
이범철 (Lee B.C.) 네트워크컴퓨팅융합연구실 실장
I. 서론
Ceilometer는 빌링(billing, 과금)을 위한 텔레메터링 프로젝트이다. 텔레메터링이란 오픈스택 문서에 의하면 “빌링, 벤치마킹, 확장성, 통계적 목적으로 오픈스택 클라우드를 모니터하고 메터링함(Monitor and meters the OpenStack cloud for billing, benchmarking, scalability, and statistical purposes)”이다. 빌링을 위해 사용량을 측정하고(metering), 이를 바탕으로 요금 및 비용을 정산하고(rating), 고객에게 청구서를 발급하는 과금(billing) 행위가 필요한데 현재는 metering 단계이다. 또한 다양한 요구사항에 대해서 쉽게 확장 가능한 프레임워크를 개발하는 것도 큰 목표이다(Framework should be easily expandable to collect for other needs).
2012년 3월부터 시작된 Ceilometer 개발은 Canonical, DreamHost, RedHat, Dell, Intel, AT&T 등이 주 개발자이다. 비교적 최근에 시작된 프로젝트이고 다수 요구사항이 많은 다이내믹한 개발 성격을 가지고 있어서 정식 문서보다는 ‘개발자 문서’에 기록되어있다. 현재 프로젝트 리더는 Julien Danjou로 다수의 코어 멤버가 있다.
초창기에는 Nova(compute, volume, network이 분리되지 않았을 때), glance, swift 등 한정된 프로젝트에서 빌링만 위해 instance, cpu, ram, disk, image_upload 등의 모니터링 정보만 수집하였다. 그 후 Havana 버전에서 전체 프로젝트로 확장되었다. 이때 Heat와 통합하여 모니터링 정보가 오토스케일링과 연관되었다. 또한 event-triggering 방식에 의한 alarm, event가 도입되었다. Icehouse 버전에서 collector가 분리되고 sample 및 event API(Application Interface)가 생기고 ODL(OpenDayLight) 진영의 network 구현 및 베어메탈을 위한 Hardware 모니터링이 추가되었다. 그 기술적 개발 특징을 <표 1>에 담았다. 본고의 분석은 Ice-house(2014. 1.)를 기준으로 한다.

II. 전체 구조
1. 주요 설계 개념
중요한 설계 개념 두 가지는 빠르게 도입되는 오픈스택 컴포넌트 확장과, 사용자 요구에 맞는 고객지향적 측정값을 쉽게 수용할 수 있는 구조로 만드는 것으로 판단된다.
전체 구조는 기존의 서비스(Nova, Neutron, Cinder 등)는 물론이고, 장래 도입될 인큐베이터 서비스도 수용할 확장구조를 가져야 한다. 최근에 Heat, hardware, energy 프로젝트가 포함되었다. 데이터 측정을 통한 피드백 제어로 최적화를 이루려는 전자통신장치의 본질적인 구조이므로 더욱 발전할 것이다.
또한 고객 취향에 따른 측정값을 쉽게 수용하고자 Plugin 매커니즘과 pipeline을 도입했다. 사용자마다 모니터링 할 소스 위치, 시간구간, 통계치가 다르기 때문이다. 실제로 새로운 측정치(meter)를 소스상에 쉽게 심을 수 있는 구조를 지니고 있다.
2. 데이터 수집 방식
데이터를 수집하는 방식은 크게 4가지가 있다. Bus listener agent, Push agents, Polling agents, Push RESTful API 방식이다.
Bus listener agent 방식이란 (그림 1)과 같이 Notification Bus란 내부버스를 이용한 통신이다. 파이썬 언어의 Oslo 라이브러리를 사용한다. 버스의 메시지 큐를 관찰하다가 생성되는 이벤트를 수신(listen)하여 측정치(sample)로 변환한다. 가장 이상적인 방법으로 오픈스택의 다수의 컴포넌트들이 이 버스를 사용한다. 그러나 현재는 AMQP(Advanced Message Queuing Protocol)란 느슨한 연결 방식(Loosely Coupled)의 프로토콜을 사용하여 빠른 통보 메시지 전달에 한계가 있어서 비 AMQP 방식의 ZeroMQ 방식이 주목 받고 있다.
