
이범철 (Lee B.C.) 네트워크컴퓨팅융합연구실 실장
Ⅰ. 서론
2000년대 후반, 네트워크 장비의 인터페이스 처리속도가 10Gbps를 넘어가면서, 네트워크 장비의 인터페이스에 연결되는 서버 네트워크 인터페이스 카드 속도 역시 10Gbps 장비로 급속하게 교체되기 시작하였다. 그러나, 기존 서버의 네트워크 패킷처리 소프트웨어 구조 한계로 인해, 네트워크 인터페이스 카드의 속도 증가에 상응하는 서버의 네트워크 패킷처리 속도에 제약이 있었고, 이를 해결하기 위한 새로운 기술에 대한 요구가 꾸준히 제기되어 왔다.
기존 서버의 네트워크 패킷처리 소프트웨어는 응용 프로그램과 응용 프로그램에서 사용되는 네트워크 패킷의 처리 루틴을 서로 다른 공간에서 분리하여 처리하는 구조로 되어 있었다. 우선, 패킷을 송신할 때, 사용자 공간의 응용 프로그램은 네트워크 패킷을 송신하기 위한 소켓을 생성하고, 해당 소켓을 통해 네트워크 패킷을 송신한다. 소켓을 통해 송수신된 패킷은, OS의 루트 공간(커널)에서 프로토콜 처리(TCP/UDP/IP)를 종료하고 난 후, 네트워크 인터페이스 카드(이하, NIC)로 패킷을 전달하여 전송하게 한다. 패킷을 수신할 때, 사용자 공간의 응용 프로그램은 네트워크 패킷을 수신하기 위한 소켓을 생성하고, 패킷 수신을 기다린다. NIC에 수신된 모든 네트워크 패킷에 대해 OS의 루트 공간에서 인터럽트 처리와 프로토콜 처리(TCP/UDP/IP)를 종료하고 난 후, 사용자 공간의 응용 프로그램으로 소켓을 통하여 전달한다. 이렇게 네트워크 패킷처리 구조를 분리함으로써, 사용자 공간의 응용 프로그램에서 네트워크 패킷 프로토콜 처리에 대한 부담을 제거하여 개발자들이 자유롭게 응용 프로그램 개발에 집중할 수 있게 되었다[1].
이러한 서버의 네트워크 패킷처리 구조는 1980년대 이후 네트워크 인터페이스 카드의 속도가 10Mbps에서 100Mbps로, 그리고 1Gbps로 증가하는 상황에서도 잘 동작하였다. 2000년대 초반에는 커널에서 TCP 처리속도를 증가시키기 위해 TCP checksum과 segment 처리를 네트워크 인터페이스 카드에서 처리하도록 off-loading 하는 기술이 도입되었다[2]. 그러나, 네트워크 인터페이스 카드의 속도가 10Gbps를 넘어가게 되자 전혀 다른 상황이 되었다. 이러한 기존 서버의 소프트웨어 처리 구조로는 네트워크 인터페이스 카드를 통해 전달되는 10Gbps 패킷(64바이트 길이의 패킷으로 초당 14.88M 패킷을 송/수신)을 처리할 수 없는 상황이 된 것이다.
이에 따라, OpenOnLoad[3][4], Netmap[5]-[7], PF_ RING[8], DPDK[9]-[13], ODP(Open Data Plane)[14][15] 등등의 다양한 새로운 기술이 기존 서버의 고속 네트워크 패킷처리 문제를 해결하기 위한 데이터 플레인 가속화(DPA: Data Plane Acceleration) 기술로 제안되었다. OpenOnLoad기술의 경우, 네트워크 패킷을 OS 커널 영역을 통과하여 사용자 공간에서 직접 처리하게 함으로써 성능 향상이 가능함을 처음으로 보여주었다. OpenOnLoad기술은 네트워크 인터페이스 카드에서 응용 네트워크 패킷 헤더에 포함되어 있는 플로우 정보를 기반으로 사용자 공간의 응용에 직접 패킷을 전달하는 인터페이스를 제공한다[3]. Solarflare Communication에서는 OpenOnLoad기술을 기반으로 서버에서 네트워크 패킷에 대한 10Gbps 처리가 가능한 네트워크 인터페이스 카드를 출시하였다[4]. EU의 CHANGE 프로젝트[5] 연구에 포함된 Netmap기술은 이탈리아 Pisa 대학의 Luigi Rizzo 교수에 의해 연구가 진행된 기술로써, 주요 기술로는 패킷 자원 사전할당 기술, 다중 패킷처리 기술, 커널과 사용자 공간 사이에서 패킷에 대한 메타 데이터 및 메모리 버퍼 공유 기술 등이 있다. Rizzo 교수는 Netmap기술을 사용하여 서버에서 네트워크 패킷에 대한 10Gbps 처리가 가능함을 보여주었다[6][7]. PF_RING기술은 고속 네트워크 패킷 캡처, 필터링 및 분석 기술로써, 사용자 공간에서 네트워크 인터페이스 카드를 직접 액세스 하는 사용자 공간 DNA(Direct NIC Access)기술을 통하여 네트워크 패킷에 대한 10Gbps 처리가 가능함을 보여주었다[8][16].
