네트워킹 서비스 고가용성 기술동향
Trends of High Availability Networking Services
- 저자
- 심재찬, 류호용, 양선희 / 네트워크SW플랫폼연구실
- 권호
- 30권 6호 (통권 156)
- 논문구분
- 일반 논문
- 페이지
- 79-89
- 발행일자
- 2015.12.01
- DOI
- 10.22648/ETRI.2015.J.300609
- 초록
- 네트워크 분야의 시장 변화에 신속하게 대응하기 위해 장비 제조 업체들은 표준에 기반을 두어 하드웨어 및 소프트웨어를 개발하고 있다. 이러한 산업계 표준을 제정하는 대표적인 기구로 SCOPE alliance와 Service Availability Forum(SAForum)이 있으며, 이들은 상호 협력 속에 새로운 생태계 구축을 위한 시도를 꾸준히 진행해오고 있다. 본고에서는 먼저 이들 기구의 표준화 동향을 살펴보고, 특히 네트워킹 소프트웨어 분야에서 고가용성 향상을 위한 기술로 SAForum에서 제정하여 배포하고 있는 미들웨어 기술을 소개한다. 그리고 미들웨어에서 제공하는 다양한 서비스 중에서 고가용성 제어의 핵심 서비스인 Availability Management Framework(AMF)와 이의 기반이 되는 다중화 모델을 설명하고, 국외 통신장비에서 채용하고 있는 대표적인 가용성 기술들을 살펴본다.
Share
Ⅰ. 서론
모든 산업분야에서 컴퓨팅 자원과 네트워크 자원을 이용한 원격 제어 및 관리로 전환되면서 재해 재난에 대비한 공공 안전 분야뿐 아니라 국방, 항공 우주, 원자력 등과 같은 미션 크리티컬 분야에서 네트워크 연결의 가용성 및 통신 시스템의 신뢰성(dependability)에 대한 요구가 최근 들어 더욱 확산되고 있다. 또한, 이전에는 이러한 신뢰성 보장과 같은 요구사항을 만족하지 않았던 application이 제공하는 서비스들에 대한 고가용성(high availability) 요구 역시 증가하는 추세이다.
Application의 신뢰성은 가용도를 포함한 몇몇 요소에 의해서 적합성이 결정된다[1]. 물론 고가용성을 달성하기란 쉽지 않은 일이다. 특히 고가용성을 ‘서비스가 99.999%(five nines) 가용한 경우’라고 정량화하면 이를 달성하는 것은 아주 어려운 문제가 된다[2]. 따라서 이러한 가용도를 보장하기 위해서는 다양한 기술들을 활용하게 되는데, 다중화(redundancy)는 전통적으로 시스템 또는 서비스의 높은 가용도 수준을 유지하는 데 활용되는 대표적인 기술 중 하나이다.
일반적으로 고가용성을 고려하지 않고 개발되는 application들은 서비스 가용도를 유지하기 위한 다양한 방법(예, redundancy, heartbeating, state synch-ronization 등)들을 적용하지 않고 있다. 그래서 이렇게 개발된 application을 가용성을 보장하도록 수정 보완하기란 무척 부담된다. 따라서 이에 대한 대안으로 appli-cation과 서비스의 가용도를 관리하는 미들웨어 솔루션이 등장하게 되었다. 이와 관련하여 표준화 기구인 Service Availability Forum(SAForum)은 서비스의 가용도를 관리하는 미들웨어 솔루션 및 이를 활용하기 위한 인터페이스를 정의하였다[3].
본고에서는 통신장비에서 요구되는 높은 가용성(99.999%)을 보장하고자 2000년대 들어 구성된 대표적인 표준화 기구를 소개하고, 이들 중에서 특히 소프트웨어 application의 가용도 확보와 관련된 표준화 기구인 SAForum 및 여기서 제정하고 있는 표준을 알아본다. 그리고 통신장비의 고가용성 확보를 위한 다양한 기술동향에 대해 살펴보고자 한다.
