자동차 비전 프로세서 동향
Trend of Vehicle Vision Processor
- 저자
- 한진호, 변경진, 엄낙웅 / 멀티미디어프로세서연구실
- 권호
- 30권 4호 (통권 154)
- 논문구분
- SW·콘텐츠 기술동향 특집
- 페이지
- 102-109
- 발행일자
- 2015.08.01
- DOI
- 10.22648/ETRI.2015.J.300411
- 초록
- 자동차 분야에서 운전자의 안전 및 안전한 운전을 위해 비전 시스템에 기반한 Advanced Driver Assistant System(ADAS)을 개발하고 있고 비전 시스템을 이용한 물체인식 기술을 이용해서 차선인식, 보행자인식, 차량인식 등 통해 차량위치 및 추돌위험 등을 감지하기 위해 자동차 수준에서 필요로 하는 물체인식 기술 요구조건은 날로 증가하고 있다. 이를 지원하기 위한 Vehicle Vision Processor 또한 발전을 해오고 있고 초기에 50GOPS의 연산능력에서 약 400GOPS에 가까운 연산능력으로 720p 이미지 크기에 대해서 30fps Frame Rate로 처리할 수 있는 등 지금까지의 vehicle vision system을 위한 vision 연산기능이 강화된 vision processor 동향에 대해서 살펴보겠다.
Share
I. 머리말
인간이 어떤 방식으로 감각기관으로부터 정보를 습득하고, 저장하고, 활용하는가에 관한 탐구는 인간의 인지능력에 관한 연구에 있어서 가장 중요한 주제 중 하나이다. 컴퓨터 비전은 인간의 여러 감각 중에서도 가장 중요한 역할을 담당한다고 할 수 있는 시각적 인지능력에 대한 연구를 통해 궁극적으로 기계에도 인간과 유사한 인지능력을 심어주려는 공학적인 목표를 갖고 이러한 무제들에 접근하고 있는 학문분야이다. 이러한 컴퓨터 비전의 여러 분야 중에서도 물체인식은 컴퓨터 비전 제반 분야의 방법론을 한데 아울러 종합적인 결과를 산출해 내는 중추적 역할을 담당하는 분야라고 할 수 있다.
컴퓨터 비전에서의 물체인식이란 (그림 1)과 같이 여러 가지 모델 물체들에 대한 데이터베이스를 갖고 이는 한 시스템에 임의의 영상이 들어 왔을 때, 입력영상과 모델 데이터베이스 간의 정합과정을 거쳐서, 입력영상 안에 포함 되어 있는 물체와 가장 유사하다고 판단되는 모델 물체를 데이터베이스로부터 검색해 내거나, 또는 입력영상에서 목표 물체의 위치를 찾아내는 일련의 과정을 말한다.
이와 같은 물체인식은 쉬운 물체처럼 보일 수 있지만, 같은 물체라고 하더라도 개개의 영상 안에서는 물체의 크기, 방향, 위치, 포즈 등이 다르게 나타날 수 있고 또한 한 영상 내에 여러 개의 물체가 포함되어 있거나, 목표 물체가 다른 물체에 의해 가려져 그 일부분만 볼 수 있는 경우도 발생하기 때문에, 이러한 모든 조건하에서도 강인하게 동작하는 물체인식 시스템을 만드는 일은 쉽지 않은 문제이다. 따라서 그동안 물체인식 기법에 대한 많은 연구가 진행되어 왔고 현재에도 여러 가지 접근방법이 활발하게 모색되고 있다.
여기서는 Advanced Driver Assistance System(ADAS)에서의 Vision System에 대해서 알아보고 이를 위해 발표된 Vision Processor에 대해서 요약하겠다. 그리고, 향후 Vision Processor의 발전방향에 대해서 요약하겠다.
II. ADAS를 위한 Vision System
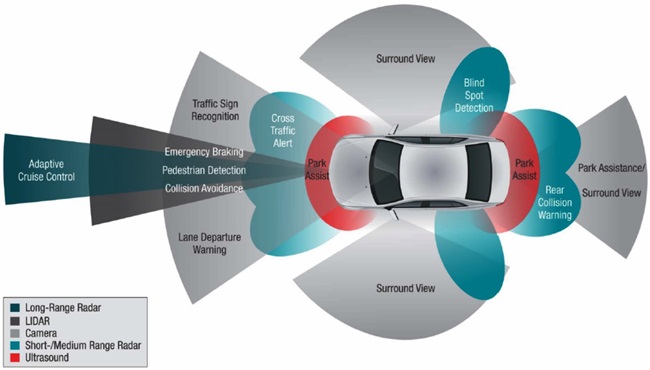
차량에서는 ADAS에서 이러한 물체인식 기술 이용하여 운전환경을 자동화하고 안전한 운전이 되도록 하고 있다. (그림 2)는 ADAS를 위한 센서, 알고리즘, 액추에이터에 대한 요구사항 을 보이고 있다. 운전자를 보조하기 위해서는 주행환경을 파악해야 하며, 현 차량의 위치, 속도 등의 차량거동정보를 알 수 있어야 하고, V2X 통신, Navigation System을 통해 도로 정보를 얻을 수 있어야 한다. 그리고 운전자의 상태를 파악하여 필요한 도움이 무엇인지를 파악할 수 있어야 할 것이다. 그리고, 알고리즘을 통해 이러한 센서 정보로부터 필요한 행동을 계산해야 할 것이며 엑추에이터를 통해 차량을 제어하거나 V2X 통신을 통해 현 차량을 상황을 Broadcast를 한다든지, 운전자를 환기시키는 기능을 해야 할 것이다.

