악성코드 대응을 위한 사이버게놈 기술동향
Cyber Genome Technology for Countering Malware
- 저자
- 김종현, 김현주, 김익균 / 네트워크보안연구실
- 권호
- 30권 5호 (통권 155)
- 논문구분
- 일반 논문
- 페이지
- 118-128
- 발행일자
- 2015.10.01
- DOI
- 10.22648/ETRI.2015.J.300513
- 초록
- 최근 인터넷을 기반으로 사이버상에서 개인정보 유출, 금융사기, Distributed Denial of Service(DDoS) 공격, Advanced Persistent Threat(APT) 공격 등 사이버 위협이 지속적으로 발생하고 있으며, 공격의 형태는 다양하지만 모든 공격에는 악성코드가 원인이 되고 있다. 또한, 기하급수적으로 증가하는 강력한 사이버 공격에 대처하기 위해 사전에 이를 방어할 수 있는 적극적인 방어 기술이 요구되고 있다. 본고에서는 사이버공격 대응을 위하여 새로운 악성코드 탐지기술로 최근 관심을 받고 있는 사이버게놈 기술에 대한 개념과 국내외 관련 기술 및 연구동향에 대하여 살펴본다.
Share
Ⅰ. 서론
종래의 사이버공격 탐지 및 차단기술은 해당 공격에 대한 시그니처를 탐지하여 차단하거나, 네트워크 단에서의 트래픽을 필터링하여 유해 트래픽을 차단하는 방법을 사용하였다. 시그니처 탐지기술은 이미 수집된 악성코드의 특징을 분석해 해당 악성코드를 탐지하는 시그니처를 생성하는 것을 말한다. 그러나 하루에도 수천, 수만 개의 악성코드가 생성됨으로써 공격자들이 만들어내는 신종 악성코드 수와 보안 업체들이 처리하는 시그니처 수의 격차는 좀처럼 좁혀 들지 않고 있으며, 오히려 그 간격이 점차 커지고 있는 것이 오늘날의 현실이다. 또한, 소스코드, 함수 등 악성코드의 내부 구조를 지속적으로 변화시켜 변종 악성코드를 만들어내는 기법이 활용되면서 백신을 우회하는 새로운 악성코드가 빠른 속도로 생성되고 있어 사이버공격을 탐지하고 차단하는 일은 더욱 어려워지고 있다.
따라서 주요 IT기반 시설의 정보시스템을 겨냥한 사이버테러 수준의 표적공격을 사전에 인지 및 통합분석하기 위하여 다중소스 데이터로부터 공격특징인자를 추출하고, 분석된 상황을 효율적으로 시각화하여 기업 내에 발생하는 보안 상황을 직관적으로 파악하는 것이 필수적이다.
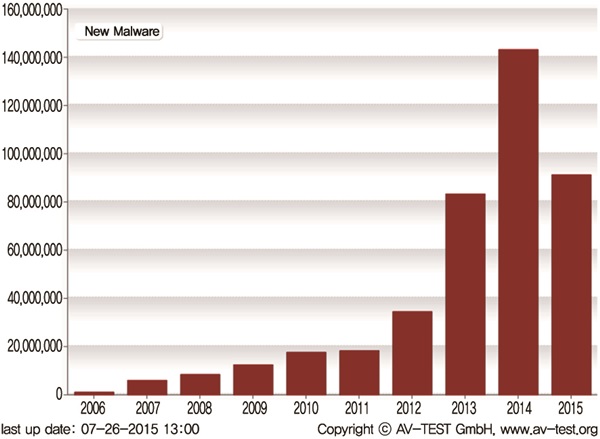
(그림 1)과 같이 최근 10년간 신규 악성코드가 지속적으로 증가되고 있고, 특히 최근 몇 년 사이 폭발적으로 증가되는 것을 볼 수 있다[1].
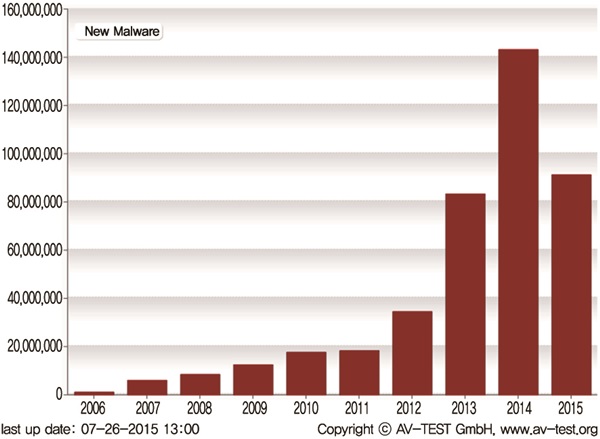
이렇듯 악성코드가 사이버 침해사고의 주요 원인이 되는 이유는 최근 악성코드는 분석을 어렵게 하기 위해 복잡해지고 정교해지고 있기 때문이다. 최근 지능화된 악성코드에 대해 효과적으로 대응하기 위한 다양한 탐지기술 및 분석 환경에 관한 연구가 이루어지고 있지만, 분석을 어렵게 하는 회피 기술 또한 지속적으로 정교해지고 있어 기존의 탐지기술 및 분석 환경으로는 악성코드를 효과적으로 식별하기에는 한계가 있다.
더불어 시그니처 수의 증가는 엔진 사이즈의 증가를 동반하고 있다. 또 엔진 사이즈가 커지고, 업데이트 빈도가 늘어남에 따라 업데이트 사이즈도 기하급수적으로 증가하고 있다. 이처럼 기존의 방식만으로는 악성코드의 위협으로부터 확실한 방어체계를 구축할 수 없는 상황에서 기존 악성코드 대응 방법을 보완할 수 있는 새로운 방식이 속속 소개되고 있다.
실제 사회에서 범죄가 발생했을 때 범인이 변장하거나 외양을 바꿀 수는 있어도 범인의 Deoxyribonucleic acid(DNA)는 변하지 않는 것과 마찬가지로 사이버상의 악성코드도 변하지 않는 고유의 행위 특징을 갖고 있다. 이러한 악성행위 특징을 추출하여 다수의 규칙으로 악성코드 유전체 DB를 구축하는 것이 사이버게놈 기술이다.