")
Push agent 방식은 (그림 2)와 같이 Notification bus 방식으로 모니터링 데이터를 추출할 수 없는 곳에 강제적으로 Push agent 모듈을 설치하는 방식이다. 현재는 compute 노드에서만 사용된다. Compute 노드에 compute 에이전트를 추가 설치하여, 하이퍼바이저로 가상머신을 폴링하여 얻은 모니터링 정보를 전달한다.
")
Polling agents 방식은 (그림 3)과 같은 것으로 신규 컴포넌트여서 Notification Bus가 구현되지 않거나, 외부 시스템으로부터 접근이 있어서 RESTful 방식을 사용한다. RESTful 방식이란 일반 웹에서 사용하는 방식으로서 http, url, server-client, html의 특징을 지니고 있다. 내부 컴포넌트끼리 전달을 위해서 오버헤드가 많고, 확장성에 문제가 있어서 기술발달에 의해 Bus listener agent 방식으로 바뀔 것이다.
")
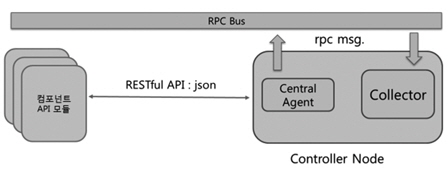
Push RESTful API 방식은 (그림 4)와 같이 외부 시스템(사용자, 운영자 등)이 일방적으로 sample를 넣어주는(push) 방식이다. Controller version2에 추가되었는데 POST 방식을 사용하여 JSON(JavaScript Object Notation) 데이터를 전달한다.
")
3. 코어 구조
전체 코어 구조는 (그림 5)와 같이 다수 개의 기본 컴포넌트가 있다. Collector, Central agent, Compute agent, Data store, API server이다. 그 외 메시지 버스와 pipeline, 알람을 기술하였다.
")
Collector는 중앙관리서버에 위치하는 핵심 컴포넌트이다. 메시지 버스를 모니터링하여 sample 데이터를 Data Store에 저장시키는 역할을 한다. 초기에는 이 모니터링 및 pipeline 기능이 Collector에 있었으나 후에는 분리되었다.
Central agent는 중앙관리서버에서 위치하여 Polling의 주체로 사용한다. 주로 Nova(가상머신, 인스턴트 등)에 관련이 없는 컴포넌트들인 Object storage(Swift), Image(Glance) 등에 사용된다. Network(Neutron)와 Compute(Nova)에도 사용되나 meter 개수가 적다. 얻은 데이터를 RPC Bus를 통해 Collector에 전달한다.
Compute agent는 추가 설치 모듈이다. 전술한 (그림 2)와 같이 push agent를 유일하게 사용한다. 빌링을 위해서는 VM 단위의 메터링 측정(cpu 개수, 누적 cpu 시간, cpu 이용률, 가상 NIC의 송수신 패킷량과 전송률, 디스크 및 메모리 통계량 등)이 매우 중요한데 Notification bus가 아직은 지원되지 않아 Push agent 방식을 사용한다. 현재 지원되는 하이퍼바이저는 livirt, hyperv, vmware 등이 있는데 livirt가 디폴트이다.
기술적 세부 설명을 하자면, 그 agent는 ceilometer/compute/manager.py에 구현되어 있다. 이 agent는 폴링 및 notification 관련 플러그인 모두를 자동 로딩시킨다. 이 agent manager에는 get_hypervisor_inspector 메써드가 중요한 역할을 하는데 ceilometer.compute.virt의 namespace에 따라 HyperVInspector, LibvirtInspector, VsphereInspector 클래스가 동작된다.
Push agent에 관한 설명은 아니나 compute node는 매우 중요하고 복잡해서 notification 방식과 Polling 방식도 덧붙이고자 한다.
Notification은 /ceilometer/compute/notifications/{cpu.py, instance.py}에 있다. 원형 클래스는 /ceilo-meter/plugin.py에 있는데 내부 버스의 payload로써 전달하므로 polling보다 복잡하다. 메써드로써 process_notification을 사용하는데 event_types과 이벤트 메시지를 받아서 sample을 만든다.