본고에서는 데이터 플레인 가속화 기술로써 최근 공개 소프트웨어로 발표된 인텔의 DPDK기술과 Linaro의 ODP기술을 중심으로 고속 네트워크 패킷처리를 위한 데이터 플레인 가속화 기술동향을 소개한다.
Ⅱ. 인텔 DPDK기술
인텔은 2011년 인텔 NIC 카드에 적용되는 DPA기술인 DPDK(Data Plane Development Kit)기술을 오픈소스(www.dpdk.org)로 공개하였다.
1. 인텔 DPDK기술의 개요
인텔 DPDK기술은 인텔에서 공개 소프트웨어로 발표한 사용자 공간의 고속 네트워크 패킷처리 기술이다. 인텔 DPDK기술은 (그림 1)과 같이 사용자 응용 프로그램이 사용자 공간의 인텔 DPDK 라이브러리 API와 EAL(Environment Abstraction Layer)을 사용하여 리눅스 커널을 통과하여 직접 네트워크 인터페이스 카드를 액세스 할 수 있는 통로를 제공한다. 또한, 인텔 DPDK기술은 리눅스 사용자 공간의 데이터 플레인 API뿐만 아니라, 최적화된 NIC 드라이버를 제공한다.
")
인텔 DPDK기술은 실행 환경으로써, 멀티 프로세서 환경에서 프로세서 수가 증가할수록 데이터 플레인 성능 역시 비례해서 증가할 수 있는 모델인 Run-to-completion 모델을 지원한다. 인텔 DPDK기술은 단순한 API 인터페이스를 제공하며, 리눅스 개발환경은 표준 툴 체인을 사용하여 응용 프로그램을 컴파일한다.
2. 인텔 DPDK기술의 주요 기술
인텔 DPDK기술의 주요 기술은 다음과 같다.
-
메모리 관리자(Memory Manager)
인텔 DPDK기술의 메모리 관리자는 메모리에서 객체들의 풀을 할당하는 기능을 수행함. 객체들의 풀은 huge 페이지 메모리 공간에 생성되고, 사용 가능 객체를 저장하기 위해 ring을 사용함. 메모리 관리자는 객체들이 DRAM 채널에 균등하게 저장되고 객체들이 padding되도록 보장하는 정렬 도움 기능을 제공함.
-
버퍼 관리자(Buffer Manager)
인텔 DPDK기술에서는 OS가 버퍼를 할당하고 해제하는 데 보내는 시간을 줄이기 위해 메모리 풀에 저장되는 고정 길이의 버퍼들을 사전할당하여 관리함.
-
큐 관리자(Queue Manger)
인텔 DPDK기술에서는 기존의 spinlock을 사용하는 대신에 서로 다른 소프트웨어 요소들이 네트워크 패킷을 병렬 처리할 때 불필요한 대기시간이 발생하지 않도록 안전한 lockless 큐를 구현하여 사용함.
-
플로우 관리자(Flow Manager)
인텔 DPDK기술에서는 인텔 스트리밍 SIMD 확장 기술을 사용하여 네트워크 패킷 헤더에 대한 hash 정보를 효과적으로 생성하여, 네트워크 패킷들이 동일 플로우에 할당되어 고속처리되게 함.
-
폴 모드 드라이버(Poll Mode Driver)
인텔 DPDK기술에서는 기존의 비동기식 인터럽트를 기반으로 네트워크 패킷을 처리하는 대신에 최적화된 동기식 폴 모드 인터럽트 처리 루틴을 사용하여 패킷 파이프라인 속도를 높임.