Ⅱ. 고가용성 표준화 동향
컴퓨팅 및 네트워크 산업계는 지난 20년 동안 기술적으로나 상업적으로 비약적인 발전을 해왔다. 한 회사가 처음부터 끝까지 모든 것을 다 만들어내던 패러다임도 수직적 통합 패러다임으로 대체되고 있다. 수직적 통합 패러다임은 시스템 개발에 있어 Component Based Architecture(CBA)를 선호한다[4]. CBA의 중요한 성공 요인 중 하나는 컴포넌트들 사이의 상호 운용성과 표준화이다. 예를 들면 같은 하드웨어에서 다양한 운영체제가 동작할 수 있고, 각 운영체제는 호환성이 있는 다양한 애플리케이션들을 지원할 수 있다. CBA에서 컴포넌트들은 인터페이스를 통해 상호 동작하기에, 시스템은 Common Off The Shelf(COTS) 컴포넌트들을 이용해서 만들게 된다. 이러한 환경 조성을 이끄는 대표적인 표준화 기구로는 SCOPE alliance와 SAForum이 있다.
1. SCOPE Alliance
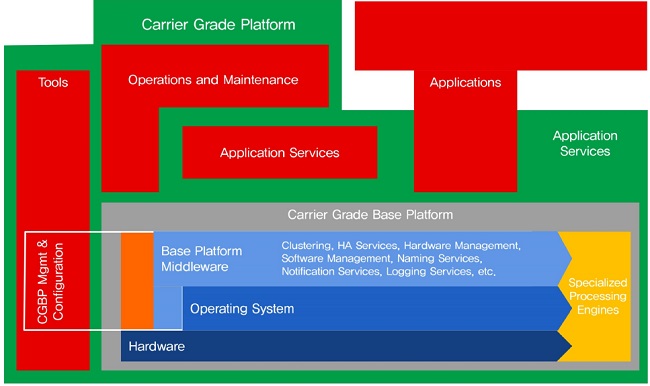
2006년 Alcatel-Lucent, Ericsson, Huawei, Motorola, NEC, Nokia-Siemens 등 주요 통신장비 제조 업체들이 모여 SCOPE alliance를 만들었으며, 이 기구에서는 COTS 하드웨어의 표준화를 진행했다. 대표적인 하드웨어 표준으로는 Advanced Telecommunication Computing Architecture(ATCA)가 있는데, 현재 많은 통신장비들이 이 규격에 따라 네트워크 장치를 만들고 있다. 그리고 공개 소스 기반 Carrier Grade Base Platform(CGBP) [(그림 1) 참조]을 표준화하여 이를 장비 제조 업체에 확산시키고 있다[5].
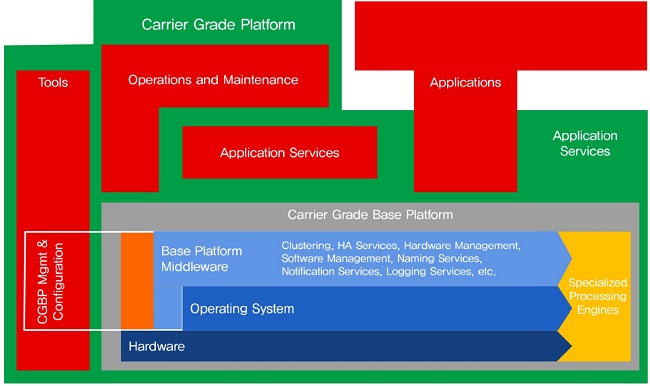
2. SAForum
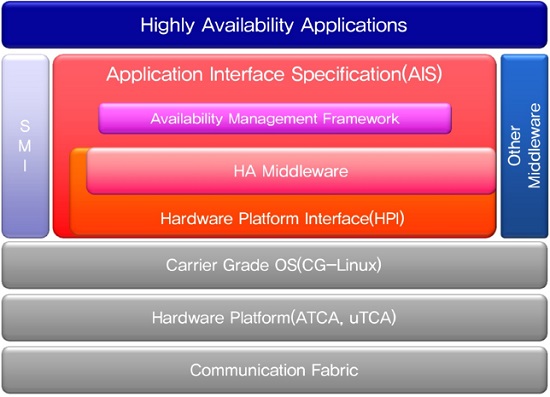
SAForum의 주요 목표는 다양한 플랫폼에 이식 가능한 COTS 컴포넌트를 이용해서 고가용성을 보장하는 애플리케이션 개발이 가능하도록 하는 데 있다. 이런 목표를 위해 SAForum은 표준화된 API들을 통해서 접근 가능한 미들웨어 서비스들을 정의하고 있다. 결국 필요한 인터페이스를 구현한 임의의 컴포넌트는 미들웨어와 상호 작용할 수 있고, 결과적으로 그런 COTS 컴포넌트들로 이루어진 애플리케이션의 서비스 가용도는 SAForum 미들웨어에 의해 관리될 수 있다. 그리하여 예상할 수 없는 장애 또는 미리 계획된 서비스 중단 시간을 최소화하고, 이를 관리하여 시스템과 서비스 가용 시간을 최대화하여 가용도를 높일 수 있다. SAForum에서는 하드웨어로부터 service availability middleware를 추상화하는 API 규격인 Hardware Platform Interface(HPI)와 고가용 application과 서비스 개발에 필요한 기능을 제공하는 service availability middleware 규격인 Application Interface Specification(AIS)을 제정하여 배포하고 있다.
