자유발화형 음성대화처리 기술동향
Trends of Spontaneous Speech Dialogue Processing Technology
- 저자
- 권오욱, 최승권, 노윤형, 김영길, 박전규, 이윤근 / 언어처리연구실
- 권호
- 30권 4호 (통권 154)
- 논문구분
- SW·콘텐츠 기술동향 특집
- 페이지
- 26-35
- 발행일자
- 2015.08.01
- DOI
- 10.22648/ETRI.2015.J.300403
- 초록
- 모바일 혁명, 빅데이터와 사물인터넷 시대에 접어들면서 인간의 음성과 말로 다양한 장치와 서비스를 제어하고 이용하는 것은 당연시되고 있다. 음성대화처리 기술은 인간 중심의 자유로운 발화를 인식하고 이해 및 처리하는 방향으로 발전하게 될 것이다. 본고에서는 현재 음성대화처리 기술 국내외 기술 및 산업 동향과 지식재산권 동향을 살펴보고, 인간 중심의 자유발화형 음성대화처리 기술 개념과 발전방향에 대해 기술한다.
Share
I. 서론
음성언어기술은 인간의 가장 중요한 정보전달 및 의사소통 수단인 언어를 다루는 기술로서, 21세기 정보화 사회의 핵심 User Interface/User eXperience(UI/UX) 기술이며, IT-교육 융복합 기술 및 서비스 확보를 통해 (그림 1)과 같이 음성언어기술 기반 SW는 국가 및 기업의 미래 경쟁력 향상에 기여할 것으로 기대하고 있다.
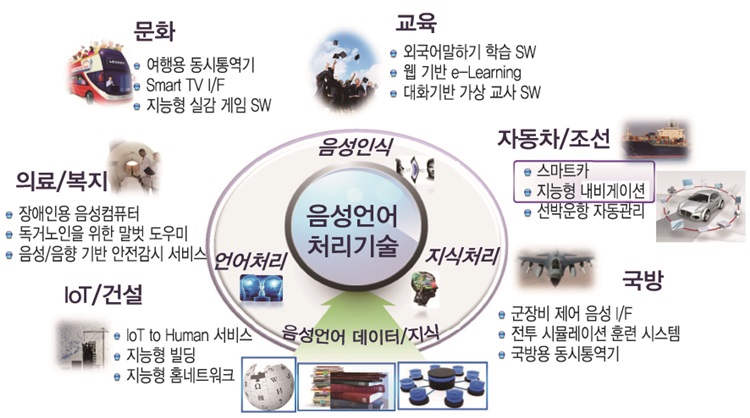
음성언어기술 SW의 대표적인 예로, 2011년 Apple의 Siri를 통해 선보인 음성 대화형 인터페이스를 들 수 있다. Siri 이후 다양한 정보단말기 및 서비스의 사용자 편의성을 높이기 위해 대화모델 기반 자연어 음성인터페이스 요구가 점차 증대되고 있다. 대화모델 기반 자연어 음성인터페이스는 사전지식 없이 초기 진입하는 사용자를 대상으로, 시스템 이용 안내에서부터 원하는 목적에 대한 상담자 역할까지 임무 수행이 가능하며 모바일 기기를 이용함에 있어서 가장 단순하고 지능화된 인터페이스로 고도의 복잡한 작업 처리를 가능하게 함으로써 새로운 사회적, 문화적 변화를 선도해 나갈 수 있다. 특히, 터치 및 키보드 식 인터페이스를 사용할 수 없는 차량에서 대화형 인터페이스는 차량 제어 및 개인비서 역할을 수행할 수 있다. 2015년까지 세계시장 규모가 2,112억 달러로 증가할 것으로 전망[1]하는 스마트카(Smart Car)의 필수요소기술로 인식되어 Apple, Microsoft, Nuance 등에서 개발된 음성대화인터페이스 기술은 Ford, Benz, Honda, BMW 등 차량에 적용하는 사례가 증가하고 있다.
음성대화처리 기술은 단순한 정보검색 및 작동을 위한 인터페이스로의 역할만이 아니라, 사람의 일부 전문적인 역할을 수행하는 분야로 관심 분야가 확대되고 있다. 그 대표적인 예로, 음성대화처리 기술을 언어학습 서비스에 적용하여 원어민과 대화하는 효과를 주기 위한 Dialog based Computer-assisted Language Learning(DB-CALL)과 말벗 서비스를 포함한 개인서비스용 로봇 등이 있다. 2013년 기준으로 언어학습 세계시장 규모는 563억 달러에 달했고, 특히 디지털 언어학습 시장은 아직 초기 단계로써(전체 언어 학습 시장의 5%) 점차 관련 시장을 대체해 나갈 것으로 전망되는 등 성장 잠재력이 아주 큰 시장이다[2]. 하지만, 세계적으로 음성대화처리 기술을 이용한 영어 말하기 학습 솔루션은 단순히 발음만 확인하는 단계의 제품이 출시되고 있는 실정이다.
음성대화처리 기술을 이용한 영어 학습 서비스에서 보듯이, 현재 실제 음성대화처리 기술을 이용한 서비스 전망과 실제 서비스 수준과는 많은 차이를 보인다. 이러한 차이는 음성대화처리 기술을 구성하는 음성인식 기술과 대화처리 기술의 현재 기술력이 음성대화처리의 파급 효과를 충족할 정도가 아니어서 생기는 현상이다.