<표 1>은 기존 기술에서 문제가 되는 네트워크 패킷처리 성능 저하 요소들에 대한 인텔 DPDK기술의 해결책을 나타낸다.

3. 인텔 DPDK기술의 패킷처리 구조
(그림 2)는 인텔 DPDK기술의 패킷처리 파이프라인구조를 나타낸다.
")
네트워크 인터페이스 카드에서 전달된 패킷은 가장 먼저 Packet I/O Rx 블록에서 처리된다. Packet I/O Rx 블록은 다수의 NIC 포트에서 수신된 패킷을 처리하는 기능을 수행하며 NIC에 대한 폴 모드 드라이버를 포함하고 있다.
Packet Parser 블록은 수신된 패킷에 대한 프로토콜 스택을 식별한다. 그리고 패킷 헤더에 대한 유효성을 검사하는 기능을 수행한다.
Packet Classification 블록은 수신된 패킷을 이미 알려진 트래픽 플로우 중의 하나에 매핑한다. Hash 함수를 사용하여 exact match 테이블 lookup을 수행하고 충돌상황을 해결하기 위해 bucket로직을 사용하는 기능을 수행한다.
Policer 블록은 srTCM 또는 trTCM 알고리즘을 사용하여 패킷에 대한 통계정보를 수집하는 기능을 수행한다.
Load Balancer 블록은 수신된 패킷을 응용 프로그램에 분배하는 기능을 수행한다. 각각의 응용 worker에 균등한 업무를 분배한다. 각각의 응용 Worker에 대한 트래픽 플로우의 친화도를 유지하고, 각각의 플로우 내의 패킷 순서를 유지하는 기능을 수행한다.
Worker 블록은 응용 프로그램이 수행되는 블록이다.
Dropper 블록은 RED(Random Early Detection) 알고리즘 또는 Weighted RED 알고리즘을 사용하여 congestion 관리를 수행하는 블록이다. 현재 스케줄러의 큐 로드 레벨과 패킷의 우선순위에 따라 패킷을 drop하는 기능을 수행한다.
Hierarchical Scheduler 블록은 수천 개(보통 64K개)의 leaf 노드(큐)로 구성된 5개의 레벨(출력 포트, 서브 포트, 파이프, 트래픽 클래스 및 큐)에 대한 계층적 스케줄러를 포함한다. 서브 포트와 파이프 레벨에 대해서는 트래픽 shaping을 수행하고, 트래픽 클래스 레벨에 대해서는 우선순위를 적용하며, 각각의 파이프 트래픽 클래스 내의 큐에 대해서는 WRR(Weighted Round Robin) 알고리즘을 적용한다.
Packet I/O Tx 블록은 다수의 NIC 포트로 패킷을 송신하는 기능을 수행한다.
상기 각각의 블록에 대한 자세한 내용은 인텔 DPDK 프로그래머 가이드[11]를 참조한다.
4. 인텔 DPDK기술 개발동향
인텔 DPDK 기반의 DPA기술은 2011년 처음 오픈 소스로 공개된 이후, 인텔의 전폭적인 지원하에 지속적으로 발전되고 있다. 인텔 DPDK ecosystem의 주요 업체에는 6Wind(WindGate DPDK, WindGate OVS(Open Virtual Switch)), Qosmos(DPI), Tieto(IP 스택), Win-driver, Radisys(40Gbps NIC DPDK 지원) 등이 있다. 현재 가장 최신 버전의 인텔 DPDK 버전은 2014년 10월에 발표된 1.8.0 버전이다[9][10].
한편, 인텔은 DPDK기술을 오픈소스 가상 스위치인 OVS(www.openvswitch.org)에 적용한 DPDK OVS를 2013년 6월 오픈소스(www.01.org/packet-processing/)로 공개하였다. 가장 최신 버전의 DPDK OVS는 2014년 8월 15일 발표된 DPDK-OVS 1.1 버전이다. 인텔은 오픈소스 가상 스위치인 OVS 그룹과의 긴밀한 공조를 통해, DPDK기술을 기반으로 하고 있는 DPDK-OVS를 OVS 2.3 버전에 OVS의 Data Plane 중 하나로 포함하여 시험 버전으로 시험 중에 있으며, 2015년 상반기에 출시 예정인, OVS 2.4 버전부터는 DPDK OVS를 정식으로 OVS의 Data Plane 중 하나로 포함할 예정이다[10][18].