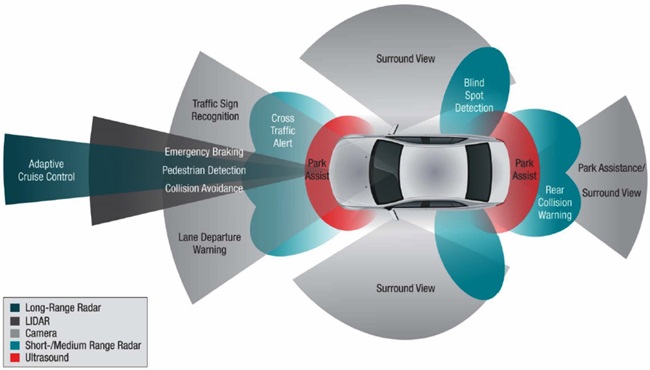
이러한 환경에서 (그림 3)과 같은 ADAS 센서 중에서 Vision System은 운전자 인식센서 또는 차량거동, 주행환경 파악 등 넓은 분야에 활용할 수 있기에 ADAS에 많은 적용이 가능하다.
이를 위해 CIS 등을 통한 Vision Sensor와 전자적으로 제어가 가능한 Actuator의 발전과 함께 알고리즘을 수행하기 위한 Vision Processor 또한 연구되고 있다. Vision 처리를 위해서는 많은 연산을 요구하고 있고 이에 단위 연산량(GOPS)을 높일 수 있는 아키텍처를 가지는 Vision Processor로 연구되고 있다.
다음 장에서는 자동차에 적용하기 위한 Vision Processor의 요구사항과 함께 현존하는 Vision Processor에 대해서 알아보겠다.
III. Vehicle Vision Processor
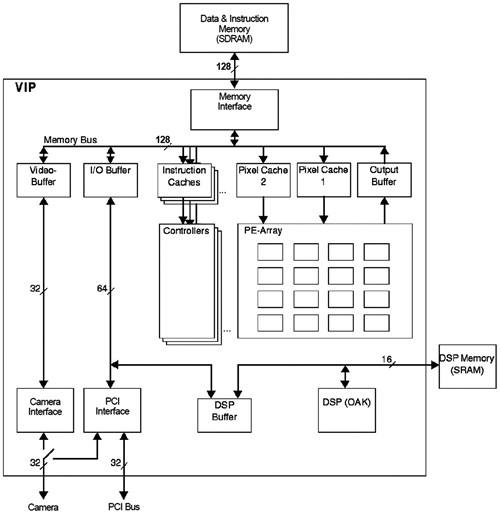
Vision 기반의 지능적인 운전제어를 위한 컴퓨터시스템 또는 운전자 지원을 위한 Intelligent Transport System(ITS) 응용분야에서는 물체인식기능을 위해 높은 연산성능뿐만이 아니라 전력 효율성과 Programmability를 요구하고 있다. Vision System은 높은 온도를 갖는 대기 안에 있는 Vehicle안에 위치한 안전하게 위치한 곳에 설치되어야 하기 때문에 전력 효율성은 System Reliability를 위해 요구가 된다. 자동차, 오토바이, 차선, 장애물 등과 같은 시간과 날씨에 영향을 받아 그 모습이 변화하는 물체를 인식하기 위해서는 다양하고 복잡한 Image Recognition Algorithm이 필요하게 되고 계속해서 개발되어야 하기에 Programmability는 또한 요구된다. 이러한 요구를 만족시키기 위해 많은 Execution Unit을 보유하고 있던 기존의 Array Processor 기반으로 시도하는 Infineon의 VIP Processor[2], 한 번의 명령어로 많은 연산을 수행하도록 하는 VLIW 명령어 기반 Processor로[3] 개발된 사례도 있다. 최근의 결과물에서는 앞에서 설명한 물체인식 단계별로 필요한 Application Specific Processor를 기반으로 하는 Heterogeneous Multicore Processor로[4][5] 한 많은 성능향상도 가져오고 있다.
이러한 시도를 통해 Vision Processor의 요구사항을 정리해 보고 이를 통해 앞으로의 Vision Processor의 발전방향을 정리해 본다.