본고에서는 급증하는 신종 및 변종 악성코드를 탐지하고, 대응하기 위한 최근 관심을 받고있는 사이버게놈 기술과 관련된 국내외 기술동향을 소개하겠다. Ⅱ장에서는 악성코드를 대응하기 위한 기존의 탐지기술과 한계점을 살펴보고, Ⅲ장에서는 사이버게놈의 개념과 주요 기술을 설명하고, Ⅳ장에서는 악성코드 대응을 위한 사이버게놈 기술의 국내외 기술동향을 살펴본다. 마지막으로 Ⅴ장에서는 본고의 결론을 기술한다.
Ⅱ. 악성코드 대응 기술
1. 악성코드 탐지기법
악성코드를 탐지하고 분류하기 위한 분석 방법으로는 행위를 분석하는 동적분석 방법과 코드를 분석하는 정적분석 방법이 존재한다. 동적분석은 분석환경 내에서 악성코드를 실행시킴으로써 수행되는 악성 행위를 실시간으로 모니터링하고 추적하는 방법이다. 정적분석은 악성코드를 실행하지 않고 프로그램 구성 요소들의 연관성 및 호출 관계 등을 분석함으로써 악성코드의 구조와 삽입된 Dynamic Link Library(DLL) 등을 파악하는 방법이다. 특히, 정적분석은 특정 실행조건에 제한 없이 악성코드의 구조와 동작 특징을 분석하는 장점이 있지만, 분석기능을 자동화하기 어렵고, 실행코드의 암호화, 패킹(Packing) 등의 은닉기술이 적용된 경우 분석에 상당한 시간과 노력이 필요하다[2].
동적분석은 악성코드를 분석하기 위해 가상머신 환경 내에서 악성코드를 직접 실행시켜 프로세스 생성, 레지스트리 변경 등 악성코드의 행위를 기반으로 분석하는 방법이다. 동적분석은 행위정보를 기반으로 분석하기 때문에 신규 악성코드에 대한 탐지 가능성이 클 뿐만 아니라 사람의 개입 없이 자동분석 방식으로 구현할 수 있으며, 확인된 악성코드의 행위정보를 수집하는 데 사용된다. 대표적인 동적분석 툴인 Cuckoo Sandbox에서 악성코드를 실행시키면, 실행대상 파일시스템에 어떠한 영향을 주는지를 네트워크, 파일시스템, 레지스트리, 프로세스, 서비스 등의 항목으로 구분하여 확인할 수 있다.
동적분석 환경은 분석을 위한 가상환경을 복수로 구성하여 동시에 여러 개의 악성코드를 분석할 수 있어 분석시간을 단축할 수 있으나, 악성코드가 분석환경을 인지하여 회피(실행중단)할 수 있다는 단점이 있다[3]. 최근 연구에 따르면, 매일 새롭게 발견되는 악성코드의 수와 종류는 지속적으로 증가하고 있으며, 이는 기존의 악성코드와 자동 제작 도구를 이용하여 신종 및 변종을 쉽게 만들 수 있기 때문이다. 이러한 악성코드의 감염에 의한 사용자 피해 역시 급속도로 증가하고 있어서 악성코드에 대한 더욱 신속한 대응이 절실히 요구되고 있고, 이를 효과적으로 분석하기 위해 최근 동적분석에 대한 연구가 중요한 이슈가 되고 있다[4].
2. 기존 악성코드 분석기술의 한계
악성코드들은 스팸메일 발송, 개인정보 탈취, 감염 시스템 손상, 서비스 방해 공격(Distributed Denial of Service: DDoS) 등의 목적으로 다양한 전파방식을 통하여 네트워크 전역으로 퍼져나가고, 보안이 취약한 시스템을 감염시킨다. 이후 악성코드들은 감염사실을 숨기기 위하여 루트킷과 같은 다양한 분석 방해 및 은닉 기법을 사용하여 감염 시스템에서의 잔존 시간을 늘려 더욱 많은 정보를 외부로 유출한다. 대표적인 분석 방해 기법으로는 악성코드는 자신의 프로세스 정보를 숨기거나 커널 레벨 구조체의 정보를 수정하는 방식 등을 사용하여 악성코드의 프로세스 정보를 숨기는 방식이다. 악성코드 분석을 회피(은닉화)하는 기술로는 다음과 같은 기술 등이 존재한다.
가. 난독화(Obfuscation)
코드 난독화란 프로그램 코드의 일부 또는 전체를 변경하는 방법의 하나로, 프로그래밍 언어로 작성된 코드에 대해 가독성을 떨어뜨려 읽기 어렵게 만드는 작업을 말한다. 일반적으로 소프트웨어를 분석하려는 역공학에 대한 대비책으로 프로그램에서 사용되는 알고리즘이나 아이디어를 숨기기 위해 사용된다.
나. 패킹(Packing)
패킹이란 Portable executable(PE)형식으로 배포되는 프로그램들을 프로그래머가 자신의 프로그램이 리버싱이 되기 어렵게 하거나, 프로그램 용량을 줄이기 위해 사용하는 방식을 말한다. 만약 악성코드를 패킹할 때 알려지지 않은 방식으로 패킹하거나 여러 패킹방식을 복합적으로 사용하여 다중 패킹할 경우, 악성코드 정적분석기술을 우회하거나 어렵게 만들 수 있다.
다. 안티 디버깅(Anti Debugging)
악성코드를 분석하는 방식으로는 디버깅이 오랫동안 사용되고 있다. 악성코드들은 백신 프로그램이 자신을 분석하는 것을 방해하기 위해서 디버깅이 수행되지 못하도록 디버깅이 실행될 때 이를 탐지하여 다른 행위를 하거나 디버거의 실행을 종료시키는 등 다양한 방식을 사용할 수 있다[5].
라. 안티 가상화(Anti Virtualization)
안티 가상화는 악성코드 분석기법의 하나인 가상머신 환경에서의 악성코드 분석기술을 우회하는 방식이다. 안티 가상화는 가상머신 환경을 구축함으로써 나타나는 특징을 탐색하여 악성코드가 수행할 시스템이 가상머신 환경인지 판단할 수 있다. 가상머신 환경을 탐지하는 방법은 프로세스, 파일시스템, 레지스트리 요소탐지와 메모리 요소탐지, 가상 하드웨어 주변장치를 탐지하는 방법이 있다[5].