Polling에 있어서는 ceilometer.poll.compute란 namespace에 정의되어있다. 개별적인 pollster들은 ceilometer/compute/pollsters/{cpu.py, disk.py, instance.py, memory.py, net.py}에 있는데, agent가 get_samples 메써드로써 주기적으로 호출하여 샘플값을 얻는다.
Data Store는 비정형 데이터를 다루는 MongoDB를 디폴트로 사용한다. 그 외에도 PostgreSQL, HBase, IBM DB2 등이 개발 및 테스트 중이다. 다양한 DB에 대해 많은 테스트가 일어나는 불안정기여서 오랫동안 개발해왔던 MongoDB를 디폴트로 권한다. 현재는 가장 기본적인 RESTful 방식으로만 액세스된다. 한 개 혹은 다수의 Collector 인스턴트로부터 동시적 저장이 가능하다. 최근에는 dispatcher 모듈을 넣어서 DB뿐 아니라 파일 저장도 된다.
API server는 웹 서버 형태로 중앙관리서버에 위치하면서, 사용자 혹은 빌링 시스템 등의 API 요구에 대해서 RESTful 방식으로 동작한다. 경량화된 파이썬 웹 프레임워크인 Pecan 서버를 사용한다. Pecan 서버는 REST-style의 컨트롤러를 다 지원하고, 파이썬 기반의 설정이 가능하고, 보안 및 템플레이트 언어 및 JSON을 확장적 제공이 가능하다. 현재 version2 컨트롤러를 사용하는데 Pecon의 RestController를 상속받아서 resource, meter, sample, alarm, event 등의 컨트롤러를 구현하고 있다.
Notification Bus의 구현은 파이썬의 Oslo 버스를 사용한다. Oslo 버스는 3 가지 메시징 시스템을 사용하는데 현재 AMQP 프로토콜을 사용하는 RabbitMQ(현재 오픈스택에서 디폴트임)와 Qpid와 비AMQP 프로토콜인 ZeroMQ가 있다. AMQP 프로토콜이 이종 시스템끼리의 느슨하게 연결(Loosely Coupled)을 위한 것이므로 Notification Bus로 이용하기엔 부족함이 있고, 무겁다는 단점이 나타나서 ZeroMQ로 전환할 예정이다. 라이브러리는 RPC와 Notify를 사용한다. RPC와 Notify 메커니즘 구조가 달라서 후에는 분리될 전망이지만 현재는 Notify도 RPC driver를 사용한다. 대신 써드파티에 비동기적으로 event를 발생시키는 경우로만 제한되어 있다. Multiple backend driver를 지원하고 있다.
Pipeline은 (그림 6)과 같이 표현할 수 있다. 샘플이 나오는 시작 지점인 source와 샘플이 변형되어 도착되는 sink를 연결하는 배관구조를 말한다. 이 pipeline 구조로 인해 사용자의 취향에 따른 meter를 추가할 수 있다. 시작 지점이란 pollster 혹은 notification handler를 말하고, sink란 샘플값의 최종 배달처인 publication 도착지점과 더불어, 데이터가 요구조건에 의해 프로세싱되어 변형되는 transformer를 포함한다. 현재는 transformer를 통해 비율 변화(rate of change), 단위 변환(performing unit conversion), 집계(aggregating)의 3가지 종류로서 체인(chain of handlers)을 만들 수 있다. Publisher로 다수에게 배달될 수 있다.
")
설정 방법은 ceilometer.conf란 파일을 사용한다. 이 파일에서 pipeline 구조가 있는 pipeline.yaml 파일을 정의한다. yaml 파일 일부는 (그림 7)과 같다[4].
")
Havana부터 도입된 alarm도 데몬으로 동작되는데 (그림 8)과 같이 alarm-evaluator, alarm-notifier로 구성된다. Evaluator가 이들 데이터를 public API를 통해서 액세스하여 알람 큐에 넣어둔다. 이때 조건에 맞는 이벤트가 발생할 경우 Notifier가 외부시스템(log, rest, test)으로 알리는 구조이다. 현재 상태는 ok, alarm, insufficient 등의 3 가지 상태가 있다. CLI(Command Line Interface) 명령에 의해 강제로 상태를 지정할 수 있다. 단위 알람끼리 ‘and’ 및 ‘or’의 조합(combination)된 조건을 만들 수 있다.