1. Vision Instruction Processor
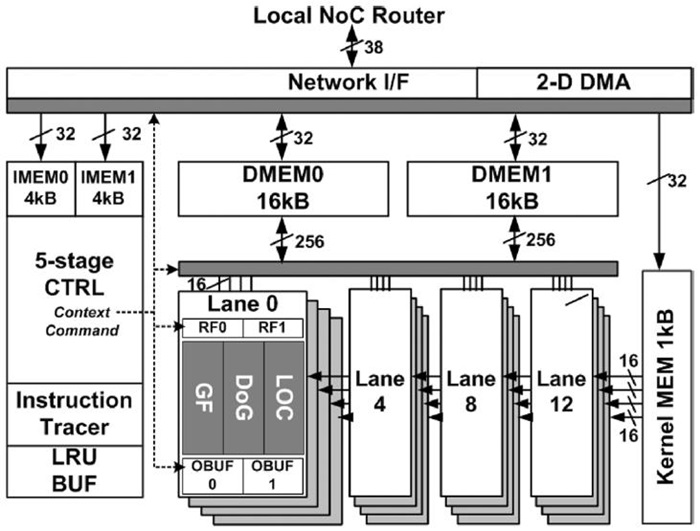
차량 및 차선인식을 가속하기 위해 개발된 Vision Instruction Processor는 53-GOPS Programmable Vision Processor이다. 약 205개의 Vision을 위한 Instruction을 지원하며 vector나 matrix 연산을 위해 16개의 Processing elements를 포함하고 있어 53-GOOPS 연산량을 실현할 수 있었다[(그림 4) 참조].
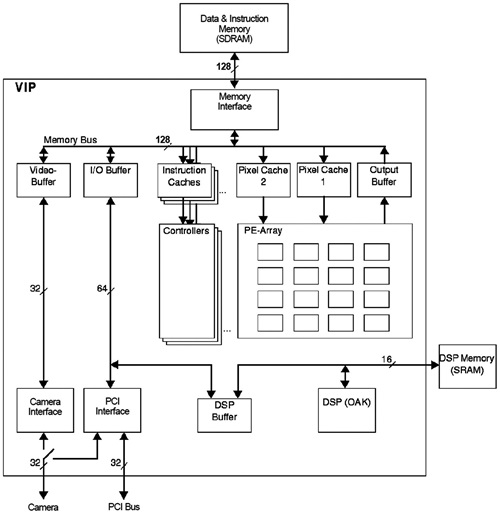
(그림 4)에서처럼 확장이 가능한 프로세서 아키텍처를 포함하고 있고, 많은 중간 영상처리 데이터를 저장하기 위한 물리적으로 분리된 온 칩 메모리, OAK DSP 코어 등으로 구성되어 있다.
가. 확장이 가능한 프로세서 아키텍처
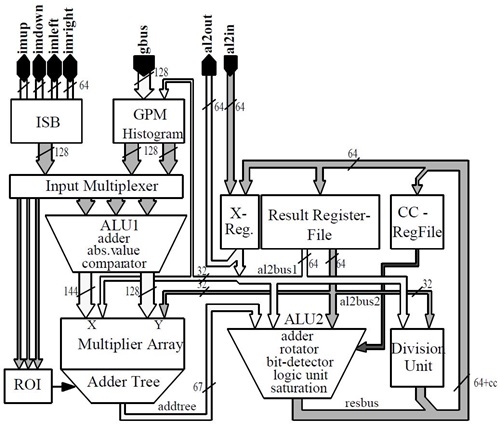
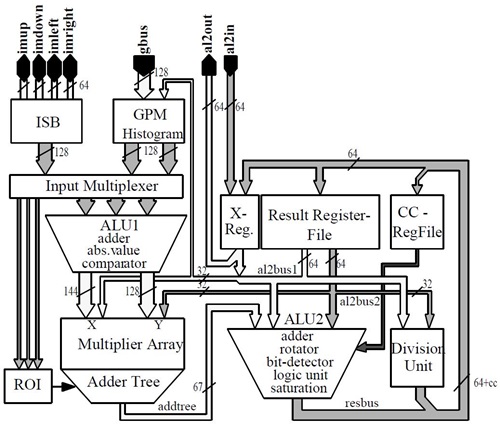
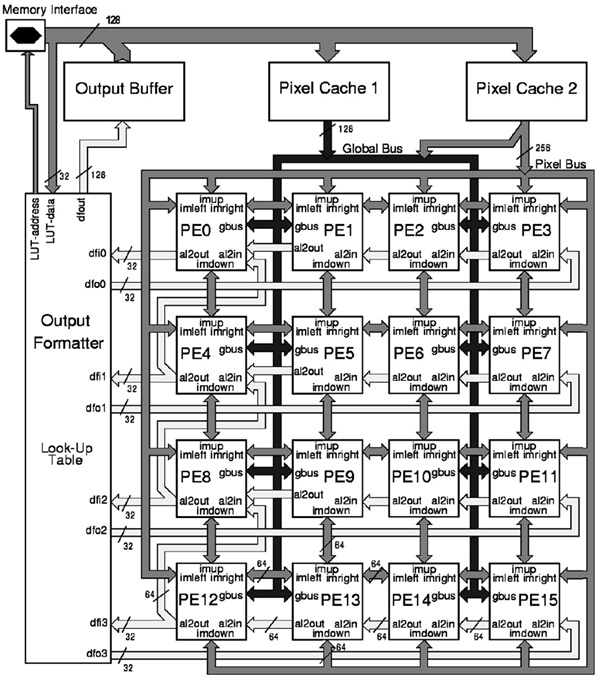
확장 가능 프로세서는 수평, 수직으로 Operand 전달이 가능한 16개의 PE로 구성된다[(그림 6) 참조]. (그림 5)에서와 같이 하나의 PE 내에서도 연산량을 극대화하기 위해 pipeline을 하는 벡터 및 매트릭스 연산 operation을 가속하는 ALU1과 표준 DSP의 execution unit의 기능을 담당하는 ALU2로 구성이 된다. ALU1은 8개의 16-bit 연산 또는 곱셈을 동시에 처리할 수 있다. 반면, ALU1은 1개의 64-bit 연산을 수행할 수 있어 32개의 64-bit register를 포함하고 있어 64-bit 데이터 연산을 한 번에 처리할 수 있는 능력도 있어 53-GOPS 연산량 위해 단위 PE 당 약 4GOPS 연산이 가능하도록 하고 있다.