마. 스케줄링(Scheduling)
악성코드의 유포지를 탐지하는 방법은 클라이언트 허니팟(Client Honeypot)과 크롤러(Crawler)와 같은 자동화된 악성코드 탐지기술이 있다. 하지만 클라이언트 허니팟과 웹 크롤러와 같은 자동적으로 웹사이트를 방문하여 악성코드 감염 여부를 판단하는 기술들은 검사하는 웹사이트에 특정시간 동안 머물러야 하는 단점이 있다. 이런 단점을 이용하는 스케줄링 기반의 악성코드가 존재한다. 일명 시한폭탄(Time-bomb) 악성코드라고 하며, 자동화된 악성코드 탐지기술을 회피하기 위하여 웹사이트 방문 시 특정 시간 이후에 악성코드가 실행되게 하여 자동화된 악성코드 수집 프로그램을 우회할 수 있다.
바. 악성코드 대량 삽입
웹사이트에 악성코드가 삽입되는 경우는 대부분 Structured Query Language(SQL) 인젝션 취약점으로 인해 발생하게 된다. SQL 인젝션은 홈페이지와 데이터베이스가 상호 데이터 교환 시 데이터에 대한 검증을 수행하지 않아 공격자가 삽입한 SQL 명령어가 수행되면서 발생하는 문제점이다.
최근 공격자는 SQL 명령어를 특정 웹사이트에 대량으로 삽입하기 위하여 데이터베이스 문자형 칼럼의 자룟값 모두에 악성코드 유포지 Uniform Resource Locator(URL)를 삽입하여 대량의 악성코드를 유포하는 기술을 사용하고 있다.
사. 악성코드의 모듈화
과거 악성코드의 경우 다양한 악성행위를 수행하는 악성코드라도 모든 기능을 하나의 파일로 만들어 유포되었다. 하지만 최근 악성코드 유포자들은 악성행위 별로 악성코드들을 모듈화하여 유포하고 있다. 사용자가 악성코드에 감염되었을 시 해당 악성코드는 다른 기능을 수행하는 악성코드들을 다운로드하는 역할만을 수행한다. 이렇게 악성코드들을 기능별로 모듈화할 시 수행하는 기능을 제한하여 악성코드로 판단하는 기준을 충족하지 못하여 백신 프로그램을 회피할 수 있다. 과거 3.4 DDoS 공격 시 이러한 기법이 사용되었다.
아. 악성코드의 은닉화
악성코드를 은닉시키는 대표적인 기법은 루트킷이다. 루트킷은 다양한 방법을 통해서 시스템으로부터 악성코드를 은닉할 수 있으며, 대표적인 은닉화 기술은 Hooking, 시스템 프로그램의 변조, 커널 데이터 조작, 디바이스 드라이버 사용, 레지스터 변조, 콜백 함수 사용 등이 있다. 특히, 백신 프로그램 역시 시스템 서비스를 사용하기 때문에 루트킷을 탐지하기가 매우 어렵다.
이러한 기존 탐지기술의 한계점과 더불어, 기존 행위 기반 악성코드 탐지 시스템들은 단일 악성코드에 대한 행위 정보를 모니터링하고 있어 각 악성코드들의 유사도 및 해당 악성코드가 어떠한 악성코드의 변종인지 확인하는 데 어려움이 있다. 따라서 대용량 악성코드 분석을 통해 침해사고를 미연에 탐지하고, 해당 악성코드가 기존의 어떤 악성코드로부터 파생되었는지 분석하여 빠른 조치를 취할 수 있는 기술이 필요하다.
Ⅲ. 사이버게놈 기술
1. 인간게놈(Human Genome) 프로젝트
인간게놈 프로젝트(Human Genome Project: HGP)는 인간의 염색체 내에 있는 모든 염기서열(유전정보)을 밝혀내기 위한 연구 프로젝트이다[6].
게놈이란 생물체를 구성하고 기능을 발휘하게 하는 모든 유전정보를 보유한 유전자의 집합체로서, 인간의 경우 23쌍의 염색체를 말하며, 부모로부터 자손에 전해지는 유전물질의 단위체를 뜻하기도 한다. 이때 게놈에서 유전정보는 DNA라는 분자구조로 존재하며 4가지 화학적 암호인 A, G, T, C 등의 염기서열로 표기되어 있다. 인간게놈은 약 30억개의 염기로 구성되어 있다.
인간게놈 프로젝트란 바로 30억에 달하는 염기서열 전부를 해독하고자 하는 연구과제이며, 주요 목표는 10만여 개의 유전자 중 이미 알고 있는 유전자를 제외한 나머지 유전자들의 기능 및 특성을 알아내는 것이다. 또한, 이 유전자들이 23쌍의 염색체상에서 어느 위치에 존재하는지를 파악하는 것, 즉 유전자 지도를 완성하는 것이다. 특히, 이 유전자를 포함한 전체 DNA 염기서열을 결정함으로써 유전자의 구조적 특성과 게놈 전체의 구조적 본질을 밝히는 것도 목표 중 하나이다. 현재까지 인간게놈 프로젝트의 도움으로 많은 질병의 원인이 되는 유전자의 염색체상에서의 위치를 알게 되었다.
인간게놈 프로젝트와 유사하게 사이버보안 분야에서도 악성코드의 변종을 탐지하고, 악성코드를 제작하는 해커를 추적하는 사이버게놈 프로젝트를 진행 중이다. 자세한 사항은 다음 절에서 소개하겠다.
2. 사이버게놈(Cyber Genome)의 개념
사이버게놈이란 미 국방부 산하 고등방위연구계획국(Defense Advanced Research Projects Agency: DARPA)이 처음 만든 용어로 인간의 게놈(유전체)을 분석하듯 인터넷상의 악성코드를 분석해 공격의 배후를 파악하고 보안 사고를 미리 차단하는 고도의 보안기술을 뜻한다[7].
사이버게놈 기술은 은밀하게 심어진 악성코드 및 사이버공격 행위의 배후와 공격 경로를 밝히는 데 목적이 있다. 이를 위해 마치 인간의 염기서열을 분석하듯 수많은 악성코드의 특징과 코드를 상세히 분석한다. 그 후 이를 공격 특징별로 분류하면 추후 비슷한 사건이 발생했을 때 악성코드 제작자나 해킹그룹, 유포지, 공격지, 공격 목적 등을 빠르게 추정해 낼 수 있다. 특히 실시간으로 다양한 공격 기법과 인터넷 주소(IP)를 바꿔가며 공격하는 지능형 지속위협(Advanced Persistent Threat: APT) 공격의 사전 대응에도 활용될 수 있다.