")
III. 기본 개념
Ceilometer의 설계는 Sample 중심으로 설계되었다. 용어 정의가 매우 중요한데 Meter, Sample, Statistics, Alarm, Event 순서로 이해할 필요가 있다[5]. CLI 명령어를 통해서 체험하고, 소스의 ceilometer/storage/models.py의 클래스를 보면 요체가 파악된다. <표 2>에 데이터 구조를 표시했다.

1. Meter
Meter는 옛 문서에서 count로 표기되기도 한다. 오픈스택의 특정 리소스들의 이용 혹은 존재 여부 혹은 CPU 이용률과 같은 성능을 측정하는 속성이다. 모든 meter는 string값의 이름을 가지고 있는데 cumulative, delta, gauge 등의 3 가지 종류가 있다. Cumulative는 적분과 같이 누적치이며, delta는 미분과 같이 순간치이며, gauge는 파라미터와 같이 단독값(standalone value)이다.
2. Sample
Sample은 특정한 meter과 관련해서 단순한 개별 데이터 포인트이다. 거의 대부분 meter와 같은 구조인데 timestamp와 volume이라고 불리는 측정값이 더해져 있다. CLI 명령을 통해서 보면 해당 시간의 값을 알 수 있다.
3. Statistics
Statistics는 sample의 단일 데이터 포인트와는 달리 구간 시간 내의 집계된 데이터 포인트들의 통계치이다. 따라서 통계치는 현재 5개의 집계 함수가 있다. Count, max, min, avg, sum이다. 이름 그대로 샘플 개수, volume 최대값, volume 최소값, volume 평균값, volume 합계를 말한다.
4. Event
Event는 sample과 같이 리소스로부터 나오는 가공되지 않은 사건(raw event)을 말한다. 여기에 부수적으로 Traits를 가지고 있다. Metric과의 관계는 한 개 혹은 다수의 Event로부터 meter를 추출해 낸다는 것이다. Sample보다는 약간 규모가 큰 사건인데, Image를 다운받거나, 가상머신을 만들거나 Image에 대해서 CRUD(Create, Read, Update, Delete) REST(Representation State Transfer) 명령어를 수행하는 등의 사건이 있다. Trait는 Event에 대해서 키/값의 쌍을 가지며, 여러 데이터 타입이 될 수 있다.
IV. Meter(측정 종류)
현재 이 meter값은 정식 문서가 아닌 개발자 문서에 있는데 Compute(nova), Network(neutron), Network(SDN controller), Energy(kwapi), Orchestration(heat), Volume(cinder), Object Storage(swift), Image(glance), Hardware meter가 정의되어 있다.
빌링에 있어서 중요한 metric은 최초 문서에 21개에 잘 나타나 있다[6]. 초기의 meter들은 현재의 수많은 meter들 속에서 중요도를 판단할 수 있다. Nova의 경우에는 compute, volume 및 network이 분화되지 않은 구조에서 meter인데 VM instance에 대해선 instance, cpu, ram, disk, io rate, 보유 혹은 사용된 volume 용량, 내외 네트워크로 출입되는 데이터량, 공인 IP 등에 대한 것으로 12개가 있다. 그 외 swift 관련된 것이 8개, glance 관련된 것이 1개가 있다.
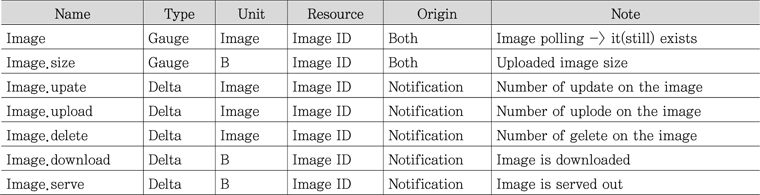
Meter 형식을 보기 위해 <표 3>의 glance를 예시하였다[7]. Name, type, unit, resource, origin, note로 이루어졌는데 name은 단순한 명칭이 아니고 setup.cfg 에 정의된 namespace인데 해당 클래스의 위치를 나타낸다. Type은 전술한 바와 같이 gauge, delta, cumulative 3 가지 종류가 있다. Origin은 notification 혹은 polling 방식을 표현한다.