한편, 네트워크 기능 가상화(NFV: Network Function Virtualization) 표준화를 진행하고 있는 유럽의 ETSI에서 진행해 온 NFV POC 중에 많은 관련 업체들의 제품군들이 인텔 DPDK기술을 채용하고 있는 상황이다. 대부분의 NFV POC는 인텔과의 협력을 통해 인텔 DPDK기술을 기반으로 하는 POC를 성공적으로 마쳤거나, 마무리하고 있는 상황이다[15].
마지막으로, 인텔은 2014년 7월에 인텔 DPDK 기술과 DPDK OVS기술 및 오픈소스 클라우드 OS인 오픈스택(OpenStack) Icehouse 버전과의 통합 기능을 오픈소스로 공개(www.01.org/packet-processing/)하였다. 가장 최근의 버전의 DPDK와 오픈스택의 통합 기술은, 2014년 12월 15일에 발표된, DPDK 기반 OVS 1.1 버전과 오픈스택 Juno 버전과의 통합 기술이다[10][12].
Ⅲ. Linaro ODP기술
ARM 기반 프로세서를 위한 리눅스 커널과 관련 툴을 만드는 비영리기관인 Linaro(www.linaro.org)의 네트워킹 그룹인 LNG(Linaro Networking Group)에서는 오픈소스이면서 플랫폼에 상관없는 네트워킹 데이터 평면에 API를 제공하기 위한 연구개발을 진행하여, ODP API라는 이름의 오픈소스(www.opendataplane.org)로 공개하였다.
1. Linaro ODP기술의 개요
(그림 3)에서 ODP 응용 프로그램은 리눅스 사용자 공간에서 한 개의 프로세서로 동작하며 최소한의 리눅스 API를 호출한다. ODP 응용 프로그램은 커널의 오버헤드를 야기하지 않고, 가용한 하드웨어의 특성을 사용하여 데이터 플레인 가속 처리하기 위하여 ODP API(또는 SDK API)를 호출한다. ODP는 하드웨어 의존적인 SDK API를 호출하는 것을 배제하지 않는데, 이러한 SDK API에 대한 호출 때문에 플랫폼에 상관없는 소스 레벨의 호환성을 제공해 주지 못할 수도 있으므로 이것은 전적으로 응용 프로그램을 디자인할 때 결정해야 한다. 데이터 플레인 응용을 지원하는 플랫폼으로써, ODP 응용 프로그램은 치명적인 성능 또는 지연 요구사항이 없고 리눅스 API를 전적으로 사용하는 리눅스 사용자 평면 제어 또는 관리 평면 기능을 구현한 응용 프로그램과 병렬적으로 실행될 수도 있다[13][14].
")
2. Linaro ODP 패킷처리 구조
(그림 4)는 Linaro ODP에서 바라보는 네트워킹 SoC의 추상화된 논리적 처리 구조이다[13][14]. (그림 4)에서 녹색으로 표시된 부분은 소프트웨어 블록을 의미한다. 오렌지색으로 표시된 부분은 하드웨어 블록에 의해 대부분 수행되는 부분으로 간주하지만, 소프트웨어에서 수행될 수도 있다. 사선 실선으로 표시된 부분은 낮은 액세스 지연을 가지는 펌웨어와 같은 하드웨어에서 아주 가까운 소프트웨어에 의해 수행되는 기능을 나타낸다. Packet Input 블록은 물리적 입력단의 패킷 포트를 추상화한다. Pre-Processing 블록은 물리 인터페이스 속도와 동일한 속도로 처리하며 버퍼 풀의 선택과 첫 번째 레벨의 congestion 제어를 위한 패킷 분류 기능을 수행한다. Input Classification 블록은 구별된 트래픽 플로우를 분석하고 분류하여 큐에 배정하고 패킷에 대한 분석 결과인 메타 데이터를 추가하는 기능을 수행한다. Ingress Queuing 블록은 실제 페이로드에 대한 메타데이터인 descriptor들의 큐(FIFO)를 제공한다. 큐에 대한 descriptors는 HW 장비 또는 S/W에서 도착한다. Delivery/Scheduling 블록은 동기화된 SW/HW 인터페이스, 동작 스케줄링과 한일 수신점에 대한 다수 개의 프로세서 코어에 대한 로드 분산 기능을 제공한다. 스케줄러는 큐 우선순위 설정과 큐의 상태, 그리고 CPU의 상태에 따라 결정을 내린다. Accelerator 블록은 비동기적 큐 기반의 인터페이스에 대해, 암호화 또는 압축과 같은 특수 목적 처리를 수행한다. Co-processors 블록은 Accelerator 블록과 유사하지만, S/W(특수 opcode, CPU 레지스터, 특수 주소)에 대한 동기화된 인터페이스를 가지고 빨리 동작을 수행한다. Egress Queuing 블록은 출력 포트를 향해서 동기화된 인터페이스를 제공한다. 각각의 큐는 논리적 포트로 매핑되고, 설정된 QOS 기능을 선택적으로 수행하기도 한다. Post Processing 블록은 패킷을 출력 포트를 위해 스케줄링 하고 패킷들이 장비를 떠나면 패킷 버퍼를 해제한다. 또한, 패킷 checksum과 같은 inline 가속 기능을 제공할 수도 있다. Packet Output 블록은 물리 출력 포트에 대한 인터페이스를 제공한다.
