread Optimized Core)로 구성된 프로세스 코어 칩을 의미한다. 따라서 Fused OS 설계개념은 응용과 운영체제를 다른 코어에서 수행되도록 하여 응용의 성능이 운영체제에 의해 간섭을 받지 않도록 하는 것이다.
(그림 7)과 같이 Fused OS의 기본 동작은 응용과 운영체제가 다른 코어에서 각각 수행되는 것이다. 즉 리눅스 운영체제는 일반적인 코어(STOC)에서 수행되고, 응용들은 가벼운 코어(PEC)에서 수행된다. PEC 코어에는 monitor라는 코드가 수행되며, 이 코드는 응용이 수행되면서 발생하는 시스템 호출이나 예외(exception) 정보를 저장하고 리눅스 운영체제에게 전달하는 역할을 한다. 반면에 리눅스 운영체제는 기존의 리눅스 코드에 PEC 코어의 메모리 등을 접근할 수 있는 기능을 추가하였다. 게다가 PEC 코어를 관리하는 CL(Compute Library)이 리눅스 응용으로 동작하며, 이 CL은 가벼운 커널 기능을 가지고 있게 설계되었다. 즉 리눅스 운영체제에서 만들어진 응용이 PEC 코어에서 수행되기 위해서, CL는 PEC 메모리에 응용 이미지를 구축하고 수행되도록 PEC 코어에 전달하게 된다. 따라서 Fused OS는 코어와 메모리 자원을 분할하여, HPC 응용의 성능을 보장하면서 리눅스 운영체제 기능도 제공하게 되었다.
")
HPC 벤치마킹 결과, Fused OS는 운영체제 기능을 하는 코어와 계산을 위한 코어를 분리시켰기 때문에, 성능 측면에서 계산을 위한 코어에서 실행되는 응용은 운영체제 기능을 하는 코어에서 실행하는 응용보다 우수하다는 것을 밝혔다. 하지만 응용에서 호출하는 시스템 호출은 원격의 운영체제 코어에서 처리되기 때문에 추가적인 호출시간이 필요하다.
라. Barrelfish(Multikernel OS)
Barrelfish[14]는 ETH Zürich대학에서 마이크로소프트사의 도움을 받아 개발된 Multikernel 운영체제이다. Manycore 시스템에서의 성능 확장성을 갖고, 리팩토링 없이 다른 하드웨어에 적용되면서 현재의 운영체제에 비교 가능한 성능을 제공하는 것이 목표이다.
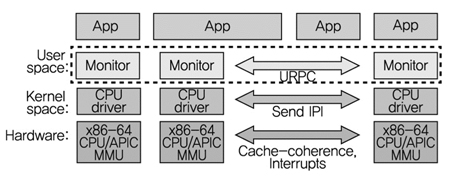
이를 위해 Barrelfish 운영체제는 수직적인 측면에서는 하드웨어에 밀접한 부분(CPU Driver)과 하드웨어 중립적인 부분(OS Node: (그림 8)에서 CPU Driver위에 구현된 OS 서비스 모듈)으로 나누고, 운영체제 기능은 주로 OS Node에서 구현한다. 그리고 수평적 측면에서는 다양한 하드웨어에 각각의 CPU Driver와 OS Node가 하나의 커널 역할을 하는 Multikernel 구조다. 그리고 이러한 커널은 메모리 공유 보다는 IPC를 통하여 통신을 하는 분산 구조이다.
")
이렇게 함으로써 Barrelfish는 이질적 코어를 모듈화하여 새로운 하드웨어에도 코드 재사용성을 높일 수 있으며 공유가 아닌 IPC로 모듈화된 코어가 동작함으로써 Manycore에 대한 성능 확장성을 가지게 된다. 메모리 공유의 부재로 인한 성능 하락은 Monitor라는 모듈을 통해서 공유가 필요한 데이터에 대해서 View라고 하는 복제를 갖게 하여 성능 하락을 보완하고 있다.
Barrelfish의 시스템 구조는 (그림 8)과 같이 명시적인 메시지를 통해 통신되는 여러 개 독립적인 OS 인스턴스를 정의하고 관리자 모드의 CPU 드라이버에 배치시킨다. 코어 간의 코디네이션은 사용자 모드의 ‘모니터’에서 실행된다. 분산시스템의 모니터와 관련된 CPU 드라이버는 기능을 캡슐화시킨다.
TBL Shoot down, 메시지 성능, 운영 워크로드, 입출력 워크로드 기반의 테스트 결과 Barrelfish는 메시지 기반의 통신이 메모리 공유 기반의 통신에 대한 대안으로 활용될 수 있음을 확인하였다.
마. Cerberus-OS 클러스터링
Cerberus[9]는 중국의 푸단(Fudan)대학에서 가상 머신 모니터(VMM: Virtual Machine Monitor) 기술을 이용하여 여러 운영체제를 통합한 시스템이다. 현재 운영체제가 Manycore에서는 성능 확장성이 떨어지지만 1) 적은 수의 코어에서는 성능의 확장성이 있다는 것과 2) 가상 머신 모니터 기술이 여러 운영체제를 통합할 수 있다는 것이 연구배경이다. (그림 9)처럼 기본적인 아이디어는 VMM 위에 여러 개의 운영체제를 클러스터링하고 운영체제 관점의 단일 시스템 이미지를 제공하며, 공유메모리 기반 POSIX 인터페이스 호환성을 제공하는 것이다.