3. SAForum AIS Specification
SAForum은 SCOPE alliance와 전략적인 협력을 맺고 carrier grade platform과 서비스 application을 위한 고가용 미들웨어 규격을 제정하여 배포하고 있다. 2003년 4월에 최초 버전을 공개한 후 2011년 9월 말 release 6.1을 공개하였다. (그림 2)는 서비스의 가용도 보장을 위한 고가용 미들웨어의 상위 레벨 시스템 구조이다.
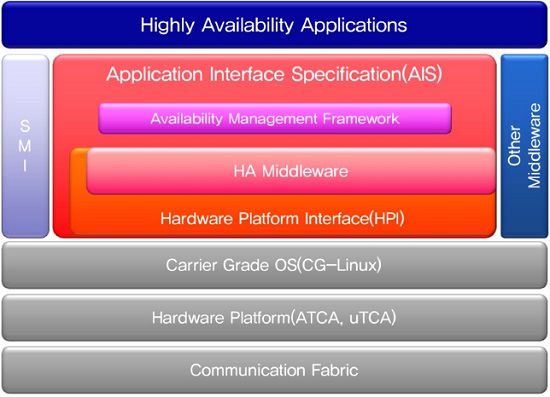
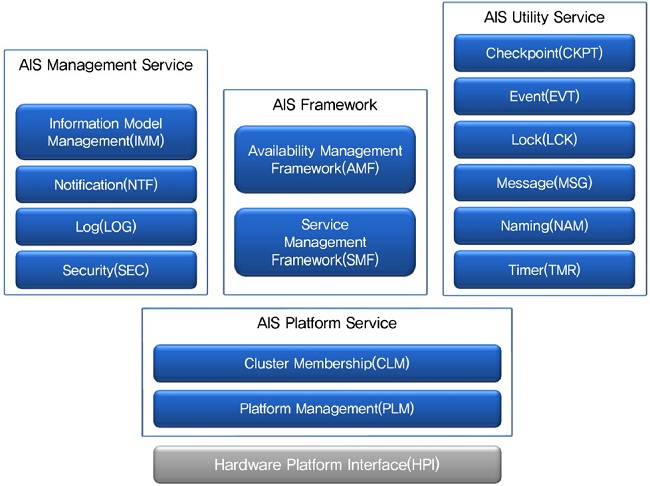
다양한 응용 서비스의 가용성 보장을 위해 SAForum에서는 (그림 3)과 같은 미들웨어 서비스 API인 AIS를 정의하고 있으며, 이들 미들웨어 서비스는 다음과 같다.
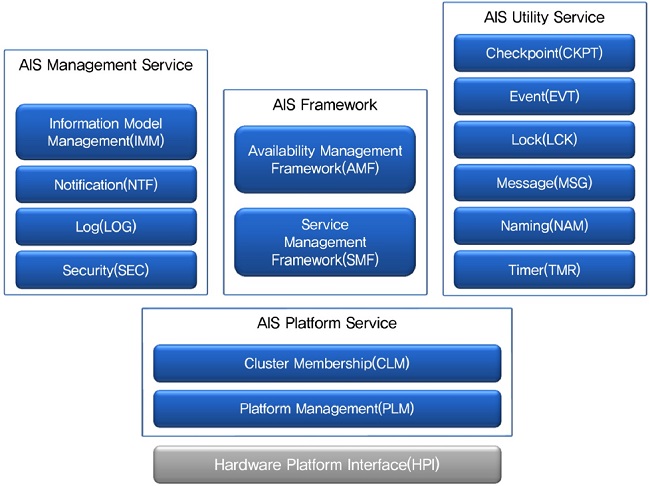
· Availability Management Framework(AMF, SAI-AIS-AMF-B.04.01)
모든 서비스를 제어하며, 서비스 컴포넌트의 상태를 감시하고 판단하여, 장애가 발생하면 정책에 따라 복구 조치를 수행함.