")
Ⅳ. 결론
인터넷 트래픽의 향후 5년간 연평균성장률(CAGR)은 24%(유선 트래픽이 21%, 모바일 트래픽이 68%)로 예상되지만, 인터넷 트래픽을 처리하는 칩셋의 성능 연평균성장률은 14% 정도로 예상되고 있다. 이에 따라, 증가하는 인터넷 트래픽과 이를 처리하는 칩셋의 성능 사이에 격차(Forwarding Gap)가 발생하고 있는 상황이다. 이런 격차를 줄이기 위해 시작된 연구기술이 데이터 플레인 가속화(DPA) 기술이다.
본고에서는 데이터 플레인 가속화 기술인 인텔 DPDK기술의 개요 및 주요 기능 분석을 통해 기존 데이터 플레인 가속화 기술에서 문제가 되는 네트워크 패킷처리 성능 저하 요소들에 대한 인텔 DPDK 기술의 해결책을 살펴보았다. 또한 인텔 DPDK기술 개발동향을 통해, 인텔 DPDK기술이 NFV의 핵심기술로 자리잡아 가고 있음을 살펴볼 수 있었다. 또한, 본고에서는 또 다른 데이터 플레인 가속화 기술 중 하나인 Linaro ODP의 개요, 패킷처리 구조와 현재 기술동향을 살펴보았다. Linaro ODP기술은 인텔 DPD 기술의 대항마를 자처하고 나섰지만, 아직 초기 개발 단계이다.
네트워크 기능 가상화(NFV) 기술은 소프트웨어 정의 네트워킹(SDN: Software Defined Networking) 기술과 함께 기존 하드웨어 중심의 네트워크 인프라를 소프트웨어 중심으로 진화시킬 수 있는 새로운 네트워크 기술로 각광받고 있다. 이미 상용화 초기 단계에 접어든 소프트웨어 정의 네트워킹 기술과는 달리 네트워크 기능 가상화(NFV) 기술은 ETSI NFV를 중심으로 한 기술 논의와 상위 문서작업에 많은 노력을 기울여 왔지만, NFV 기술이 상용화 되기 위해서는 데이터 플레인 가속화 기술과의 융합이 필수적이라 볼 수 있다[15].
국내에는 대학교, 연구소 등을 중심으로 인텔 DPDK기술을 분석하고 개선하기 위한 연구개발을 진행하고 있으며, 기존 제품을 인텔 DPDK 기반으로 변경하는 작업을 하고 있는 국내 기업들도 있다. 기존의 인텔 DPDK기술에 추가하여, 새로 소개된 Linaro ODP기술에 대한 관심도 가져야 할 것으로 판단된다.