")
VMM 수준에서 단일 운영체제 이미지를 제공하기 위해서 클러스터링된 운영체제 간의 상태정보를 복제하고 배포기법을 VMM에 추가하였다. 특히 운영체제 간 메모리 공유에 있어 페이지 부재(fault)처리를 효율적으로 하도록 하였고, 파일의 접근 경쟁도 줄이기 위해서 분산파일시스템을 적용하였다. 또한 사용자에게 단일 운영체제 이미지를 제공하기 위해서, 시스템 호출 가상화 층을 제공하였다. 이 시스템 호출 가상화 층을 이용하여 사용자의 응용은 여러 운영체제 중에 한 운영체제를 사용할 수 있게 된다.
프로토타입은 Xen 가상화 기술과 리눅스 2.6.18로 구현되었으며, 인텔 16 코어 시스템 및 AMD 48 코어 시스템에서 실험되었다. Xen VMM에서 1,800 소스코드 라인이 추가되었으며, 리눅스 커널은 변경되지 않았다. 그리고 시스템 호출 가상화 층을 위해 8,800 라인이 구현되었다. 맵리듀스, dbench, memcached 및 아파치 웹 서버로 성능 측정을 하였으며, 인텔 1 코어에서 1.74~4.95배, AMD 48 코어에서 1.37~11.62배 성능 향상이 있었다. 게다가, 성능 프로파일링 결과, VMM 기반 운영체제 클러스티링 기법이 기존 운영체제보다 자원에 대한 경쟁률을 줄이는 것으로 분석되었다.
2. ETRI의 전망 및 방향
지금의 Manycore 경향은 코어 수를 보다 증가시키고 코어 간 데이터 통신을 최적화하고 있다. 또한 캐쉬 동기화 정책도 변하고 있다. 아직은 진화와 검증을 되풀이 하는 단계이기에 어떤 운영체제가 뛰어나다고 할 수는 없다. 최근의 여러 연구에서 다양한 운영체제 구조가 제안되는 것이 이에 대한 방증이다.
앞으로의 연구방향은 두 방면으로 진행될 예정이다. 첫 번째는 기존 운영체제의 분석이다. 기존 운영체제에서 ‘코어가 매우 제한된 희귀한 자원’이라는 가정으로 설계된 부분을 찾는 것이 중요하다. 시분할 스케줄링이나 Lock을 이용한 공유 문제가 바로 이러한 연구의 한 결과물이라 할 수 있다.
두 번째는 앞서 분석된 문제점을 해결하는 것이다. 아직은 특정 운영체제의 구조가 우세하다고 밝혀지지 않았기 때문에 해결방안을 모노리틱 커널과 마이크로 커널에서 각각 적용 결과를 평가하고 서로 간의 비교 분석이 필요하다. 한 예로, 분석단계에서 밝혀진 공유의 오버헤드는 모노리틱에서는 Lock 알고리즘의 개선[16]을 통해서 실현될 수 있고, 마이크로 커널에서는 IPC를 통해서 이뤄질 수도 있다. 따라서, 하나의 해결 방안에 대해서 각각의 커널에 대한 반영 비용과 결과에 대한 교차 평가가 필요하다.
V. 결론
Manycore 시스템은 현재 단일 시스템 안에 수십개의 코어에서부터 수백개의 코어로 발전하고 있다. 이에 반해 이를 직접 다루는 운영체제는 아직까지 멀티코어 지원 수준에 머물러 있어 코어 수에 따른 성능 확장성에 문제를 보이고 있다. 이로 인해 응용은 하드웨어의 성능을 충분히 활용하지 못하고 있다.
본고에서는 이러한 문제를 해결하기 위한 여러 가지 운영체제를 살펴 보았다. 대표적으로 Fused 운영체제는 기존의 운영체제에서 대처하기 힘든 성능 하락 문제를 계산 전용 운영체제(CNK: Computing Node Kernel)를 내재화함으로써 개선하려고 하였고, 이에 반해 Corey 같은 운영체제는 완전히 새롭게 설계하는 접근방식을 취하여 대응하려고 했다. 서로 다른 접근을 하고 있지만 기존 운영체제에서 발견된 Manycore 시스템에서 코어에 대한 공유 경쟁 문제나 코어 간의 간섭 문제를 해결하고자 한다는 점에서 공통점을 갖는다.
현재는 Manycore를 하드웨어로 형상화하는 것도 초기 단계이다. 보다 최적화된 하드웨어 구성이 나올 수도 있고 이것은 역으로 운영체제에서 문제를 일으킬 수도 있다. 이는 현재 많은 연구에서 지적되는 공유나 통신 비용 외에 다른 문제가 발생할 수 있음을 의미한다. 따라서, 향후 심도 깊은 관찰과 시뮬레이션을 통해 문제점을 분석하는 것이 필요하고, 운영체제에 분석결과를 적용하고 검증하는 연구가 지속적으로 필요하다.