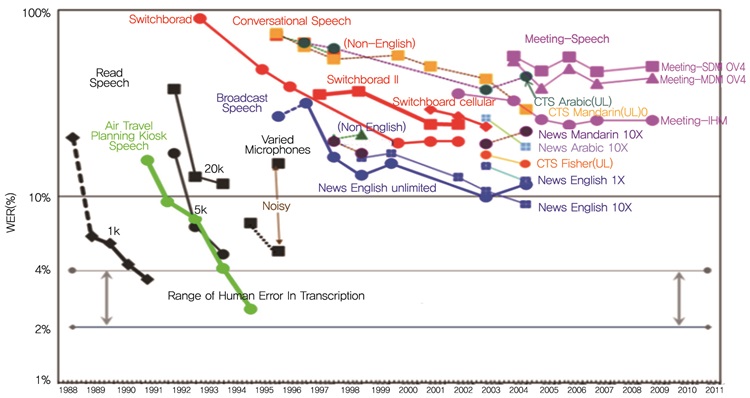
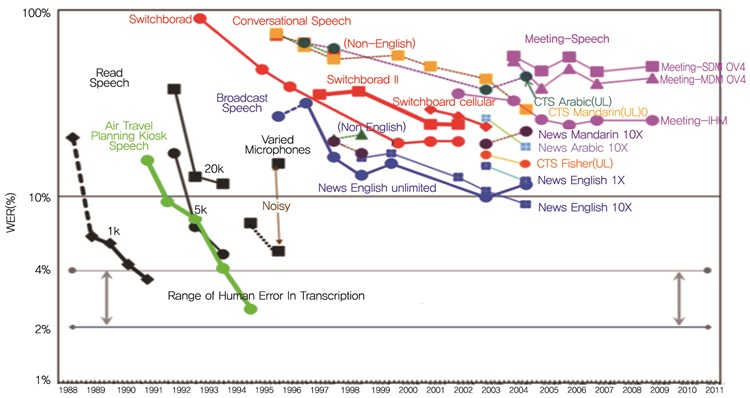
현재의 음성인식 기술은 비교적 정확히 발성한 음성에 대해서는 상용화 수준의 인식률을 보이나 대화체 음성에서 나타나는 비정형 문형이나 부정확한 발음에 대해서는 낮은 인식률을 보인다. (그림 2)에서 보듯이, 음성인식 기술이 기계(컴퓨터)와 인간의 인터페이스용으로 적용될 경우(예를 들어 스마트폰의 음성검색, 내비게이션의 음성명령 등) 비교적 우호적이고 명료한 발성(Read Speech)에서는 음성인식 정확도가 양호하다. 그러나 대화체 음성인식에 적용될 경우에는(예를 들어 콜센터 녹취데이터 음성인식, 회의록 음성인식 등) 비정형화된 음성입력이 다수 발생함으로써 인식 성능이 매우 저하되어 약 50~60% 정확도를 나타낸다[3].
현재 대화처리 기술은 사용자 의도를 인식해야 할 범위가 작은 도메인(예를 들어, 전화/메시지 작동, 날씨 검색, 경로 탐색, 일정 관리 등)에서는 상용화 수준의 성능을 보이나 처리할 서비스가 조금 복잡하여 사용자와의 대화가 길어지는 도메인(예를 들어 상품/표 구입 및 예약 등)에서는 음성인식 오류와 대화처리 오류가 복합되어 낮은 성공률을 보이고 있다. 명확한 서비스 업무를 처리하는 목적이 아니라, 사람과 같은 대화 상대로서의 대화처리 기술에서는 많은 단발성 대화 응답 예제 또는 고정된 대화 흐름 패턴을 가지고 처리를 하고 있다. 대화처리 기술은 일반적인 언어처리 기술과 마찬가지로 대화 응답을 위한 지식을 사람에 의해 구축해야 하는 확장성의 한계도 가지고 있다. 음성대화처리 기술은 인간의 말을 알아듣고 이해하여 명령을 수행하고 대화를 하는 것을 목적으로 하며 인간 중심의 자연스런 음성 발화를 처리 가능한 기술로 발전한다면 (그림 1)의 경쟁력을 확보할 수 있을 것이다.
Ⅱ. 기술개요
자유발화형 음성대화처리 기술이란 인간과 컴퓨터 간의 단순한 패턴이나 시나리오 형태의 고정된 대화를 벗어나, 사용자의 자연스러운 자유발화를 듣고 의도를 파악하여 주제와 문맥에 맞는 자연스러운 대화를 가능하게 하는 음성대화처리 원천기술을 말한다. (그림 3)은 자유발화형 음성대화처리 기술이 자연스러운 인간의 음성을 인식하고 이를 이해하여 표현 및 반응하기 위한 2가지 핵심 기술인 비정형 자연어 음성인식 기술과 자유 대화처리 기술을 나타내고 있다. 자유발화형 음성대화처리 기술은 인터페이스할 대상이 제한적이고 단순하여 사용자인 인간이 기계가 알아들을 수 있도록 발화하는 것이 아니라, 사용자가 자신의 목적을 대화를 통하여 구체화해 나가는 상황에서 발생하는 비정형 자연어 음성과 기계와의 대화 과정에서 제공할 서비스(주제, 도메인)에서 벗어나는 대화를 인지하고 사용자의 목적을 인지하도록 대화를 유도한다.