· Service Management Framework(SMF, SAI-AIS-SMF-A.01.02)
AMF 및 다른 서비스들과 연동하여 소프트웨어 migration을 수행함.
· Checkpoint Service(CKPT, SAI-AIS-CKPT-B.02.02)
Application 데이터를 저장 관리하여, 문제가 발생하면 저장된 데이터를 이용하여 손실을 최소화하여 복구할 수 있도록 함.
· Cluster Membership Service(CLM, SAI-AIS-CLM-B.04.01)
클러스터에 포함된 노드들의 상태를 관리하고, 등록, 삭제 정보를 제공함.
· Event Service(EVT, SAI-AIS-EVT-B.03.01)
Publish/Subscribe 방식의 multipoint to mul-tipoint asynchronous 통신 서비스를 제공함.
· Lock Service(LCK, SAI-AIS-LCK-B.03.01)
클러스너 내부 자원들에 대한 접근 제어를 제공함.
· Log Service(LOG, SAI-AIS-LOG-A.02.01)
시스템 운용자 또는 자동화된 도구에게 운용 시 발생하는 정보를 제공함.
· Information Model Management Service(IMM, SAI-AIS-IMM-A.03.01)
AIS 서비스 및 application을 위해서 정보 모델을 구성하고 관리하는 방안을 제공함.
· Notification Service(NTF, SAI-AIS-NTF-A.03.01)
경보, 상태 변화, object의 생성/삭제, 값의 변화 등의 정보를 제공함.
· Message Service(MSG, SAI-AIS-MSG-B.03.01)
Message queue를 기본으로하여 application 사이에 메시지를 송수신하는 기능을 제공함.
· Timer Service(TMR, SAI-AIS-TMR-A.01.01)
일정 시간 또는 특정시간에 time out 정보를 제공함.
SAForum에서는 서비스 가용도를 높이기 위해 전술한 모든 미들웨어 서비스를 활용하기를 권고하지는 않는다. 하지만 적어도 AMF, cluster membership(CLM), IMM 그리고 Notification(NTF)은 응용 서비스의 가용도 보장을 위해 활용할 것을 권장하고 있다.
Ⅲ. Redundancy Model
서비스 가용도(service availability)는 임의의 시간에 서비스가 가용한 확률로 정의된다[6]. 그리고 고가용성은 서비스가 99.999% 가용할 때(five nines of availability) 달성된다[7]. 서비스를 제공하는 컴포넌트에 장애가 발생한 경우, 같은 기능을 제공하는 여분의 컴포넌트 사본이 동일한 서비스를 제공하는 역할을 대신해야 한다. 이런 전환이 신속한 방법으로 수행될 때, 서비스 이용자는 단지 무시해도 좋을 정도의 서비스 중단을 경험하게 된다. 이를 위한 한 가지 방안은 가용성 관리 소프트웨어를 활용하여 서비스를 제공하는 소프트웨어를 모니터링하고, 장애 상황에서 서비스 제공이 즉시 재개되도록 하는 것이다. 앞서 언급했듯이 SAForum에서는 AMF를 포함한 미들웨어 서비스들인 Appli-cation Interface Specification(AIS)를 제정했다[8].
미들웨어 서비스 중에서 AMF의 역할은 애플리케이션이 제공하는 서비스의 가용도를 관리하는 것이다. 이는 여분의 컴포넌트의 관리를 통해서 달성되며, 서비스 복구 관리에 AMF의 역할은 다음과 같다.
· 고장 탐지(failure detection)
AMF는 고장 발생을 탐지하거나 통보받음.
· 고장 격리(failure isolation)
AMF는 결함있는 컴포넌트를 정리함으로써 고장을 격리함.