용어해설
모놀리틱 커널 모놀리틱 커널은 프로세스, 메모리, 파일시스템, 입출력 관리, 네트워크 등의 모든 커널 기능을 하나로 묶고 시스템 호출과 인터럽트 처리 기능을 제공하는 커널을 말함. 하드웨어나 운영체제에 종속적인 부분을 분리한 계층구조를 가지고 있어 어느 정도 이식성을 제공하지만 새로운 기능 추가시 원칙적으로 다시 컴파일되고 부팅되어야 함. 하지만 단일 이미지 형태이기 때문에 운영체제 기능을 사용함에 있어 속도가 빠름.
마이크로 커널 꼭 필요한 핵심적인 기능(주로 처리기, 메모리 관리, 프로세스 관리, IPC)만 남겨둔 최소한의 커널로 대부분의 주요 운영체제 기능인 파일시스템, 네트워크, 입출력 장치 관리 등은 일반적으로 사용자 프로세스(서버) 형태로 제공됨. 따라서, 주요 하드웨어 장치를 사용하고자 하면 해당 장치를 담당하는 서버 프로세서와 통신을 통해 작업을 수행함. 하드웨어 장치 관리를 일반 응용 수준에서 하기 때문에 해당 장치에 여러 서버를 둘 수도 있고 동적으로 추가, 수정, 삭제도 가능함. 하지만, 운영체제 기능을 사용함에 있어 통신이 빈번하기 때문에 성능이 느리다는 단점이 있음.
References
(그림 1)
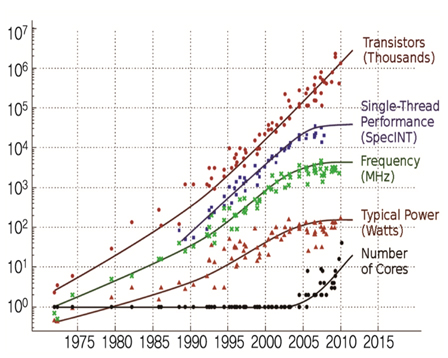
프로세서 발전추이<a href="#r001">[1]</a>
(그림 2)
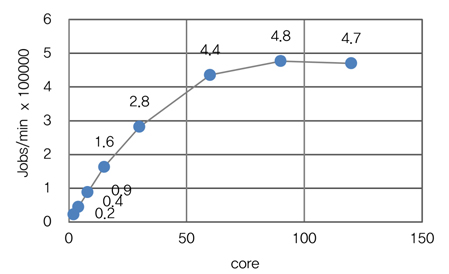
AIM7 벤치마크 결과
(그림 3)
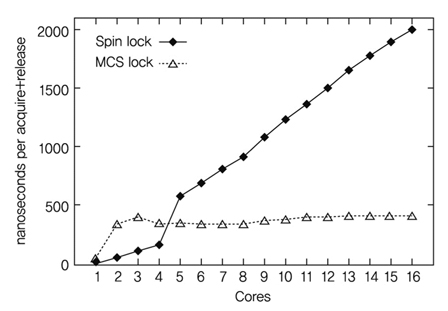
Spin lock과 MCS lock의 성능 비교<a href="#r007">[7]</a>
(그림 4)
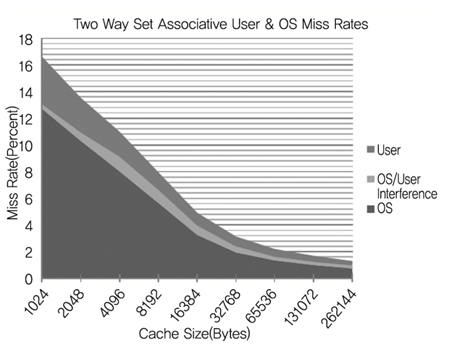
캐쉬 크기에 따른 캐쉬 성능<a href="#r009">[9]</a>
(그림 5)
dup & close 벤치마크 결과<a href="#r007">[7]</a>
(그림 6)
FOS 운영체제의 코어 구성도<a href="#r009">[9]</a>
(그림 7)
Fused OS의 기본 동작 개념<a href="#r012">[12]</a>
(그림 8)
Barrelfish 운영체제 구조도<a href="#r014">[14]</a>
(그림 9)
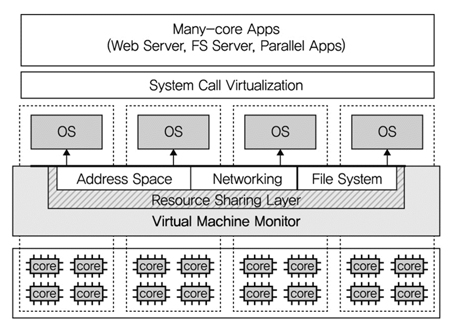
VMM 기반 운영체제 클러스터링 구조도<a href="#r015">[15]</a>