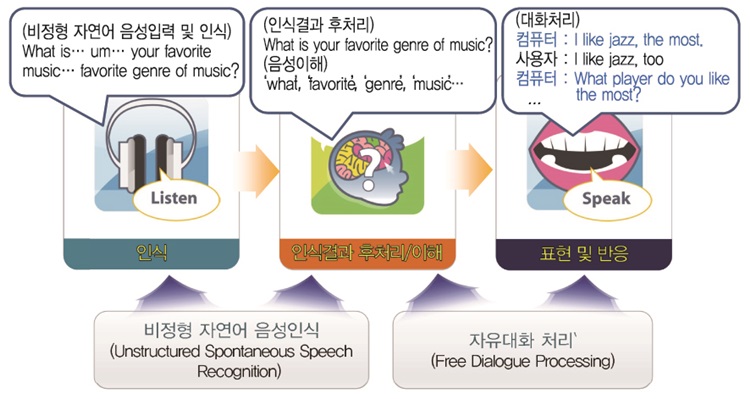
기존의 음성인식 기술은 인간의 청각만을 모델링하였으나 비정형 자연어 음성인식 기술은 인간의 청각과 언어적 사고를 융합하여 다차원 지식을 모델링 및 구현하여야 하며 이를 통해 비정형 자연어 대화체 음성에 대한 인식 정확도를 향상할 것으로 기대한다. 기존의 대화처리 기술은 정해진 대화 시나리오 기반의 고정된 대화만이 가능하였으나, 자유 대화처리 기술은 현실세계의 자유 대화상황을 처리하기 위해 동적으로 변하는 대화 문맥을 처리 및 응답하는 기술이어야 한다. 다양한 자유 발화 대화 상황을 처리하기 위해 대용량 대화 및 음성 데이터에서 자연어 음성인식 및 자유발화형 대화처리 지식을 학습함으로 도메인 이식 및 확장을 할 수 있어야 한다.
자유발화형 음성대화처리 기술을 언어 학습에 적용하기 위해서는 학습자와의 자유대화 상황에서 주제 및 문맥에 따라 문법 및 표현 오류를 파악하여 가르쳐 줄 수 있어야 한다.
Ⅲ. 기술 및 산업동향
1. 국내동향
Apple, Google, Microsoft 등의 음성대화 서비스의 영향으로 국내에서도 단순 음성검색 서비스에서 대화형 음성검색 서비스로 진화하고 있다. 특정 영역이나 고정된 대화 패턴에서 높은 성능을 보이나, 대화문맥을 고려하지 않은 단순 자연어 음성 검색 수준을 보인다.
모바일 스마트폰 정보서비스에서는 삼성전자가 지능형 개인비서 SW인 Vlingo를 도입하여 S 보이스를 출시하였고, 다음(Daum)은 자체 기술로 자연어 대화 검색 기능을 도입한 다음지도를 출시하였다. 2013년부터 삼성전자와 LG전자에서 콘텐츠 및 웹 정보에 대한 음성검색과 음성 제어명령이 가능한 스마트TV를 출시하고 있으며, 국내 IPTV 업체인 LG유플러스, 올레TV, SK브로드밴드 모두에서 자연어 음성검색 기능을 제공하고 있다. 하지만, 대화처리 기술이 적용되지 않은 단순한 자연어 음성검색 기술이어서 스마트TV의 복잡한 기능을 제어하고 많은 정보를 처리하기에는 기술적 한계가 있다.
국내의 음성대화처리 기술 연구는 ETRI, 포항공대, 서강대, KT 등을 중심으로 활발히 연구가 진행 중이다. ETRI는 자연어 음성인식 기술, 기계학습 및 패턴기반의 하이브리드 대화이해 기술, 다양한 태스크 처리에 적합한 계층적 태스크 기반 대화관리 모델을 개발하였다. ㈜파인디지털에서 ETRI의 음성대화처리 기술을 차량용 정보서비스에 적용하여 2014년부터 국내 최초의 대화형 음성인식 내비게이션 Fine Voice를 상용화하였다. ETRI에서는 음성대화처리 기술을 영어교육에 적용하여 고정형 대화 상황에서의 문법 오류 교정과 학습자 대답 적합성을 가르쳐주는 음성대화형 영어 학습 서비스인 지니튜터를 개발하였고 2015년에 청담러닝, iMBC, 동아출판 등 6개 수요업체에서 시범서비스를 진행하였다. (그림 4)는 ETRI의 음성대화형 영어 학습 서비스인 지니튜터의 소개 사이트로써 고정 대화 상황에서 대화하고 사용자의 영어 문법 및 표현 오류를 교정하는 화면을 보여준다.

ETRI는 음성대화형 영어 학습을 위해, 한국인의 비원어민 영어 발화를 음성인식하기 위한 특화 기술을 개발하였고 이를 기술이전하여, 모바일용 영어 말하기 학습 서비스인 GnB스마트 잉글리시와 NC소프트와 영어학습용 게임 SW인 청담러닝의 호두잉글리시를 상용화하였다.
포항공대는 언어처리 및 대화처리 기술에 대한 다양한 실험적인 선행 연구들을 진행 중이다. 대표적으로 예제기반 대화관리 모델, 영어교육을 위한 대화기반 언어학습 시스템, 다중사용자 대화시스템 등에 대한 기초 선행 연구와 특정 영역의 프로토타입들을 개발하여 관련 시연 영상을 유튜브에 공개하고 있다.
서강대와 KT 등에서는 공동연구로 다중영역 정보서비스를 위한 대화형 개인비서 프로젝트를 2012년부터 2014년까지 진행하였다. 이 과제는 일정, 이메일 등의 개인정보, 날씨, 길찾기 등의 일상정보, 웹서비스 등에서의 개인업무를 처리하는 태스크 기반 음성대화기술과 이들 기술을 기존 서비스와 연계 가능하게 하는 개인비서 플랫폼 구축을 목표로 진행하였다.