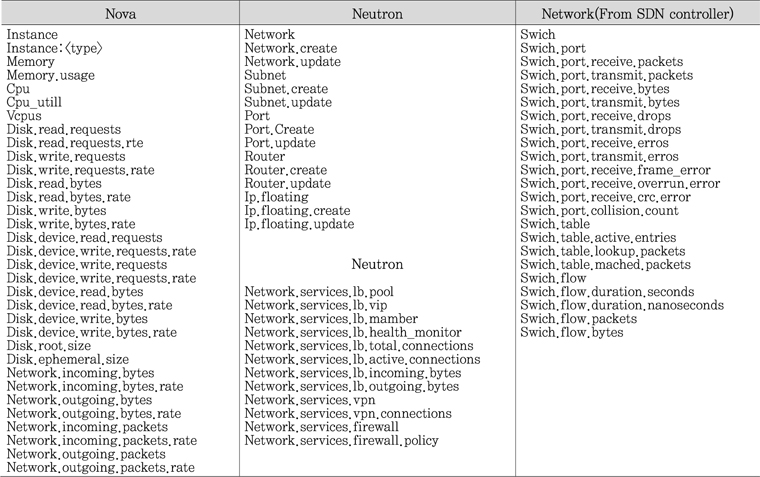
<표 4>에 가장 변화가 많은 Nova와 Neutron에 대한 meter를 정리해보았다.

Network metric은 기본적으로 network, subnet, port, router, floatingIP, bandwidth가 있어서 creation, update되는 상황을 파악할 수 있다. SDN(Software Defined Network) Controller와 관련해 좀 더 세밀한 네트워크 상황을 모니터링 하기 위해 flow, port, table, switch, driver류의 meter를 살펴보아야 하는데 아직 소스 분석상으로 보면 초기 정의단계이다.
그나마 SDN 후발주자인 ODL이 가장 앞섰다. ODL 진영의 driver만 구체적으로 구현되어있다. 타 진영은 아직은 추상 클래스만 정의되어 있다. 드라이버 설정은 pipeline.yaml 파일을 사용된다. 용법은 ‘opendaylight://127.0.0.1: 8080/ controller/nb/v2?xxxxxx’ 식으로 url을 사용하고 query 파트에 scheme(http), auth, user, password, container, name값을 넣게 되어있다. packet, byte, drop, error, collision count를 측정하는 함수가 소스상 존재하나 구현 정도는 알려지지 않았다.
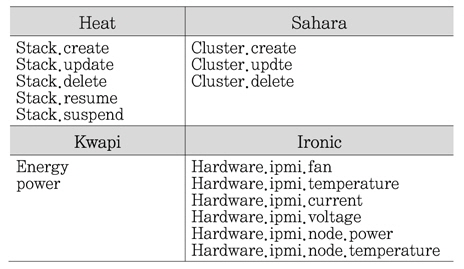
그 외 Heat(orchestration), Sahara(data processing), Kwapi(energy), Ironic(hardware IPMI Sensor Data) 등이 새롭게 추가되었다.
Heat는 오케스트레이션을 위한 것인데 자원 이용률을 측정해서 오토스케일링할 수 있다. Sahara는 과거 Savanna 이름을 개명한 것인데 Hadoop 혹은 Spark 같은 빅데이터 분석을 다룬다. Kwapi는 효율적인 에너지 사용을 위한 구조를 다루는 프로젝트이다. Ironic은 베어메탈 프로비저닝을 다룬다. 전자통신장치의 경우 최적화를 위해서는 데이터 측정을 통한 피드백 제어가 필수적이므로 ceilometer와의 연관성을 피해갈 수 없을 것으로 판단된다(<표 5> 참조).