이러한 사이버게놈 기술은 사이버공격을 예방하고 사전에 차단하기 위해 해커의 습성과 특징을 파악하고 앞으로 진행될 공격 방법과 경로 유추 및 해커의 행동을 실시간 분석할 수 있는 기술로서 사이버공격에 대한 효과적인 대응기술이 될 것이다. 다양한 악성코드 분석과 해킹 사건 분석을 통해 도출되는 해커의 아이디, 해킹 그룹 식별 능력이 있을 때, 분석 및 대응에 걸리는 시간을 절약하여 수많은 공격에 효과적으로 대응할 수 있을 뿐 아니라, 잠재적으로 발생 가능한 사이버테러에 대해 방어수단을 사전에 확보할 수 있게 된다.
3. 사이버게놈 분석의 주요 기술
사이버게놈 기술은 사이버공격에 대응하기 위하여 최근에 국내외적으로 연구가 진행되고 있는 악성코드 탐지기술로써, 일반적으로 악성코드 샘플을 확보한 후 데이터 마이닝 기법을 통하여 악성코드의 고유 행위패턴(유전체)을 찾게 된다. 사이버게놈 분석에서 사용되는 주요 기술들은 다음과 같다.
가. 악성코드 API 시퀀스 추출
Application Programming Interfaces(API)란 응용프로그램에서 시스템자원을 사용할 수 있도록 운영체제나 프로그래밍 언어가 제공하는 미리 정해진 메소드를 말한다. 응용프로그램은 시스템 자원을 사용하거나 다른 응용프로그램과 상호작용을 할 때 반드시 API를 호출해야 하며 프로그램 내부에서 호출되는 함수의 형태로 구현된다. 따라서 악성코드도 다양한 악성 행위를 수행하기 위해 API 호출을 사용한다.
한 가지 예로서 악성코드는 피해자의 컴퓨터에 추가 파일을 다운로드 하여 설치하고자 하는 경우, 네트워크 연결 행위와 파일 생성 행위에 관련된 connect(), recv(), createFile() 등의 API를 사용한다. 따라서 시스템 API 호출 시퀀스를 추출하여 악성코드의 실행 프로세스를 확인할 수 있다. 악성코드로부터 API리스트를 추출하는 방법으로는 바이너리 실행파일 자체에서 추출하는 방법과 프로그램 동작 중 호출되는 API를 후킹하는 방법이 있다. 바이너리 실행파일 자체에서 추출하는 방법은 PE파일 분석을 통해 Import Address Table(IAT)를 찾고 IAT로부터 포함된 API리스트를 추출하는 방법이다. API를 후킹하는 방법은 프로그램 작동 중 호출되는 인터럽트를 후킹하여 호출되는 API를 기록하는 방법인데 주로 Native API에 대한 정보를 얻기 위해 사용된다. 이러한 커널 후킹을 이용한 방법에는 System Service Descriptor Table(SSDT) 후킹이나 Interrupt Descriptor Table(IDT) 후킹 등이 있다[8].
나. API 기반의 악성코드 특성인자 추출
일반적으로 애플리케이션은 프로그램 로딩 시 고유한 시스템 API호출을 수행한다. 공격자는 시스템 메모리에 악성코드를 로드하는 순간 IAT를 변경하여 공격자가 의도하는 시스템 API를 호출하게 하고, 기존의 정상적인 API의 흐름을 그대로 유지시킨다. 이와 같은 악성코드를 탐지하기 위해 정상적인 실행 파일의 로딩 시에 호출되는 시스템 API 호출을 프로세스, 메모리, 레지스트리, 파일, 스레드, 네트워크, 서비스 영역 등으로 분류하고, 악성코드가 아닌 정상적인 프로그램으로부터 자주 포함되는 API의 리스트를 DLL 별로 저장하여 화이트리스트(White List)를 생성한다. 그리고 악성코드 샘플을 실행한 후 추출된 API 리스트에서 화이트리스트의 API를 제거하게 되면 악성코드만이 갖는 고유 특성인자를 추출하게 된다. 또한, 악성코드가 실행되면서 호출하는 주요 API리스트를 알파벳 또는 특정 디지털 문자열로 치환하는 과정이 필요하다. 이런 과정은 Bioinformatics 분야에서 사용되는 서열 정렬 툴(ClustalX, MAFFT, MUSCLE, JalView)을 사용하기 위해서도 필요하며, 이후 Bioinformatics 분야에서 사용하는 DNA 시퀀스 정렬 방법을 사용하여 악성코드에 대한 그룹별 유사도 값을 측정할 수도 있다.
다. 서열 정렬(Sequence Alignment)
서열 정렬(sequence alignment)은 일반적으로 Bio-informatics 분야에서 두 개 혹은 그 이상의 서열들의 유사도 값을 측정하거나 유사 구간의 관계성을 찾기 위해 사용되는 기법이다. 특히, 두 문자열에 포함된 각 문자에 대하여 하나씩 비교하여 일치하는 부분이 가장 많아지도록 문자열을 정렬하는 것이 서열 정렬 기법의 목적이다[9].
서열 정렬 알고리즘은 다음과 같은 과정을 수행한다. 문자열 x, y에 대하여 각 길이를 m, n으로 정의한다. 이때 아래 수식과 같이 행렬 M을 정의할 수 있다. 행렬 M의 각 원소는 아래의 4가지 경우 중 최대의 값을 가진다.
s(xi,yj)는 xi,yj가 같을 때 2, 다를 때 -1이다. Wk는 정렬을 수행하는 데 있어 각각의 문자열에 공백(gap)을 삽입하여 서로 대응되는 문자 간의 유사도 합이 최대가 되는 조합을 찾는 경우에 적용되는 값이다.
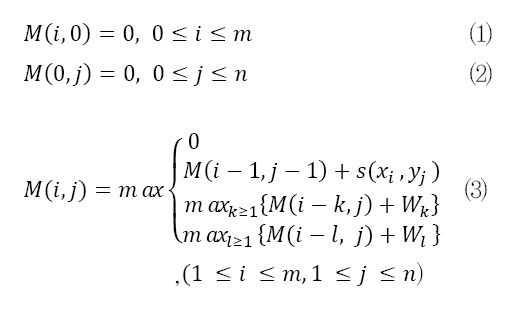
만약 x, y를 각각 ‘ABCDE’, ‘BBFCD’라고 가정하면, 두 문자열의 정렬된 최종 결과는 행렬 M의 최댓값을 갖는 원소를 기준점으로 하여, 대각선과 가로, 세로 방향 중 한 방향을 선택하여 역으로 진행하면 얻을 수 있다. 만약 값이 같을 경우, 대각선 방향이 우선시 되며 가로, 세로 방향은 동일한 순위를 가진다. 최종적으로 값이 0인 원소에 도달할 때까지 진행하면서 경로를 형성한다. 경로가 형성되면 형성할 때의 반대 순서로 진행하여 실제 정렬을 수행한다. 이렇게 수행된 정렬 결과는 아래와 같다.