· 서비스 복구(service recovery)
AMF는 장애 컴포넌트를 정상 컴포넌트로 교체하여 서비스를 복구함.
· 수리(repair)
AMF는 결함 컴포넌트 또는 장비의 재시작을 통해 수리를 시도함. 때때로 수리는 복구 절차의 한 프로세스로 실행됨.
AMF가 애플리케이션의 가용도를 관리하기 위해서는 장애가 발생한 경우 적용할 복구 정책 외에 애플리케이션의 컴포넌트들과 서비스들에 대한 배치, 의존성 등에 대한 분명한 서술이 필요한데, 이를 AMF configuration이라 한다.
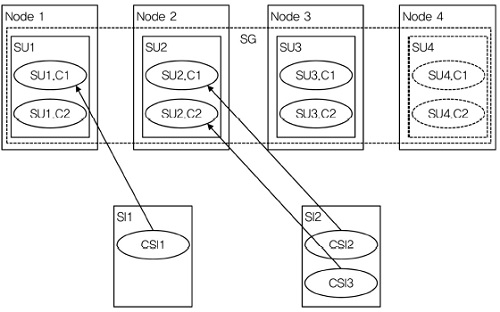
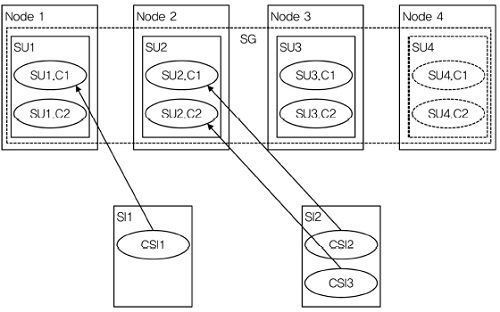
AMF가 관리하는 가장 작은 단위의 개체는 컴포넌트(component)이다. 컴포넌트는 임의의 기능을 제공하는 하드웨어 또는 소프트웨어 자원들의 집합을 의미한다. 그리고 AMF는 각 컴포넌트를 API를 통해서 관리한다. 일례로 컴포넌트는 라우팅 프로토콜의 instance를 상징하는 프로세스를 추상화할 수 있다. Service Unit(SU)은 하나 또는 그 이상의 컴포넌트들로 구성된 논리적 개체로 컴포넌트들이 제공하는 여러 기능을 서비스로 결합한다. 예를 들어 라우팅 프로토콜과 Routing Information Base(RIB) 매니저는 밀접하게 협력하며, 함께 그룹화되어 라우팅 서비스를 제공한다. 기능을 제공하거나 보호하는 것과 관련되어 컴포넌트에 할당될 수 있는 작업(workload)은 Com-ponent Service Instance(CSI)로 표현된다. 예를 들어, source IP 주소를 포함한 라우팅 프로토콜 정보를 처리하는 작업은 라우팅 프로토콜에 부여된 작업, 즉 Routing-CSI로 표현할 수 있다. 그리고 같은 SU의 컴포넌트들에 할당될 서비스에 필요한 CSI들의 집합은 Service Instance(SI)로 나타낸다. 즉, SI는 실행시간에 실제로 서비스를 제공하거나 standby로 서비스를 보호하도록 AMF에 의해 SU에 할당되는 작업이다. 일례로 라우팅 서비스는 라우팅 프로토콜 CSI (Routing-CSI)와 RIB 매니저 CSI(RIB Mgr-CSI)를 결합하여 만들 수 있다.
AMF는 다중화한 SU들에 부여한 작업을 관리함으로써 SI들의 가용도를 유지한다. 이를 위해 SU들은 Service Group(SG)으로 그룹화된다. 즉, SG는 SI들의 집합을 보호하기 위해 협력하는 SU들의 집합으로 구성된다. 그리고 다중화 모델(redundancy model)에 따라 동작한다. 이러한 다중화 모델은 크게 5종류가 있는데, 2N, N+M, N-Way, N-Way Active, No-Red-undancy 이다[9]. 이들 다중화 모델은 각 SI가 갖게 되는 active와 standby 상태 할당(state assignment)의 개수와 이들을 어떻게 SU에 분배하는가에 따라 구분된다.