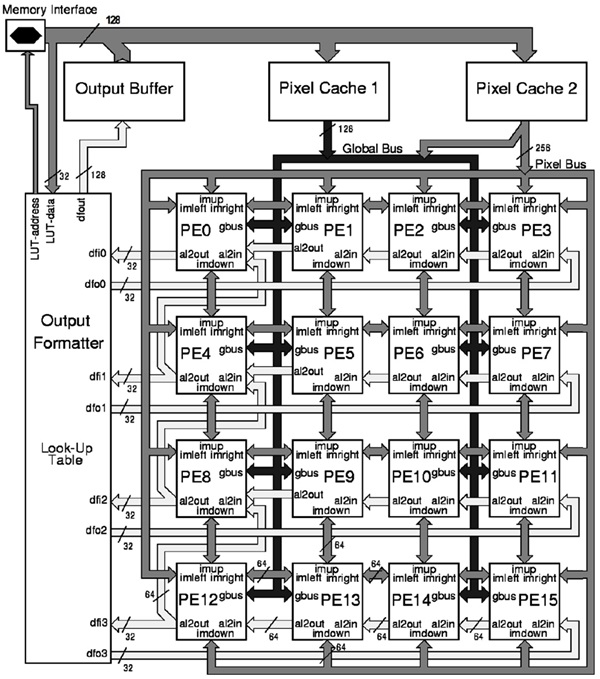
나. 내부 메모리 구조
Vision 처리에는 많은 Video data가 이동해야 한다. 이를 위해 VIP는 PE-local memory, global cache/ buffer, instruction/data memory로 사용되는 off-chip memory로 구성된 메모리 계층을 독특한 구성을 하고있다. 이러한 구성은 많은 알고리즘에서 data의 재사용을 촉진시키며 PE array가 요구하는 data 형태를 제공하기 위함이다. 이를 통해 많은 bandwidth를 줄이고 있어 성능저하를 없애고 있다. 기본적으로 이러한 메모리들은 다양한 2D data structure를 지원하고 있다. 우선, PE 내부에는 (그림 5)에서처럼 ISB는 register와 2D/1D shift 기능을 포함하고 있다. 8-bit, 16-bit, 32-bit, 2×2 and, 4×4 data를 제공할 수 있다. 또 하나의 GPM는 PE가 사용하는 2 read port와 off-chip memory가 사용하는 1 write port로 구성되어 있다. 또한, histo-gram mode는 8, 10, 12 histogram 저장할 수 있도록 하고 있다. SIMD PE array는 Output formatter와 Output Buffer가 있다. 이는 Off-chip Memory에 효율적으로 접근하도록 하며 MMU없이 간접 addressing도 지원을 한다. Video Input Data는 2개의 Pixel Cache를 통해 PE 내의 ISB와 GPM에 효율적으로 Data를 전달한다.
이러한 구조를 통해 동시에 ALU1는 32 operation을, ALU2는 1 operation을 수행하여 동작주파수 100MHz에서 51.2GOPS의 성능을 보여준다. 그리고, 제안 메모리 계층구조에 의해 24GB/sec peak 통신 대역폭을 실현하였다.