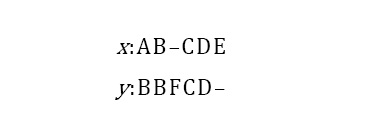
서열 정렬 알고리즘은 보통 두 가지 방식으로 나뉜다. 먼저 두 문자열의 길이가 다르거나, 대체로 다른 문자열을 정렬할 경우 두 문자열의 공통된 부분을 찾는 국소 정렬(Local Alignment) 알고리즘이 있으며, 대표적인 알고리즘으로 Smith-Waterman 알고리즘이 있다[9]. 반대로 두 문자열의 길이가 비슷하고 전체적으로 비슷한 문자열을 정렬할 경우 전체적인 관점에서 두 문자열이 가장 유사하도록 하는 전역 정렬(Global Alignment) 알고리즘이 있으며, Needlman-Wunsch 알고리즘이 대표적이다[10]. 두 알고리즘은 정렬 과정은 동일하나, 경로 형성의 기준점에 차이가 있다. 일반적으로 변종 악성코드들의 API 호출 리스트의 종류와 길이가 대체로 다양해서 Global Alignment보다는 Local Alignment 알고리즘이 많이 적용되고 있다.
라. 악성코드 유사도 분석
일반적으로 Dynamic Programing(DP)은 DNA, Ribonucleic acid(RNA), 단백질 서열의 비교와 프로그래밍 소스 코드의 유사도 값을 측정할 때 널리 사용됐다. 최근 Bioinformatics분야에서 DP를 이용한 Pairwise Alignment와 Longest Common Subsequence(LCS) 알고리즘을 이용하여 두 서열 간의 유사도 분석을 하고 있으며, 사이버게놈 기술에서도 이와 유사한 접근 방법을 따르고 있다. LCS는 두 문자열에서 공통으로 존재하는 가장 긴 서열을 찾는 알고리즘이다[11].
두 문자열을 다음과 같이 정의한다.
X=(X1,X2…Xm), Y=(Y1,Y2…Yn) X의 부분서열은 X1,2…m이고, Y의 부분서열은 Y1,2…n이다. LCS(Xi,Yj)을 부분서열 Xi와 Yj의 최장 공통 부분서열을 대표한다고 하면, 이 서열의 집합은 다음과 같이 주어진다.
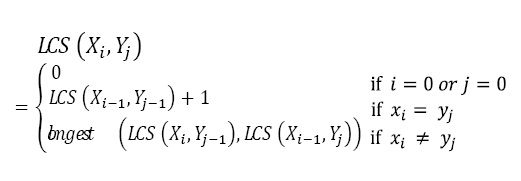
Xi와 Yj의 최장 공통 부분 서열을 찾기 위해서, 두 원소 xi와 yj을 비교한다. 만약 그들이 같다면 서열 LCS(Xi-1,Yj-1)는 xi원소로 확장되고, 만약 그들이 같지 않다면 두 서열 LCS(Xi,Yj-1) 와 LCS(Xi-1,Yj) 중 더 긴 것이 얻어진다.
Ⅳ. 국내외 기술 및 연구동향
본 절에서는 신종 악성코드 대응을 위한 사이버게놈프로젝트에 대한 국내외 기술 및 연구동향을 소개한다.
1. 국외 기술 및 연구동향
가. 산업계의 기술동향
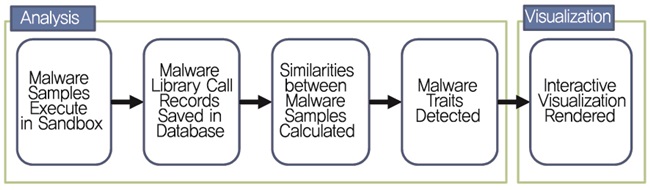
Invincea사에서 사이버게놈 프로젝트의 일환으로 Cynomix라는 시스템을 개발 중이다. 본 기술은 샌드박스에서 악성코드를 실행한 후 Process Monitor (PROCMON) 툴을 통하여 악성코드의 시스템 API 호출 로그를 추출한다. 그다음 단계로 의미 있는 API 서열을 추출하기 위하여 마코프 체인 알고리즘을 사용한다. 전반적인 시스템 동작 프로세스는 (그림 2)와 같다.
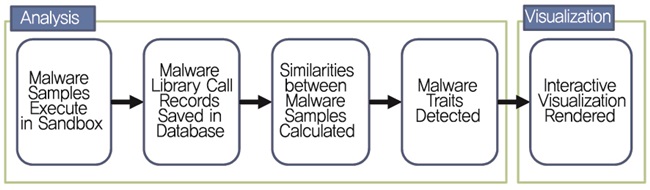
본 시스템은 (그림 3)과 같이 세 개의 패널로 구성된 시각화 기술을 포함하고 있으며, 악성코드 유사도 분석을 기반으로 하는 클러스터링 글로벌 뷰, 각각의 악성코드 API 서열을 표현해주는 뷰, 사용자에 의한 필터링 조건을 선택하는 뷰로 구성된다. 본 시스템은 대규모 악성코드 데이터 셋을 갖고 각각의 악성코드를 실행하기 위한 시스템 콜의 서열 관계를 분석하고 시각적으로 표현하는 시스템이다[12]. 즉, 악성코드 행위를 시스템 API 호출의 서열로 정의하고, 각 서열의 유사도 분석을 통하여 변종 및 신종 악성코드를 분류하고 있다.