1. No Redundancy Model
Active SU만 있고 standby SU은 존재하지 않는다. 그러나 여분(spare)의 SU가 존재할 수 있다. 각 SI에는 한 번에 하나의 active SU만 할당된다. 그리고 하나의 SU는 많아야 하나의 SI에만 active 상태로 할당된다 [(그림 4) 참조].
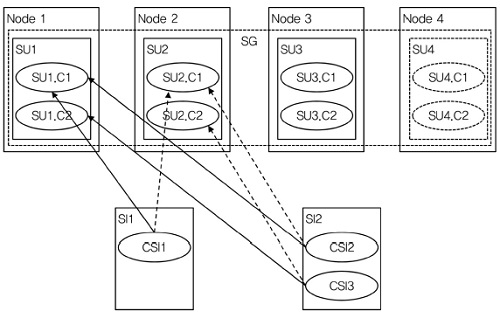
2. 2N Redundancy Model
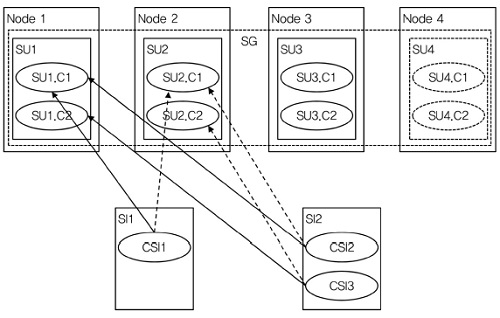
SG에 의해 보호받는 모든 SI에 대해, SG에는 많아야 하나의 SU가 active 상태이고, 많아야 하나의 SU가 standby 상태이며, 이들을 각각 active SU와 standby SU라 한다. 따라서 각각의 SI에는 많아야 하나의 active SU와 하나의 standby SU가 할당된다[(그림 5) 참조].
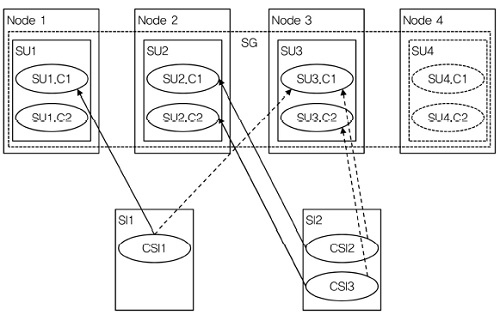
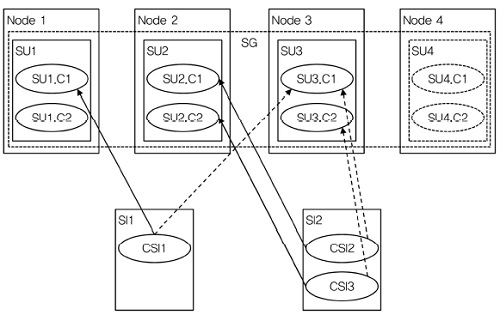
3. N+M Redundancy Model
2N redundancy model과 유사하다. 그러나 SG에는 N개의 active SU들과 M개의 standby SU들이 있다. 이 때 통상적으로 N > M을 만족한다. 하나의 SU는 모든 SI들에 대해 active 또는 standby SU가 될 수 있다. 즉, 하나의 SU는 동시에 어떤 SI들의 active SU가 되고, 다른 SI들의 standby SU가 될 수 없다. 그리고 각 SI에는 많아야 하나의 active SU와 하나의 standby SU가 할당된다[(그림 6) 참조].