2. 국외동향
가. 음성인식 기술동향
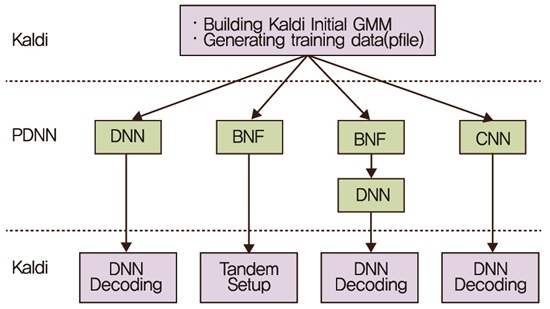
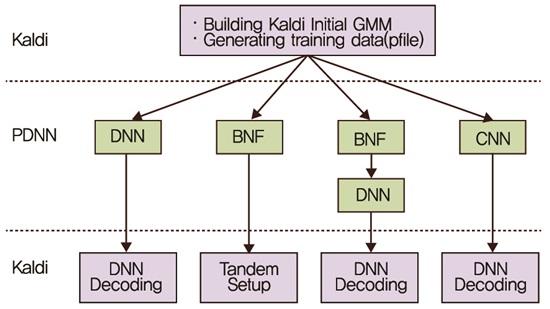
현재의 음성인식 구조는 수십 년간 유사한 형태를 유지하고 있으며 성능에 대한 breakthrough가 이루어지지 않고 있다. 음성인식 구조는 단구간 스펙트럼 분석 기법인 Mel-Frequency Cepstral Coefficients(MFCC) 등에 기반한 특징 추출, 가우시안 분포 모델링에 의한 음향모델, Hidden Markov Model(HMM)에 기반한 동적 디코딩, n-gram 기반의 언어모델 등으로 구성되며 이와 같은 구조는 대부분의 상용 음성인식 시스템에 적용되고 있다. 이러한 음성인식 알고리즘의 구성은 음성분석 및 모델링, 인식 과정을 지나치게 단순화 함으로써 인간의 인지 과정에 비하여 정밀도와 유연성이 떨어진다. 이를 극복하기 위해, Deep Neural Network(DNN) 및 심층학습(Deep Learning)을 이용하여 기존의 Gaussian Mixture Model(GMM) 대비 음성인식 성능이 대폭 개선되는 효과를 보임에 따라 Google, Microsoft, IBM 및 국내 ETRI, NHN 등 국내외 음성인식 기술을 보유한 주요 기관에서 적용을 완료했으며 이에 대한 관련 연구가 국내외에서 활발하게 이루어지고 있다[4][5][6]. (그림 5)는 대표적인 음성인식 툴킷인 Kaldi에서 기존의 음성인식 툴킷에 DNN을 적용하는 방식을 설명하는 개요도이다[7].
세계적으로 Google, Nuance 등에서는 다국어 음성인식 상용 서비스를 통해 축적한 대용량 다국어 실사용자 음성로그 DB을 기반으로 다국어 음성인식 기술의 강자로 위치를 확고히 하고 있다. 하지만, 최근에는 한국 ETRI, 중국 iFlytec, 일본 Amivoice 등 로컬 기관 및 업체의 모국어 음성인식 기술 수준이 대폭 향상되고 있다. 이는 자국 내 모국어 음성언어 리소스 확보가 용이하고 음성인식 성능이 대용량 음성데이터 확보에 크게 의존적이기 때문으로 판단되며 앞으로 이러한 개발 추세는 타 국가에까지 확산될 것으로 보인다.
Google은 무료 서비스(또는 API)를 통해 사용자들의 대용량 실사용 음성언어 로그 DB(음성, 텍스트 문장 등)를 수집하고, 이를 클라우드 인프라를 기반으로 고속, 고효율로 처리하여 음성인식 엔진의 성능 개선에 활용하고 있다. Nuance는 Apple Siri에 핵심 음성인식 기술을 공급하며, Google, Microsoft, Apple을 비롯해 세계 전화자동 응답 장치(ARS) 시장의 97%를 점유하는 등 전 세계 음성인식 시장의 70% 이상을 점유하고 있다. SRI에서는 EduSpeak 등 언어교육을 위한 음성인식 기술, SRILM 등 범용 언어모델링 도구 등을 연구하고 있으며, 최근에는 기본적인 음성인식 기술에 대한 연구보다는 인공지능 및 의미이해 등에 대한 연구가 주류를 이루고 있다.
모바일 통신 시스템을 개발하는 Vocera에서는 자사가 개발한 무선망 솔루션 및 장비에 대해 음성인식, 전화회의 등을 적용하여 핸즈프리 음성 통신 시스템을 서비스하고 있다. 특히 음성인식을 통해 해당 의료진에 직접 통화가 가능하도록 지원하여, M.D. 앤더슨 암센터 등에 솔루션을 공급하였다. Vocollect는 헤드셋과 웨어러블 컴퓨터를 착용해 양손으로 포장 작업을 하고 동시에 상품 분류를 음성인식으로 시스템에 입력하도록 하는 ‘Talking Warehouse’라는 물류 전용 솔루션을 개발하였다.
나. 대화처리 기술동향
현재 대화처리 기술은 크게 태스크 기반 대화처리(task-oriented dialog processing) 기술과 챗봇(chatbot) 기술로 구분할 수 있다. 태스크 기반 대화처리 기술은 서비스할 태스크(예를 들어, 전화/메시지 작동, 날씨 검색, 경로 탐색, 일정 관리, 표 구입 등)에서 사용자의 요구(예를 들어, 엄마에게 전화하기, 서울 오늘 날씨검색, 서울역까지 경로 찾기 등)를 알아듣고 그 요구에 맞는 서비스를 제공하는 기술이다. 챗봇 기술은 특정한 태스크를 처리하는 대화가 목적이 아니라, 사용자가 사람과 채팅하듯이 사용자의 대화를 들어 주고 맞장구치며 되물어 주는 등의 사람과의 대화와 유사하도록 하는 기술이다.