나. 연구기관의 기술동향
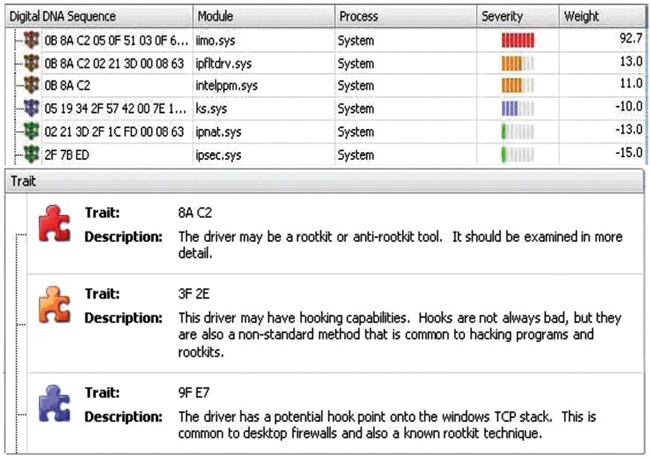
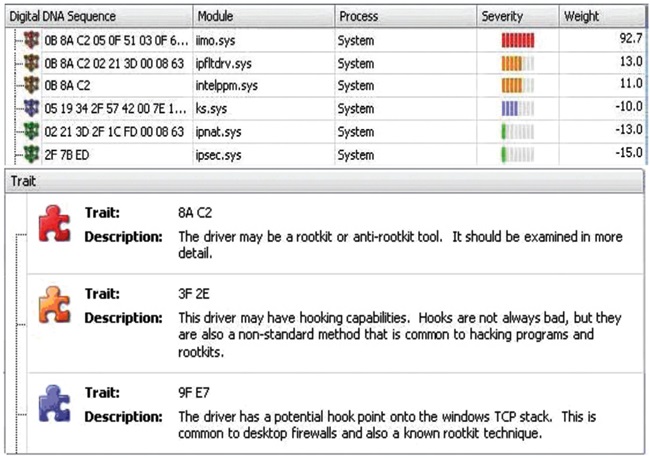
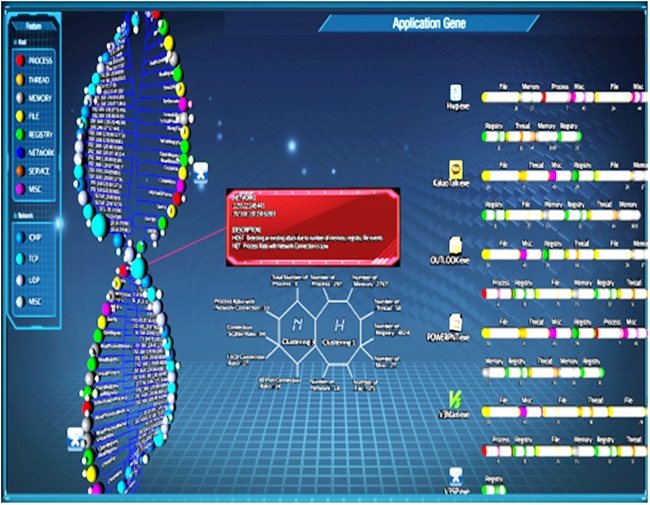
새로운 악성코드, 새로운 변형, 다형성 코드와 같은 지능화된 공격 기술의 발달은 기존 보안 시스템의 패턴기반 탐지 방식을 회피하고, 사용자들의 자산 보호에 위협을 주게 된다. 미국의 HBGary 연구소는 새로운 형식의 행위 기반 탐지기술로 Digital DNA 기술을 개발하게 되며, 이 기술은 시스템 메모리상에서 실행되는 프로세스의 행위를 분석하여 악성코드를 탐지하고 리포팅 한다. 또한, 정적분석과 동적분석을 통하여 프로세스 행위의 취약성을 발견하고, 해당 프로세스의 악성여부를 판단한 후 취약성 내용을 Digital DNA로 변환하는 작업을 한다[13].
(그림 4)는 HBGary연구소에서 개발한 Responder 제품에서 Digital DNA를 확인하는 화면이다. 본 제품은 메모리 분석을 통한 신종 및 변종 악성코드를 탐지하고, 프로세스가 사용 중인 DLL, SYS파일 등을 분석하며, 동작 중인 프로세스에 대한 Binary분석, String분석 등을 통해 악성코드 행위패턴을 추출하고, 분석한다.
다. 학계의 연구동향
산업계 및 연구기관 이외에도 학계에서도 사이버게놈 프로젝트를 진행 중에 있으며, Bioinformatics 공학에서 다루는 DNA분석기법을 악성코드 탐지기법에 적용하고 있다.
특히, 컴퓨터의 16진수 헥사 값을 DNA에서 표현하는 20가지의 아미노산의 문자열로 치환한 후 개별 악성코드 프로세스의 행위를 데이터 마이닝 기법을 적용하여 탐지하는 알고리즘이 소개되었다[14]. 또한, 다중 서열 정렬 기법을 사용하여 악성코드의 유사도 분석을 수행하고, 공격 특징별로 행위 패턴을 추출하는 프로세스도 설명하고 있다.
2. 국내 기술 및 연구동향
가. 산업계의 기술동향
국내의 경우, 안랩에서 개발한 룰 기반 악성코드 탐지기법은 인간의 DNA맵을 그리는 게놈 프로젝트와 같이 클라우드 센터가 보유하고 있는 악성/정상파일 DNA의 고유한 특징을 분류해 DNA맵을 구성한 후 DNA맵의 구성 중 악성코드만이 가지고 있는 특징들을 추출하고, 새로운 악성코드 진단 룰을 생성하여 신종 및 변종 악성코드를 진단하는 기술이다[15].
클라우드 컴퓨팅 개념을 도입한 악성코드 대응 기술의 경우, 기존에 사용자에게 일방적으로 악성코드 패턴 DB를 내려 검사/치료하는 방식이 아닌 사용자와 클라우드 센터 간 양방향 통신을 통해 악성 여부를 판단함으로써 새로이 나타난 악성코드의 전파 속도가 어떠한지, 어떤 악성코드에 가장 많이 감염되고 있는지 등의 악성코드 위협 상황을 쉽게 파악할 수 있는 장점이 있다.