V. MongoDB
현대 정보시스템의 정보가 눈에 띄지 않는 DB에 있듯이, ceilometer의 정보들이 디폴트로 셋팅된 MongoDB에 있다. 기존의 익숙한 관계형 RDBMS(Relational Database Management System)와는 달리 빅데이터 같은 비정형 데이터를 처리하기에 좋은 구조를 가지고 있다. 엄격한 스키마 정의를 하는 RDBMS와는 달리 MongoDB는 JSON 형태를 가진, 풍부하고 계층적인 구조의 데이터 표현이 가능한 (그림 9)과 같은 document 기반의 DB이다.
")
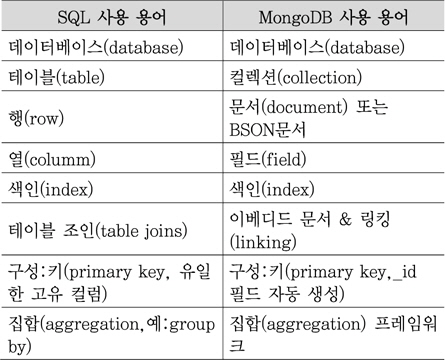
JSON 자체가 간단하고 직관적이고 인간 친화적이어서 직관적이다. 물론 스키마 역할을 하는 필드가 있어서 애플리케이션에 의해 첨삭, 수정이 가능하다. 데이터 타입에 자유롭지 못한 RDBMS는 정형적인 틀로 인해 많은 테이블이 필요하고, Join 연산자가 정보를 추출하므로 수평 확장이 힘들다. 물론 정형 데이터에 대해서는 RDBMS는 간단하고 신뢰할 만하고 고성능 서버로 업그레이드하면 확장이 쉽다. 그러나 수평 확장이 힘든 약점이 있다. 이에 비해 MongoDB는 중복성과 자동 장애 조치를 위해 다수 서버에 분산이 가능해 가용성 측면에서 우수하다. 또 복제와 샤딩이 쉽다[8].
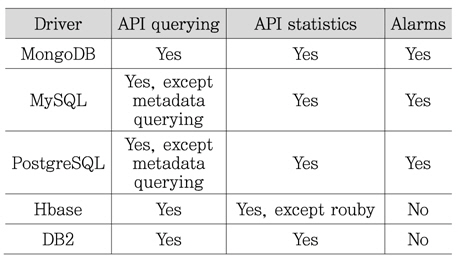
Ceilometer에서 MongoDB 이외에 <표 6>과 같이 SQL Databse, HBase Database 등 다수가 있다. 그러나 DB마다 구현 정도와 테스팅 완성도가 달라서 MongoDB를 사용할 것을 권고하고 있다.

안정화될 때까지는 DB 인터페이스 방법 및 드라이버가 변경될 것이므로 일차적으로 구현 가능한 REST API로 구현되어있다. REST 외의 빠른 접속을 위해서는 코드를 수정해야 한다. SQL 같은 RDBMS와 비교하여 <표 7>에 나타내었다[10].

VI. 인터페이스
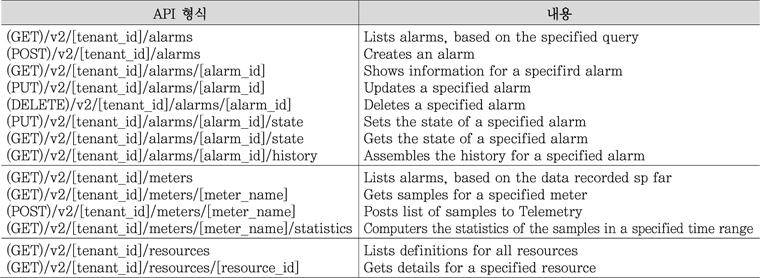
CLI 명령어로는 <표 8>의 25개로 alarm, event, meter, query, resource, sample, statistics, trait 등으로 분류된다[11].

<표 9>의 API 명령어로써도 접근할 수 있는데 아직은 CLI 명령어의 일부분으로 한정된다. CLI에서 보이는 query, event, trait 관련 API는 아직 없다. RESTful 방식의 CRUD 메써드를 사용한다. 데이터 형식은 XML(eXtensible Markup Language) 혹은 JSON을 사용한다[12].