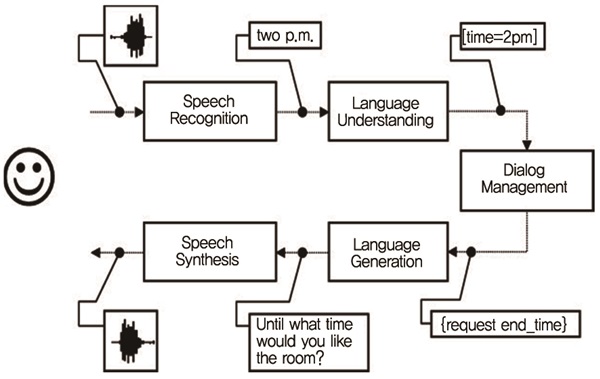
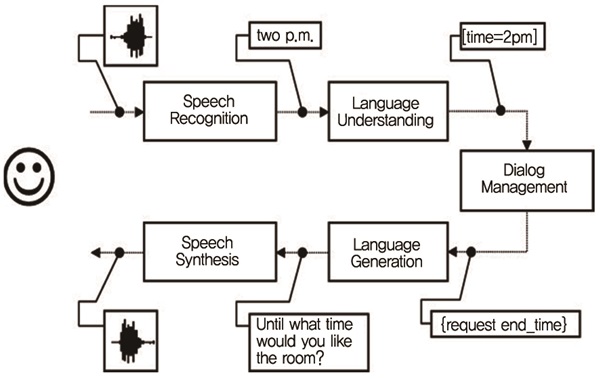
(그림 6)에서 보듯이, 태스크 기반 대화처리 기술은 정해진 태스크에서 사용자 요구를 정확하게 알기 위해서는 음성인식된 사용자 발화에서 의도(예를 들어, 전화하기, 날씨 검색, 경로찾기 등)와 슬롯(예를 들어, 전화 대상=엄마, 날씨검색 도시=서울, 날씨검색 날짜=오늘, 경로 목적지=서울역 등)을 파악하는 음성언어이해(Spoken Language Understanding: SLU) 기술과 태스크를 수행하기 위해 부족한 슬롯 정보나 의도를 파악하여 주어진 일을 마무리하기 위한 일정한 처리 흐름을 관리하는 대화관리(Dialog Management) 기술로 구성된다. 현재 태스크 기반 대화처리 기술은 아주 작은 슬롯 수와 의도 수가 한정되어 단순한 태스크 처리에서 시스템 설계자가 예상한 대화 흐름 내에서 상용화 수준의 정확도를 보인다.
최근, 언어이해기술에서는 수동적으로 구축한 기존의 지식/규칙 기반 방식의 확장성 및 강건성 문제점을 해결하기 위해 통계/데이터 기반 방식 및 기계학습을 적용하는 방법이 많이 연구되고 있다. 정보검색 기법을 적용하여 필요한 정보만으로 의도를 파악하거나, active learning 등의 기법을 적용하여 강건성과 확장성을 개선하려는 연구를 진행하였다[9][10]. Microsoft에서는 도메인 독립적인 SLU를 위한 Deeper Understanding, 쉽게 SLU를 확장할 수 있도록 하기 위한 Scaling SLU, DNN기술을 SLU에 적용하기 위한 ‘Deep Learning for SLU’ 프로젝트를 진행 중에 있다[11][12][13].
대화관리 기술은 대화 상태를 기술하는 방식에 따라 규칙 스크립트 방식, Finite State 방식, Form 방식, Agent 기반 방식, 예제기반 방식과 Partially Observable Markov Decision Processes(POMDP) 모델 등으로 구분할 수 있으며, 이러한 대화 상태의 흐름 방식에서 정해진 규칙으로 하는 방법과 강화학습(Reinforcement Learning) 방법으로 구분할 수 있다. 대표적인 전통적 대화관리 방법으로 CMU의 Agent 기반 대화관리인 Ravenclaw[8]와 IBM의 Form 기반 방식인 FDM과 HOT을 들 수 있다[14]. 최근에는 음성인식 및 음성대화이해의 오류에 강건하게 반응할 수 있는 POMDP 모델 및 DNN 기반의 강화학습 방법론에 대한 연구가 주도적으로 이루어지고 있다[15][16][17][18]. 하지만 이들 연구들이 슬롯 수와 슬롯 인스턴스 수, 대화 상태 수에 대하여 제한적이어서 상용화 단계에 이르지 못하고 있다. 반면에 대부분의 Siri와 같은 상용화 시스템에서의 태스크 기반 서비스(예를 들어, 일정관리, 날씨 검색, 알람, 경로 탐색 등)는 구현 및 제어가 간단한 규칙 스크립트 방식, Finite State 방식과 Form 방식을 채택하고 있다.
챗봇 시스템으로는 Artificial Intelligence Markup Language(AIML)을 기반으로 한 A.L.I.C.E., Pandorabots, AI Buddy 등과 그 외 My Cyber Twin, Rosette 등이 있으며 아직 학습기능을 갖춘 지능형 챗봇이 완성되지 못하고 규칙, 패턴, 예제 매칭에 의존하는 챗봇 기술이 주류를 이룬다[19]. 현재 챗봇 기술은 같은 대화에 대하여 같은 반응 또는 반복적인 반응을 보이는 한계를 보인다. 이러한 문제를 극복하기 위해 최근에는 사용자가 발화한 내용에서 사용자 개인 정보를 추출하여 대화에 활용하려는 연구가 진행되고 있다 [20][21]. 2014년에 러시아 개발진이 개발한 유진 구스트만이라는 챗봇 시스템이 최초로 튜링 테스트를 통과했다고 하여 이슈화된 적 있지만, 기계적이고 엉뚱한 반응으로 인하여 튜링 테스트의 모호성에 대한 의구심이 제기되고 있다.