나. 학계의 연구동향
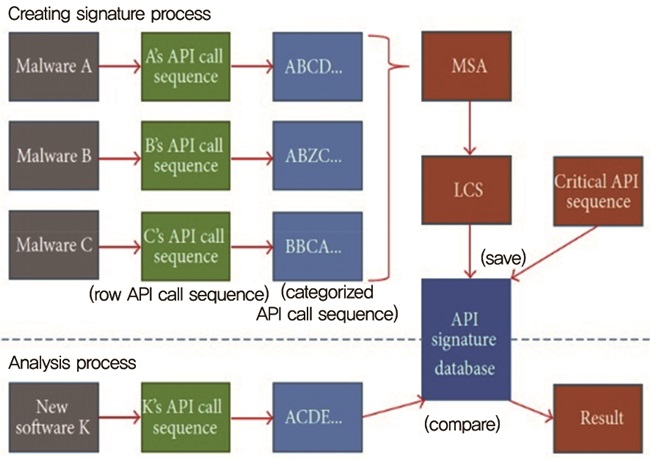
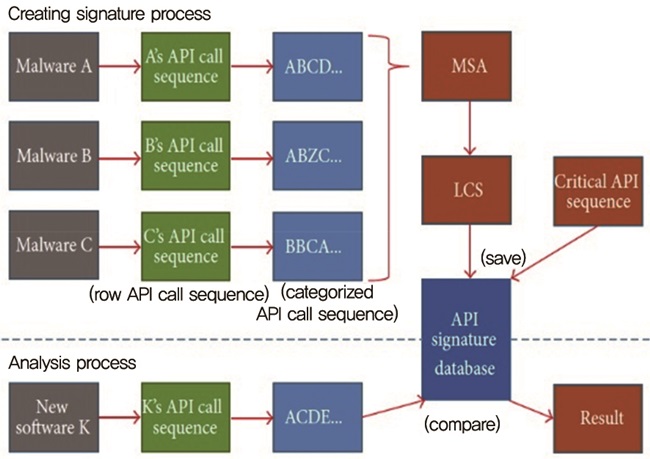
국내 모 대학에서는 시스템 API 호출 시퀀스를 분석하여 악성코드를 탐지하고, 유사도 분석을 수행하고 있다. 주요 내용은 수천 개의 악성코드 샘플을 확보한 후 가상화 머신 환경에서 각 악성코드를 실행시킨다. 이후 악성코드가 실행되면서 호출하는 시스템 API 리스트를 추출하고, 주요 시스템 API 호출 리스트를 알파벳 문자열로 치환한다. 그다음 단계로 Bioinfomatics 분야에서 널리 사용되는 ClustalX 툴을 통하여 API 서열 정렬을 수행하고, LCS 알고리즘을 이용하여 악성코드의 공통 행위 패턴을 추출한 후, 악성코드 패턴 DB에 저장한다. 마지막으로 시스템 검증을 위하여 의심되는 실행파일의 API 서열을 악성코드 패턴 DB에 조회하여 해당 실행파일의 악성여부를 판단한다. (그림 5)는 해당 기술의 전체 프로세스 구성을 나타내고 있다[16].
다. 연구기관의 기술동향
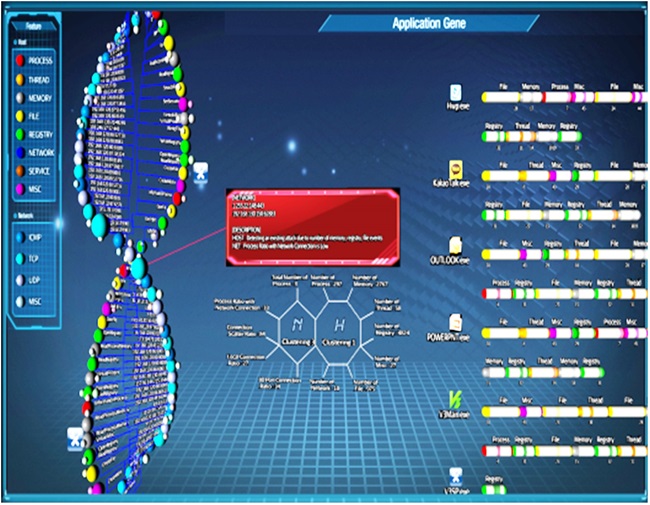
국내의 경우, ETRI에서는 단일 기업망 환경에서 일반 사용자 PC의 로그정보와 네트워크 트래픽 정보를 수집하고, 이를 기반으로 공격 특성인자를 추출한다. 추출된 특성인자들 간의 관계성을 DNA구조형태로 표현함으로써 사용자PC의 악성코드 감염여부를 보다 쉽고, 빠르게 식별할 수 있는 사이버 유전체 분석(Cyber Genetic Analysis: Cyber-Genesis) 기술을 개발 중이다. 또한, 빅데이터 플랫폼 기술을 활용하여 과거에 일어났던 사이버표적공격에 대한 공격특성 DNA 프로파일을 구축하고, 현재 감염된 PC의 공격특성 DNA와 유사도 분석을 수행함으로써 사이버표적공격의 세부 유형을 쉽게 탐지할 수도 있다.
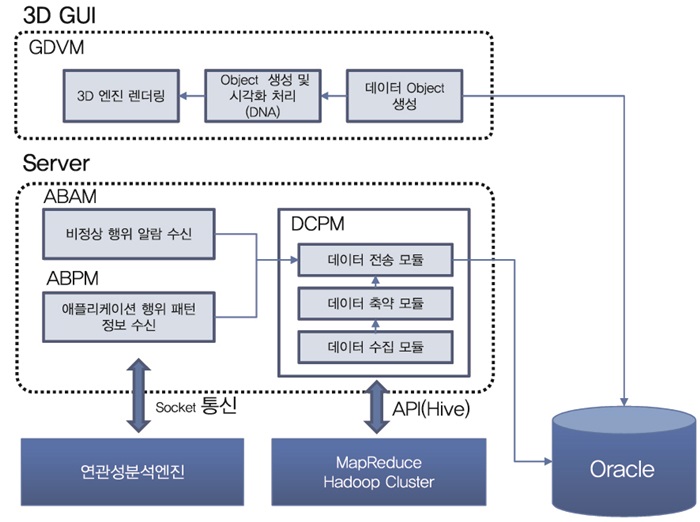
(그림 6)은 수집된 이벤트 로그로부터 고유의 공격특성 정보를 추출하고, 공격특성들 간의 관계성을 DNA구조형태로 표현하고, 시스템에서 실행 중인 프로세스의 API 호출 시퀀스를 분석하여 악성여부를 확인할 수 있는 Cyber-Genesis의 3D 시각화 화면이다.
(그림 7)은 악성코드 특성인자 DNA 추출 및 악성코드 유사도 분석을 수행하는 3D 시각화 엔진의 개략적인 기능 블록 구성도를 나타내고 있다. 데이터 처리 서버는 사용자PC, 서버, 네트워크 장비로부터 다양한 데이터를 수집하고 처리하는 데이터 처리 및 저장 기능, 수집된 데이터로부터 표적공격을 탐지하기 위한 악성코드 고유 패턴(DNA) 추출 기능, 비정상 행위 탐지경보와 연관성 분석결과를 수신하는 기능 등을 수행한다.