2. Video Recognition Processor
40µW에서 2003년도에 만들어진 NEC의 Video Recognition Processor는 2.4GHz General-purpose processor와 비교하여 1/20 전력소모를 하며 4배 더 좋은 성능인 51.2-GOPS의 계산능력을 보여주고 있다.
가. 외부 메모리 인터페이스
Video Recognition Processor는 EXTIF, CP, PE Array로 구성되어 있다. EXTIF는 SDRAM과 같은 외부 메모리 및 PCI, I2C, NEC CPU bus 등의 외부인터페이스 통신을 효율적으로 하도록 구성이 되어 있다. 즉, SDRAM Controller와 External bus interface를 효율적으로 지원하기 위한 Background data transfer control 및 Queue를 지원한다.
나. 제어 프로세서
Control Processor는 PE Array의 Operand 처리 및 제어를 담당한다. 16-bit RISC Processor로 총 6 stage pipeline을 한다. 이는 3 stage pipeline으로 되어 있는 PE array와 긴밀하게 통신을 한다. 주요기능은 ① PE Array에 Instruction 전달, ② Scalar 연산 수행, ③ PE array 상태 및 PE array 연산 결과를 scalar data 형태로 수집 기능을 한다. 이러한 통신은 BC1, BC2, RDU 등과 같은 명령어를 통해서 이루어 진다[(그림 7) 참조].
다. 단위연산 프로세서 코어구조
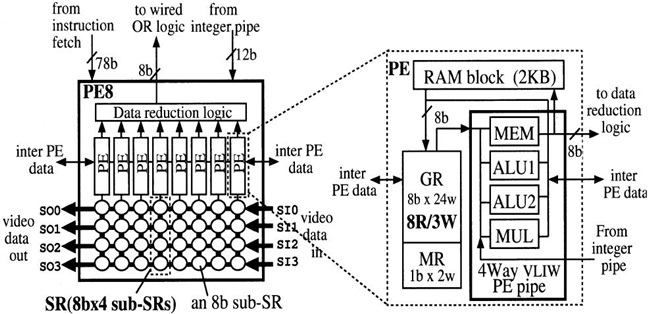
PE Array는 128개의 4 way VLIW 명령어를 처리할 수 있는 PE로 구성되어 있고 8개의 PE는 PE8을 구성하여 Data Reduction Logic를 공유한다. (그림 8)과 같이 하나의 PE당 4개의 8bit Shift Register(SR)가 병렬로 연결되어 있어 32개의 SR이 있고 다른 PE8과도 연결되어 있다. PE array와 SDRAM, 외부 Video Camera 및 PE 간의 효율적인 통신을 위해서 Inter-PE SR Path, Image SR Path, Video SR Path를 두고 있다.
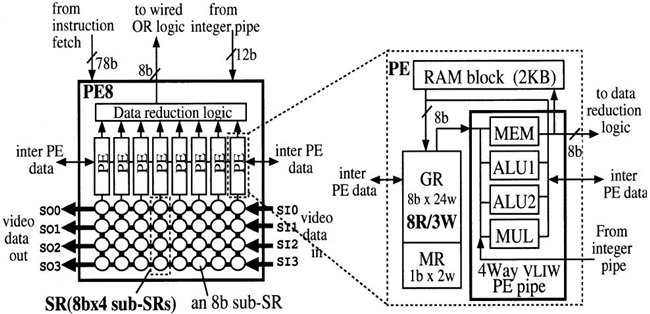
Inter-PE SR Path는 (그림 8)의 그림처럼 PE 내부에 있는 General Register(GR), Mask Register(MR)을 Shift Register로 구성을 하여 인근 PE의 GR, MR과의 통신이 자유롭도록 하였다. Image SR Path는 (그림 8)에서의 2K RAM block과 SDRAM 간의 통신 path로 Data reduction logic 내의 Line-buffer, (그림 7)에서의 EXTIF 내의 2개의 Priority Operation을 할 수 있는 Queue를 통해서 SDRAM과 128개의 2K RAM Block과 통신하도록 하고 있다. 캐시를 사용하지 않는다.