Apple의 Siri 이후에, 스마트 폰 환경에서의 대화형 개인비서가 기업 기술력을 나타내는 필수적인 요소가 되어, Google Now, Mirosoft의 Cortana, 삼성의 S 보이스 등이 출시되었다. 이들 대화형 개인비서 시스템은 태스크 기반 음성대화시스템과 챗봇 시스템, 질의응답 시스템, 웹검색 시스템 등이 교묘하게 결합하여 각 시스템 기술의 한계 및 서비스 범위를 상호 보완하는 형태로 구성되어 있다. Apple, Microsoft, Nuance 등에서 개발된 음성대화인터페이스 기술은 Ford, Benz, Honda, BMW 등 차량에 적용하여 눈과 손이 차량 운전으로 자유롭지 못한 상태에서의 경로탐색 등의 다양한 서비스를 제공한다.
일본 소프트뱅크에서 대화가 가능할 뿐 아니라 감정까지 읽을 수 있는 인간형 로봇 페퍼(Pepper)를 2015년에 출시할 예정이라고 발표하였다. 로봇 페퍼에 사용된 Wit.AI의 대화처리 기술은 자연어처리 분석을 통해 인간의 말을 해석하고 의도를 파악하는 기술에 기반을 두고 있으나 아직 초보적인 단계이다. Wit.AI는 최근 페이스북에 인수됐고, 삼성, Nao, 일본 소프트뱅크 등 3,000개 기업에서 사용되는 기술을 개발 중이다.
컴퓨터를 이용한 언어학습시스템(Computer Assisted Language Learning)은 최근 음성인식과 언어, 대화처리기술과 더불어 외국어 학습 이론, 사용자 문법 오류 검출, 오류 피드백, 학습자 유창성 평가 등을 결합한 연구를 EUROCALL, CALICO 등을 포함한 다양한 그룹에서 진행하고 있다. 또한, 세컨드라이프같은 가상세계에서의 언어학습, 모바일지원언어학습, 인공지능기술을 접목한 지능적 언어학습 시스템 등으로 확장되고 있다[22][23][24]. Microsoft는 Computer Assisted Lan-guage Learning(CALL)시스템으로 Encarta Interactive English Learning 시스템을 개발하였다. 각 유닛은 리스닝, 스피킹, 실습 및 어휘 학습의 기능을 포함하며 유닛이 완료되면 주요 항목에 대해 테스트할 수 있는 Virtual Challenge를 수행하도록 구성되어 있다[24].
CALL에 음성대화처리 기술을 접목한 DB-CALL 관련된 시스템으로 Role-playing이나 언어를 배울 수 있는 기능 및 환경을 제공해 주는 DEAL, SPELL, SCILL, ITSPOKE 시스템 등이 있는데, 대부분 정해진 시나리오에 한정되어 있다[25][26][27]. 하지만 일반적인 대화시스템과 달리 해당 언어에 미숙한 언어학습자의 발음 및 발화를 이해하고 피드백을 제공해야 하는 어려움이 있고, 이러한 이유로 대화기반 컴퓨터 영어학습 시스템의 성능은 아직 부족한 상황이다.
Ⅳ. 지식재산권 동향
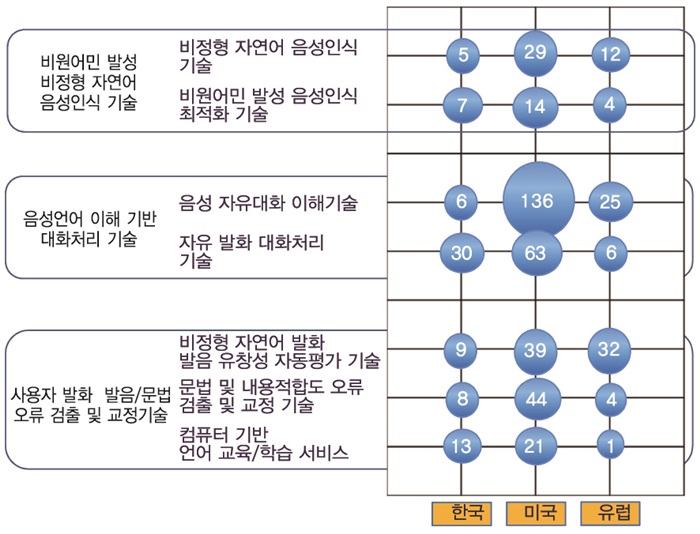
자유발화형 음성대화처리 기술의 특허 출원현황을 파악하기 위해, (그림 7)과 같이 주요 요소 기술별로 주요 국가별 출원 현황을 분석하였다. 비원어민이 발성한 비정형 문장에 대한 음성인식 기술 특허는 최근에 대화체를 대상으로 주로 국외에서 출원되기 시작하고 있다. Human Computer Interaction(HCI)를 위한 대화처리 기술에 대한 관심의 증가와 함께, 사용자 발화 문장 이해 및 의도 파악과 관련된 특허가 집중되고 있다. 언어학습을 위한 사용자 발화 발음/문법 오류 교정 기술은 국내외에서 관심을 갖기 시작한 단계로서 현재까지 출원된 특허가 많지 않은 상황이다.