VII. 결론
소스 분석을 통해서 많은 이슈들이 도출되었다. 첫째, 개발 역사로 보면 빌링 목적에서 출발해서 heat와 연관지어 VM의 오토스케일링에 현재 포커스를 맞추고 있다는 판단이다. 다양한 컴포넌트의 자원 최적 사용을 위해서 더욱 영역이 넓어질 것이다. 둘쩨, 알람 등의 트리거 기능 추가, 다양한 DB 적용, pipeline 구조 등 빠른 구조적 변화를 읽을 수 있다. 비록 상용 SW에 비해 부족하다는 평을 받지만 고객 수요에 맞춘 개방 구조를 이루려는 오픈스택의 대세를 무시할 수 없다. 셋째, 오픈스택 구조 자체가 각 컴포넌트들의 AMQP 같은 메시지 큐 방식을 사용하여 느슨하게 연결되어 있고, 서로의 통신은 API를 이용하는 방식을 사용하므로 컴포넌트끼리의 이벤트 전달이 빠르지 못한 면이 본질적이 면이 있다. Notification bus를 통해 통합하려고 하나 그 하부 기반인 AMQP 방식이 구조적 한계를 보인다. 쌍방 간 메시지 전달(notification bus)과 이벤트가 발생할 때 통보(notify)하는 구조는 본질적으로 달라서 전달 메커니즘이 AMQP 일원화에서 다변화될 것이다. 넷째, 성장하고 있는 오픈스택은 많은 새로운 인큐베이터 프로젝트를 도입시킬 것이다. 개별 프로젝트마다 자체 통신구조와 성격이 다르다. 그래서인지 데이터 수집방식도 상당히 여러 가지이다. 그 중 VM을 다루는 nova 데이터 수집구조가 제일 복잡하다. 개별 하드웨어들의 베어메탈을 위해 SNMP, IMPI를 도입하는 것도 특별하다. Swift도 안정된 독립된 기술인데 다수 엔티티에 대한 분산구조를 이루므로 미들웨어로 전달하는 특징을 지닌다. 다섯째, DB를 디폴트로 MongoDB를 사용한다는 것도 시사하는 바가 크다고 본다. 데이터를 모델링하는 방식이 JSON 형태의 document 형식이어서 비정형 데이터를 다룰 수 있다. 이것은 빅데이터 서비스를 다루는데 유리하지 않을까 판단된다. 여섯째, IaaS(Infrastructure as a Service) 서비스를 지향하는 오픈스택이므로 VM 자체가 아닌 VM에 설치된 SW 모니터링은 아직 없다. VM이 아닌 Host 서버에 대한 모니터링도 약하다. 이런면에서 오픈스택이 상용성이 부족하다고 쉽게 판단할 수 있다. 일곱째, 사실 Ceilometer는 모니터링할 수 있는 엔진이 들어있다기 보다 프레임워크를 제공하는 면이 강하다. 독립 컴포넌트들의 조합으로 이루어진 오픈스택의 본질적 구조로 인한 면도 있으므로 면밀히 분석함이 중요하다. 여덟째, 자체 모니터링만을 위한 것에서 외부 시스템의 연결을 위해 개방성에 포커스를 맞추고 있으나 아직은 불편하다. Pipeline의 publisher를 통해 샘플값을 file, udp에 보낼 수 있으나 초기단계이다. DB이전에 dispatcher를 두어 DB외에 file로도 보낼 수 있으나 역시 내부 로컬에만 사용할 수 있어 결국 API로만 통신해야 된다는 구조적 한계를 지닌다.
용어해설
OpenStack 오픈스택은 아파치 라이선스를 가진 대규모로 확장가능한(massively scalable) IaaS서비스를 제공하는 클라우드 OS임. 클라우드 OS란 computing, storage, network 자원이 연결되어 정보를 분석하고 처리하여 저장하고 관리하는 컴퓨팅 시스템으로 과거 컴퓨터의 OS가 CPU, Disk, Bus 자원을 관리하는 것에서 확장한 의미임. Icehouse 버전에는 10개의 프로젝트가 있는데 10개의 코드명은 Nova, Cinder, Swift, Neutron, Horizon, Keystone, Glance, Ceilometer, Heat, Trove임.