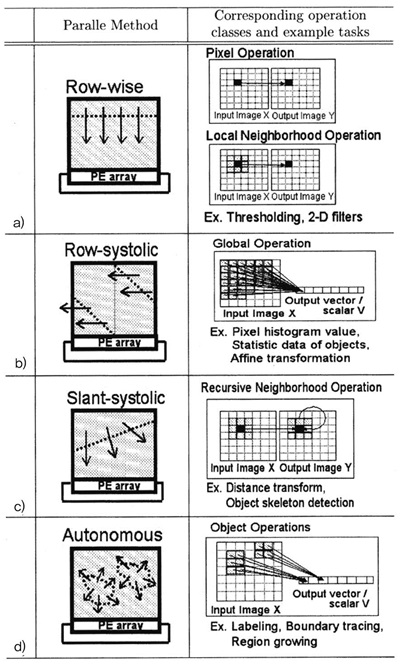
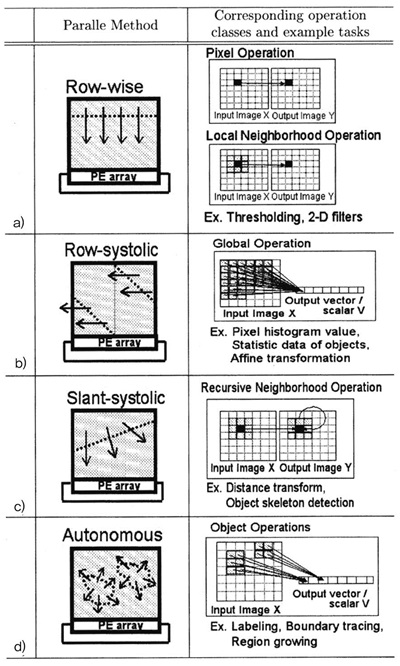
(그림 8)에서처럼 하나의 PE 내부에는 4-way Execution Unit과 4개의 8bit Shift Register, 2kbyte RAM 그리고, 24개의 8-bit General Register를 갖고 있다. 이는 8개씩 모여 PE8을 구성하고 있으며 PE8 내에는 32개의 8-bit SR를 이용하여 32개의 Operation을 수행할 수 있다. 그리고 16개의 PE8이 모여 512 Operation을 동시에 수행할 수 있다. 또한 Video/ Inter-PE SR Path는 Configuration 기능으로 Row/Column 방향으로 Shift도 지원을 한다. 이를 통해 128개의 PE는 (그림 9)와 같은 Row-wise, Row-systolic, Slant-systolic, Autonomous 등의 Parallel Mode를 지원하며 이를 통하여 Pixel/Local Neigh-borhood/Distance Transform, 2-D Filter Operation 등 물체인식에서의 기본 task들을 가속할 수 있다.
NEC의 이러한 Integrated Memory Array Processor for Car Electronics(IMAP-CE) 칩은 VLIW Compiler 기반의 1DC(one-dimensional C)라 불리는 Data Parallel Extended C language 및 이를 이용한 Image Processing Library를 지원하는 소프트웨어 개발환경도 함께 제공한다.
3. Context-aware Vision Processor
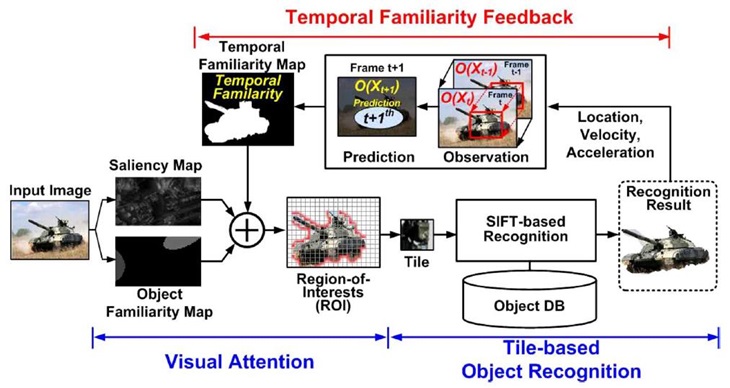
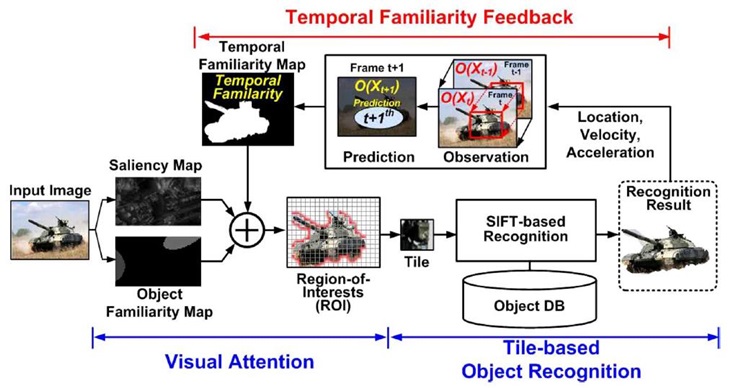
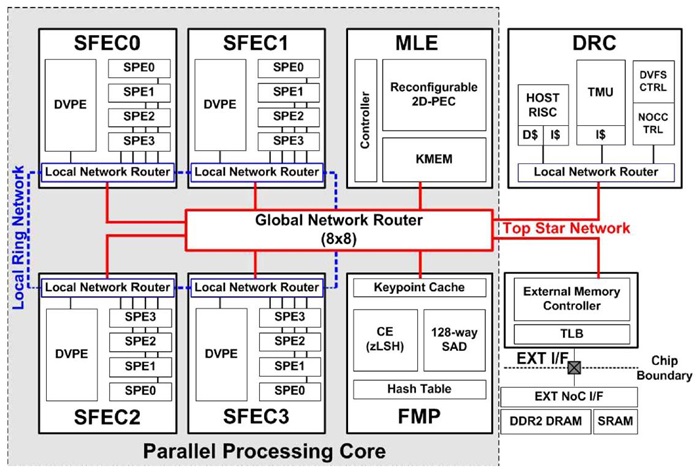
HD 720p Video Stream에서의 다이내믹 물체인식을 실시간으로 할 수 있는 342GOPS 성능의 Hetero-geneous multicore architecture 기반의 Object Recognition Processor를 개발하였다. 