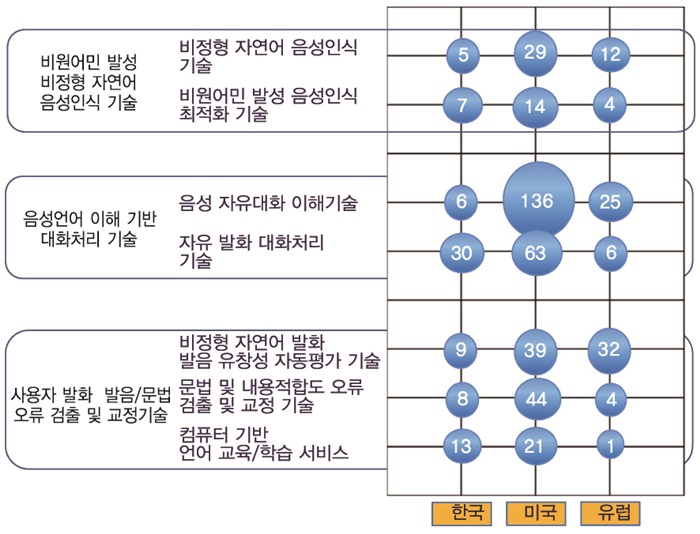
음성인식 분야의 국내외 특허동향은 한때 주춤했던 Google, Microsoft, Facebook 등 글로벌 기업의 특허가 최근에 많이 출원되고 있지만, 비원어민 발성 비정형 음성인식 특화와 관련된 특허는 상대적으로 그 수가 적다. 특허 내용 측면에서 보면, 페이스북은 자동 음성통역 분야에 특화된 자연어(다국어 대상) 음성 인식 기술을 확보하고 있으며, Nuance는 다국어를 인식 대상으로 하는 대화체 음성인식 기술 및 고객을 위한 인식엔진 특화(customization) 기술을 확보하고 있다. 비원어민이 발성한 비정형 음성인식 특화 기술과 관련된 특허는 해외에서도 특허 출원 건수가 적기 때문에 추가적인 지적재산권의 확보가 가능할 것으로 판단된다.
음성언어 이해 기반 대화처리 기술의 경우, 언어 이해 및 사용자 의도 파악과 관련된 특허가 Nuance, AT&T를 중심으로 출원되고 있다. 대화시스템에서 사용자 의도 파악은 대화시스템의 성능을 결정하는 핵심 기술로서 대화처리와 연계된 언어 이해 및 의도 파악 기술 관련 특허가 특히 많다. 대화처리 기술 관련 특허는 대부분 제한된 도메인에서의 제한된 발화를 대상으로 하고 있으므로, 비정형 자유발화를 대상으로 하는 대화처리 및 언어이해 특허의 선점이 가능할 것으로 보인다.
사용자 발화 발음/문법 오류 교정 기술의 경우, 비교적 새로운 기술 분야로서 해당 기술을 지배하는 특허를 소유한 기업은 발견되지 않고 있다. 따라서 사용자 발화 발음/문법 오류 교정 분야의 특허 확보는 외국어 교육에 대한 관심이 증가하는 현 상황에서 향후 파급효과가 클 것으로 판단된다.
V. 발전방향
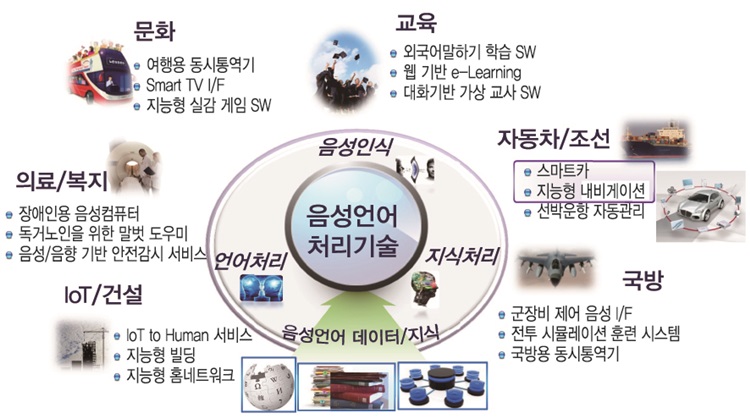
최근 스마트 단말 이용이 대중화됨에 따라, 기기 간 연결을 통한 정보를 소통하는 사물인터넷(Internet of Things: IoT) 산업에 대한 기대가 커지고 있으며, 사물인터넷과 인간이 소통하는 Internet of Things to Human(IoT2H) 기술의 핵심 원천기술인 자유발화형 음성대화처리 기술을 확보하는 방향으로 연구가 진행 및 가속화될 것이다. 또한, 자유발화형 음성대화처리 기술은 HCI의 핵심원천 기술로서, 가상 개인 도우미, 지능 로봇, 스마트 조언자, 대화형 정보서비스 등 유망 기술 및 서비스 분야에서 폭넓게 사용됨으로써 경제적 파급효과가 클 것으로 기대된다.
특히, 자유발화형 음성대화처리 핵심원천 기술을 영어, 한국어 등 언어교육 서비스에 접목함으로써, 영어, 한국어 등의 발음 교육에서부터 문법 및 표현 교육, 회화 연습 및 회화 실습에 이르는 다양한 언어 교육 서비스가 가능할 것이다. 또한, 국내 초중고교 영어 교육 과정에 활용함으로써, 부족한 원어민 교사 역할을 일부 대체 수행 할 수 있으며, 교육 보조 콘텐츠로 활용할 수 있다. 자유발화형 영어 학습 서비스는 일본, 중국, 동남아 등의 영어 발성 특성과 영어 교육 환경에 특화하여 외국어 교육 서비스 수출이 가능할 것이다. 자유발화형 한국어 학습 서비스는 다문화 가정과 국내 취업 외국인을 위한 한국어 교육 서비스에 활용 가능하고, 외국인들에게 한국어 보급 기회를 증가시켜 한류, 국제 교류 등의 활성화 및 한국어 위상을 제고할 것으로 기대된다. 또한, 장애우 및 아동 언어치료 교육과 접목하여 특수 언어치료 서비스로 확대할 수 있다.
Ⅵ. 결론
음성대화처리 기술의 핵심 기술들과 기술 분야별 국내외동향에 대해 간략히 살펴보았다. 기술 발전 및 음성대화처리 기술의 활용도를 높이기 위해, 인간 중심의 인터페이스가 되도록 자유로운 인간의 발화를 이해하고 처리하는 자유발화형 음성대화처리 기술을 확보하여야 한다. 자유발화형 음성대화처리 기술 선점이 미래 시장성 전망이 매우 큰 개인비서 SW, 사물인터넷의 IoT2H, 스마트카, 및 언어학습 SW 등에서의 최종 승자를 결정지을 것이다.