용어해설
데이터 플레인 가속화 기술기존 커널 공간에서 처리되던 패킷처리 기술의 패킷처리 속도 제한 문제를 해결하기 위해 NIC에서 바로 사용자 공간으로 패킷을 전달하여 고속으로 패킷을 처리하는 기술
약어 정리
DNA
Direct NIC Access
DPA
Data Plane Acceleration
DPDK
Data Plane Development Kit
EAL
Environment Abstraction Layer
KNI
Kernel Network Interface
LNG
Linaro Networking Group
NFV
Network Function Virtualization
ODP
Open Data Plane
OVS
Open Virtual Switch
RED
Random Early Detection
SDN
Software Defined Networking
WRED
Weighted Random Early Detection
WRR
Weighted Round Robin
References
(그림 1)
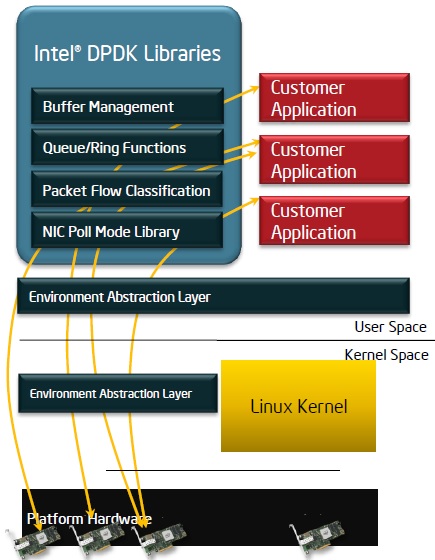
인텔 DPDK 구조<a href="#r017">[17]</a>
<표 1>
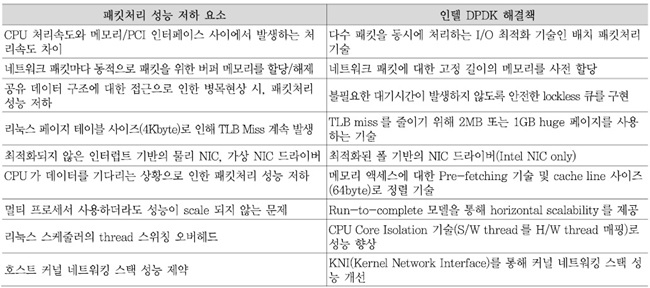
인텔 DPDK 해결책
(그림 2)
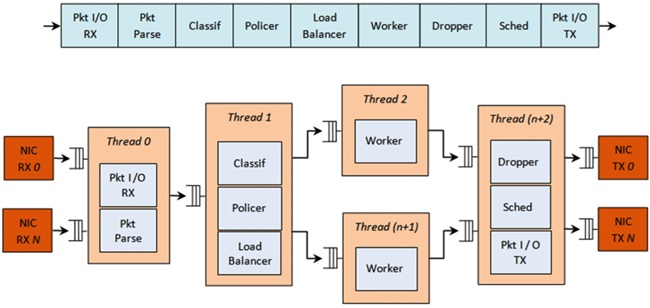
인텔 DPDK 내부 패킷처리 구조<a href="#r011">[11]</a>
(그림 3)
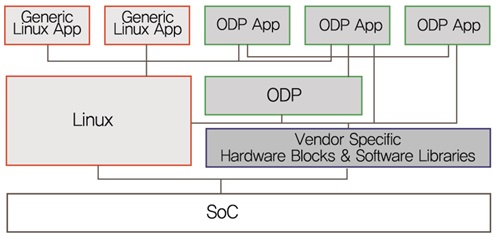
Linaro ODP 구조<a href="#r014">[14]</a>
(그림 4)
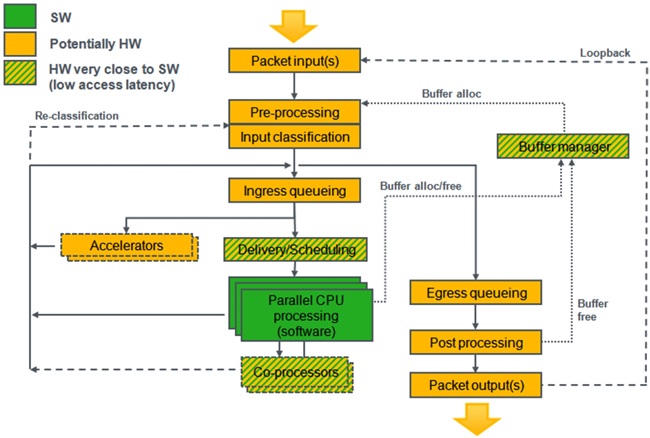
Linaro ODP 추상화된 패킷 처리 구조<a href="#r014">[14]</a>