이는 Tile 기반의 SIFT 물체인식을 구현하였다. HD 720p라는 커진 영상크기에 따른 연산증가를 상쇄하기 위해 attention algorithm을 통해 Region-of-interest(ROI)를 찾아 연산해야 할 Tile의 수를 줄이고 있다. 또한, motion blur, illumination 그리고, occlusion과 같은 Dynamic Noise를 줄이기 위해 좀 더 정확하게 세밀한 ROI를 설정할 수 있도록 하였고 이를 위해 (그림 10)과 같은 Context-aware Visual Attention Model(CAVAM)을 제안하여 temporal뿐만이 아니라 spatial familiarity를 찾아 주도록 하였다. 이러한 노력은 기존의 HD video Stream를 처리할 수 있는 Object Recognition Processor에 비교해 16%의 전력효율성과 46%의 on-chip bandwidth를 감소시켜 Attention 정확도를 높이고 있다. 이러한 Object Recognition Processor의 구조는 (그림 11)과 같다. SIFT feature extraction operation을 위해 Simultaneous multithreading feature extraction cluster (SFEC), SIFT descriptor를 이용한 매칭 operation을 위해 Feature Matching Processor(FMP), CAVAM의 attention operation을 위한 Machine Learning Engine (MLE) 그리고, 전력소모 조절과 Heterogeneous core의 관리를 위한 Dynamic Resource Controller(DRC)로 구성이 되어 있다.
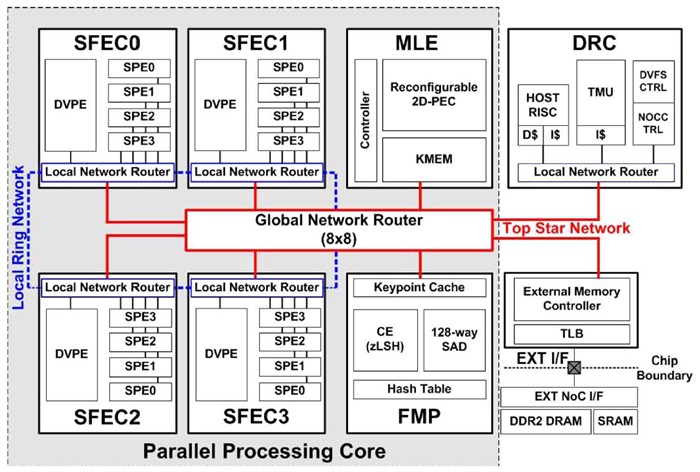
가. SFEC
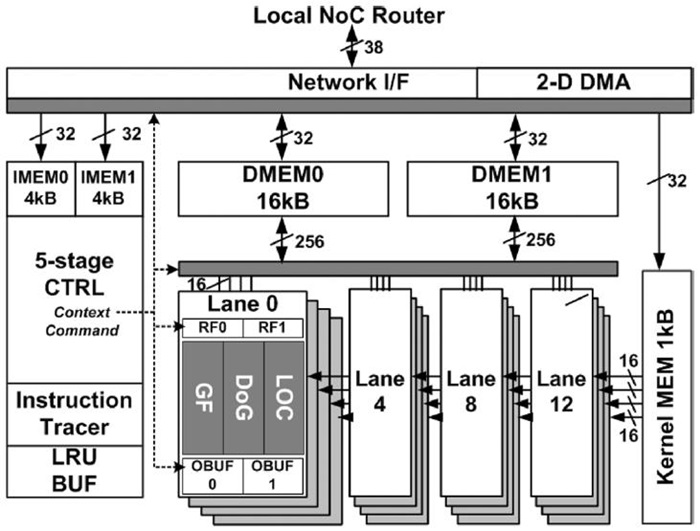
SFEC 안에는 하나의 Dual-threaded Vector Processing Element(PVPE)가 있다. 이는 16-way를 갖는 데이터 병렬처리를 할 수 있는 SIMD Processing Element가 있고, 4개의 Scalar Processing Elements (SPEs)로 구성이 되어 있다. 이는 모드 내부 NoC에 의해 통신을 하며 4개의 SPECs에 의한 Feature Extraction 수행 시 서로 간의 Ring 통신을 하게 된다[(그림 12) 참조].