약어 정리
AMQP
Advanced Message Queuing Protocol
API
Application Interface
CLI
Command Line Interface
CRUD
Create, Read, Update, Delete
IaaS
Infrastructure as a Service
JSON
JavaScript Object Notation
ODL
OpenDayLight
REST
Representation State Transfer
RDBMS
Relational Database Management System
SDN
Software Defined Network
XML
eXtensible Markup Language
References
<표 1>
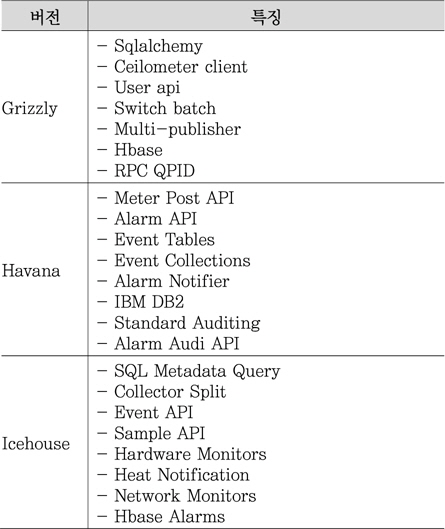
오픈스택 버전별 Ceilometer 특징<a href="#r001">[1]</a>
(그림 1)
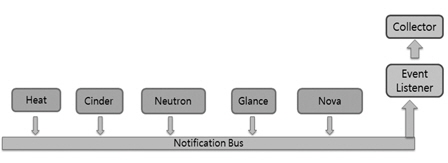
Bus listener agent 방식
(그림 2)
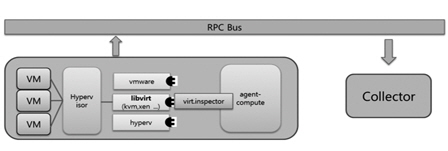
Push agent 방식
(그림 3)
Polling agent 방식
(그림 4)
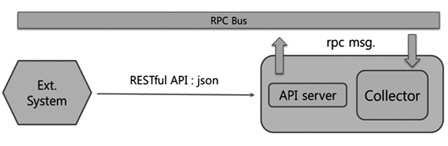
Push RESTful API 방식
(그림 5)
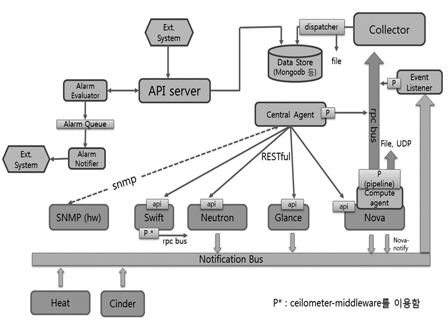
Ceilometer 전체 구조<a href="#r002">[2]</a>
(그림 6)

Pipeline 구조<a href="#r003">[3]</a>
(그림 7)

pipeline 설정 파일
(그림 8)
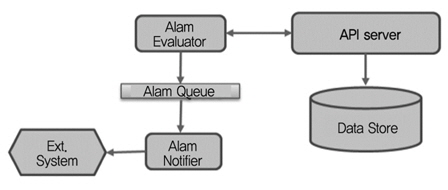
알람 구조<a href="#r003">[3]</a>
<표 2>
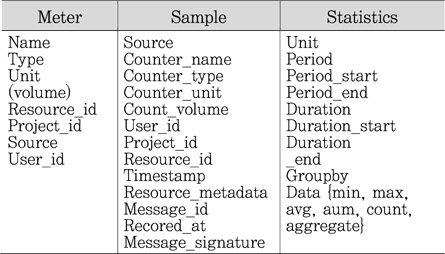
Meter, Sample Statistics 데이터 구조
<표 3>
Meter의 형식 표현
<표 4>
Nova와 Neutron 관련 meter
<표 5>
heat, sahara, kwapi, ironic의 meter
(그림 9)

MongoDB 의 Document 형식
<표 6>
다양한 DB의 특징<a href="#r009">[9]</a>
<표 7>
MySQL과 MongoDB의 용어 비교
<표 8>

CLI 명령어
<표 9>
API 명령어