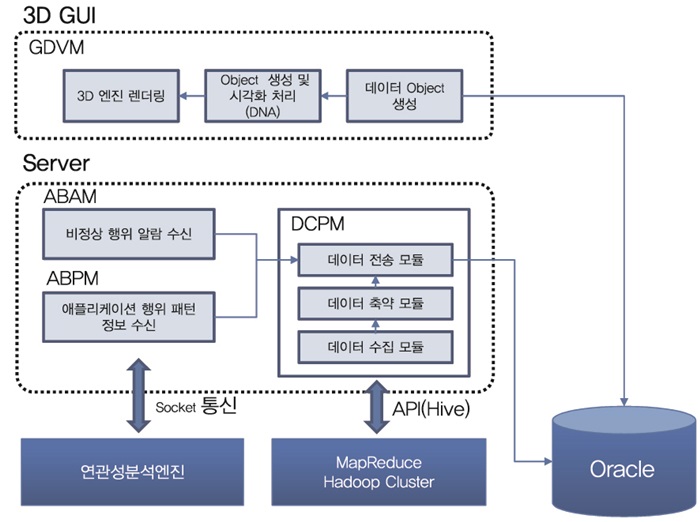
3D GUI 엔진은 사용자PC, 서버, 네트워크 장비로부터 비정상 행위를 탐지하기 위하여 추출된 특징인자들간의 관계성을 DNA 구조형태로 표현한다. 또한, 개별 프로세스에 대한 특징인자 시퀀스를 표현함으로써 시스템의 비정상 상태를 직관적으로 인식할 수도 있다.
V. 결론
본고에서는 인간게놈 프로젝트와 유사하게 사이버보안 분야에서 악성코드의 변종을 탐지하고, 악성코드를 제작하는 해커를 추적하는 사이버게놈 기술과 관련된 국내외 기술동향을 살펴보았다.
최근의 사이버 테러는 과거처럼 몇몇 해킹 집단의 과시용 행위가 아닌 사회적 혼란을 일으키고 국가 안보를 위협하며 개인에게 금전적으로 피해를 주는 등 다양한 목적으로 자행되고 있다. 특히, 악성코드 제작이 쉬운 돈벌이 수단이 되면서 많은 범죄조직이 악성코드 제작에 달려들어 점점 고도화되고 수많은 변종을 양산하고 있다. 특히 수적으로 이전에는 상상도 못 할 정도의 엄청난 양의 악성코드가 생성되고 있다.
따라서 이제는 기존의 악성코드 탐지기법에서 벗어나 새로운 접근 방법이 필요한 시점이다. 본고에서 소개한 사이버게놈 개념을 도입한 악성코드 대응 기술이 악성코드의 폭발적 증가와 복합적 공격 양상으로 변화하고 있는 현재의 사이버 상황에서 사용자들에게 좀 더 안전한 인터넷 환경을 조성해줄 것으로 기대한다.
용어해설
악성코드(Malware) 악성과 소프트웨어의 합성어로서 악성 행위를 위해 개발된 컴퓨터 프로그램 즉 소프트웨어이다. 바이러스, 웜, 트로이목마 또는 루트킷과 같이 컴퓨터 및 모바일 기기를 감염시키고 통제하기 위해 사이버 범죄자들이 사용하는 프로그램 종류
사이버게놈(Cyber Genome) 미 국방부 산하 고등방위연구계획국(Defense Advanced Research Projects Agency: DARPA)이 처음 만든 용어로 인간의 게놈(유전체)을 분석하듯 인터넷상의 악성코드를 분석해 공격의 배후를 파악하고 보안 사고를 미리 차단하는 고도의 보안기술
약어 정리
API
Application Programming Interfaces
APT
Advanced Persistent Threat
DARPA
Defense Advanced Research Projects Agency
DDoS
Distributed Denial of Service
DLL
Dynamic Link Library
DNA
Deoxyribonucleic acid
DP
Dynamic Programing
GENOME
Gene chromosome
HGP
Human Genome Project
IAT
Import Address Table
IDT
Interrupt Descriptor Table
LCS
Longest Common Subsequence
PE
Portable executable
PROCMON
Process Monitor
RNA
Ribonucleic acid
SQL
Structured Query Language
SSDT
System Service Descriptor Table
URL
Uniform Resource Locator
A. Moser, C. Kruegel, and E. Kirda, “Exploring Multi Execution Paths for Malware Analysis,” Proc IEEE Symposium on Security and Privacy, May 2007, pp. 231-245.
V. Thomas, P. Ramagopal, and R. Mohandas, “The Rise of Autorun-Based Malware,” McAfee Avert Labs., 2009.
E. Manuel et al., “A Survey on Automated Dynamic Malware-Analysis Techniques and Tools,” ACM Computing Surveys(CSUR), vol. 44, no.2, Feb. 2012, pp. 1-42.
X. Chen et al., “Towards an Understanding of Anti-Virtualization and Anti-Debugging Behavior in Modern Malware,” DSN, IEEE Computer Society, 2008, pp. 177-186.
G. Hoglund and J. Butler, “Rootkits: Subverting the Windows Kernel,” Addison-Wesley Professional, 2006.
T.F. Smith and M.S. Waterman, “Identification of Common Molecular Subsequences,” J. Molecular Biology, vol. 147, no. 1, Mar. 1981, pp. 195–197.
S.B. Needleman and C.D. Wunsch, “A General Method Applicable to the Search for Similarities in the Amino Acid Sequence of Two Proteins,” J. Molecular Biology,vol. 48, no. 3, March 1970, pp. 443–453.
In Wikipedia: Longest Common Subsequence (LCS), https://en.wikipedia.org/wiki/Longest_common_subsequence_problem
J. Saxe, D. Mentis, and C. Greamo, “Visualization of Shared System Call Sequence Relationships in Large Malware Corpora,” Proc. 9th Inter. Symposium on Visualization for Cyber Security(Vizsec), Oct. 2012, pp. 33-40.
Y. Chen et al., “Multiple Sequence Alignment and Artificial Neural Networks for Malicious Software Detection,” Proc. 8th Inter. Conf. Natural Compu-tation(ICNC), May 2012, pp. 261-265.
안철수연구소, Special Report, “DNA Scan으로 ‘사전 예방 시대’열다,” https://www.ahnlab.com/kr/site/securit yinfo/secunews/secuNewsView.do?menu_dist=2&se q=17309

- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.