용어해설
비정형 자연어 음성인식 기술 화자, 환경, 어휘에 무관하게 누구나 자연스럽게 발성하여 머뭇거림, 반복, 자기수정 등의 다양한 비정형적인 요소를 포함하는 음성을 인식하는 기술
자유 대화처리 기술 사용자의 자유발화가 시스템 및 서비스 목적에 벗어나는 대화라도 이에 적절한 반응과 응답을 하면서 목적을 달성하도록 대화를 유도하는 기술
약어 정리
AIML
Artificial Intelligence Markup Language
CALL
Computer Assisted Language Learning
DB-CALL
Dialog based Computer-assisted Language Learning
DNN
Deep Neural Network
GMM
Gaussian Mixture Model
HCI
Human Computer Interaction
HMM
Hidden Markov Model
IoT
Internet of Things
IoT2H
Extreme Low-Energy
MFCC
Mel-Frequency Cepstral Coefficients
POMDP
Partially Observable Markov Decision Processes
SLU
Spoken Language Understanding
UI/UX
User Interface/User eXperience
S.S. Adkins, “The 2013-2018 The Worldwide Digital English Language Learning Market,” Ambient Insight Premium Report, Aug. 2014, http://www.ambientinsig ht.com/Resources/DocumentD/AmbientInsight-2013 -2018-Worldwide-Digital-English-Language-Learn ing-Market-Executive-Overview.pdf
J. Ajot and J. Fiscus, “The Rich Transcription 2009 Speech-To-Text(STT) and Speaker Attributed STT (SASTT) Results, ” Rich Transcription Evaluation Workshop, 2009, http://www.itl.nist.gov/iad/mig/tests /rt/2009/workshop/RT00-STT_SASTT-v1.pdf
A. Graves and N. Jaitly, “Towards End-to-End Speech Recognition with Recurrent Neural Networks,” Proc. 31st International Conference Machine Learning, 2014.
D. Povey et al, “The Kaldi Speech Recognition Toolkit,” IEEE Workshop Automatic Speech Recognition and Understanding, 2011.
G. Hinton et al., “Deep Neural Networks for Acoustic Modeling in Speech Recognition,” vol. 29, no. 6, Nov. 2012, pp. 82-97.
Y. Miao, “Kaldi+PDNN: Building DNN-based ASR Systems with Kaldi and PDNN,” CoRR abs/1401.6984, 2014.
D. Bohus and A.I. Rudnicky, “The RavenClaw Dialog Management Framework: Architecture and Systems,” Computer Speech & Language, vol. 23, no. 3, July 2009, pp. 332-361.
F. García et al., “An Active Learning Approach for Statistical Spoken Language Understanding,” LNCS, vol. 7042, 2011, pp. 565-572.
T. Kawahara, “New Perspectives on Spoken Language Understanding: Does Machine Need to Fully Understand Speech?,” IEEE Workshop on Automatic Speech Recognition & Understanding, 2009, pp. 46-50.
A. Celikyilmaz, D. Hakkani-Tur, and R. Sarikaya, “Semi-Supervised Semantic Tagging for Conversational Understanding Using Markov Topic Regression,” Proc. 51th Annual Meeting ACL, Aug. 2013, pp. 914-923.
G. Tur et al., “Towards Deeper Understanding Deep Convex Networks for Semantic Utterance Classification,”IEEE ICASSP, Mar. 2012.
R. Sarikaya, G.E. Hinton, and A. Deoras, “Application of Deep Belief Networks for Natural Language Un-derstanding,” IEEE Transactions on Audio, Speech and Language Processing, 2014.
K.A. Papineni, S. Roukos, and R.T. Ward, “Free-Flow Dialog Management Using Forms,” Proc. Eurospeech, Sept. 1999, pp. 1411-1414.
J.D. Williams and S. Young, “Partially Observable Markov Decision Processing for Spoken Dialog Systems,” Computer Speech and Language, vol. 21, no.2, Apr. 2007, pp. 393-422.
M. Henderson, B. Thomson, and S. Young, “Deep Neural Network Approach for the Dialog State Tracking Challenge,” Proc. SIGDIAL, 2013, pp. 467-471.
O. Pietquin et al., “Sample Efficient Batch Reinforcement Learning for Dialogue Management Optimization,”ACM Transaction on Speech and Language Processing, vol. 7, no 3, 2011, pp. 1-21.
S. Young et al., “POMDP-based Statistical Spoken Dialog Systems: A Review,”Proc. IEEE,vol. 101, no. 5, 2013, pp. 1160–1179.
B.A. Shawar, “A Corpus Based Approach to Generalising a Chatbot System,” University of Leeds School of Computing, Apr. 2005.
N. Matter and I. Wachsmuth, “Let’s Personal Assessing the Impact of Personal Information in Human-Agent Conversations,” Bell Syst. Tech. J., vol. 8511, 2014, pp. 450-461.
Y. Kim et al., “Acquisition and Use of Long-Term Memory for Personalized Dialog Systems,” MA3HMI Workshop, 2014, pp. 78-87.
M. Schulze and T. Heift, “Intelligent CALL,” Contemporary Computer-Assisted Language Learning, Chapter 13, 2013, pp. 249-265.
S. Hundsberger, “Foreign Language Learning in Second Life and the Implications for Resource Provision in Academic Libraries,” ARCADIA project, June 2009.
SIG ICALL of CALICO, “Intelligent Computer-Assisted Language Learning,” http://purl.org/calico/ic all
A. Hjalmarsson, P. Wik, and J. Brusk, “Dealing with DEAL: a Dialogue System for Conversation Training,” Proc. 8th SIGdial Workshop Discourse and Dialogue, 2007, pp. 132-135.


- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.