나. FMP
그 이후에 바로 FMP는 매칭 operation을 수행을 하며 매칭 과정 중에 필요한 DB data와 추출된 SIFT feature descriptor는 NoC와 EXT I/F를 통해 최소의 clock 손실로 읽어 오게 된다.
다. MLE
이는 CAVAM의 Kaman Filter operation과 DRC의 서로 다른 처리정도를 갖는 Reinforcement learning 알고리즘을 가속하기 위한 것이다. 이는 ILP와 DLP를 제어 시 많이 찾아서 병렬화할 수 있도록 하였으며 ADD, SUB, MUL 그리고, SHIFT와 같은 SIMD 연산을 가속화하고 SIMD 연산을 위한 Cell은 ADRES[6], Montium Tile processor, XPP[7]와 같은 회로와 비슷하게 Reconfigurable이 되도록 하여 필요한 연산에 따라 계산식을 바꿀 수 있도록 하였다.
이러한 SoC는 50~200MHz까지 DVFS를 하며 3432 GOPS의 최대 성능과 함께 640GOPS/W와 10.69 GOPS/mm2의 성능을 나타낸다.
이러한 수치는 지금까지의 object recognition processor의 성능과 비교하여 2.54배 높은 수치이다.
IV. 맺음말
자동차 분야에서 운전자의 안전 및 안전한 운전을 위해서 물체인식 기술을 중요해지고 있다. 자동차 수준에서 필요로 하는 물체인식 기술 요구조건을 날로 증가하고 있어 이를 지원하기 위한 차량에 적합하게 연산능력을 높인 Vehicle Vision Processor 또한 발전을 해오고 있다. 살펴본 Vehicle Vision Processor는 50GOPS의 연산능력에서 약 700GOPS에 가까운 연산능력으로 720p 이미지 크기에 대해서 30fps Frame Rate로 처리를 하고 있고 낮은 전력을 소모하도록 개발되고 있다 최근에는 보행자인식, 전방차량인식, 차선인식 등을 하나의 카메라로 수행하는 Mobileye의 EyeQ2[8], nVidia의 GP-GPU를 이용한 Vision 처리를 하는 GPU, Toshiba에서 발표한 1.9 TOPS 연산능력이 있는 Heterogeneous multi-core 기반 Vision Processor[5]가 발표되고 있어 물체인식을 높이기 위한 고해상도의 영상크기를 지원하고 낮은 전력소모와 함께 앞으로는 좀 더 열악한 상황에서도 사람과 유사한 물체인식은 끊임없이 요구되고 있어 더 많은 연산능력을 요구할 것이다.
피사체뿐만이 아니라 Vehicle Vision Processor가 탑재되는 시스템 또한 Dynamic하게 움직이는 상황에서 Dynamic Error를 극복하고 물체인식을 할 수 있는 Vehicle Vision Processor가 요구되고 있다.
약어 정리
ADAS
Advanced Driver Assistant System
ALU
Arithmetic and Logic Unit
CAVAM
Content Aware Visual Attention Model
CP
Control Processor
DSP
Digital Signal Processor
DVFS
Dynamic Voltage Frequency Scale
GOPS
Giga Operations per seconds
GP-GPU
General Purpose Graphics Processing Unit
GPU
Graphics Processing Unit
ITS
Intelligent Transportation Systems
PE
Processing Element
RISC
Reduced Instruction Set Computer
SIMD
Single Instruction Multiple Data
V2X
Vehicle to Everything
VIP
Vision Instruction Processor
VLIW
Very Long Instruction Word
U. Ramacher et al., “A 53-GOPS Programmable Vision Processor for Processing, Coding-Decoding And Synthesizing Of Images,” European Solid-State Circuits Conf.,2001.
S. Kyo, et al., “A 51.2-GOPS Scalable Video Recognition Processor for Intelligent Cruise Control Based on a Linear Array of 128 Four-Way VLIW Processing Elements,” IEEE J. Solid-State Circuits, vol. 38, no. 11, Nov. 2003.
J.W. Oh et al., “A 320mW 342GOPS Real-Time Dynamic Object Recognition Processor for HD 720p Video Streams,” IEEE J. Solid-State Circuits, vol. 48, no. 1, Jan. 2013.
J. Tanabe et al., “A 1.9 TOPS and 564GOPS/W Heterogeneous Multicore SoC with Color-Based Object Classification Accelerator for Image-Recognition Applications,” Int. Solid-State Circuit Conf., Feb. 2015.
B. Mei et al., “ADRES: An Architecture with Tightly Coupled VLIW Processor and Coarse-Grained Reconfigurable Matrix,” Proc. Int. Conf. Field-Pro-grammable Logic Application, 2003, pp. 61-70.
P.M. Heysters, G.J.M. Smit, and E. Molenkamp, “Energy-Efficiency of MONTIUM Reconfigurable Tile Processor,” Proc. Int. Conf. Engineering of Reconfigurable Systems and Algorithm, 2004, pp. 38-44.

- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.