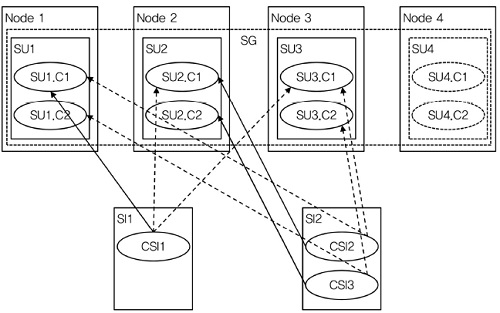
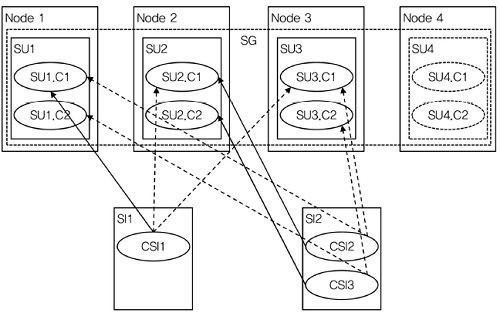
4. N-way Redundancy Model
SG에는 복수의 SI를 보호하는 N개의 SU들이 존재한다. 하나의 SU는 동시에 어떤 SI들의 active SU가 되고, 다른 SI들의 standby SU가 될 수 있다. 하나의 SI에 대해 많아야 하나의 SU가 active 상태를 가지나, 같은 SI에 대해서 하나 또는 다수의 SU들이 standby 상태를 가진다[(그림 7) 참조].
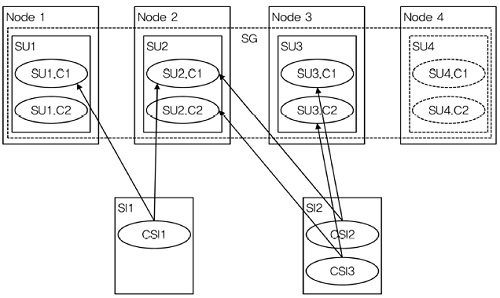
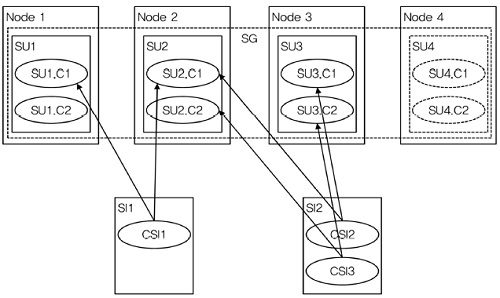
5. N-way Active Redundancy Model
Ⅳ. 네트워크 고가용성 기술
최근 들어 네트워킹 서비스의 가용성을 보장하기 위해 네트워크 장비들에 다양한 기술들이 적용되고 있으며, 대표적인 기술로는 Non-Stop Forwarding(NSF), Non-Stop Routing(NSR) 그리고 Graceful Restart(GR) 등이 있다. 그러나 이들이 기술적으로 분명히 다름에도 불구하고 별다른 구분 없이 회자됨으로써 매우 혼란스럽게 만드는 경향이 있다[10].
대부분의 고성능 라우터들은 구조적으로 forwarding plane과 control plane을 각각 서로 다른 물리적 컴포넌트로 분리하고 있다. Control plane은 라우팅 프로토콜을 실행하고, 경로 연산에 필요한 정보들을 유지 관리하며, forwarding table(Forwarding Information Base: FIB)을 생성한다. 그리고 이 FIB는 패킷전송을 책임지는 forwarding plane에 전달되며, 이 정보를 바탕으로 forwarding plane은 패킷을 전달한다.
사실 control plane이 완전히 동작을 멈춘다 하더라도 물리적으로 분리되어 자체 프로세서를 가진 forwarding plane은 자신이 보유하고 있는 FIB를 바탕으로 패킷전달을 계속할 수 있는데 이를 non-stop forwarding이라 한다. 물론 이러한 동작방식은 위험을 내포하고 있다. 만약 control plane이 동작을 멈춘 상황에서 네트워크 토폴로지가 바뀌면 새로운 루트 정보를 처리할 방법이 없어지고, 결국 forwarding plane의 FIB 정보가 유효하지 않을 수 있으며, 패킷들이 정확한 경로로 전달되지 않을 수 있기 때문이다.
그렇다면 이러한 위험을 감수하면서도 왜 non-stop forwarding이 필요한 걸까? 답은 control plane의 다중화를 통한 시스템 가용도 향상에 있다(control plane을 시스코는 route processor라 하며, 주니퍼는 routing engine이라 한다). Non-stop forwarding은 패킷전달을 방해하지 않고, active에서 standby control plane으로 전환(switchover)할 수 있도록 지원한다. 만약 standby control plane이 interface와 같은 시스템 컴포넌트의 현재상태와 구성정보들의 사본을 유지한다면, active control plane의 역할을 맡을 때 이러한 모든 정보를 새로 구성하는 것보다 훨씬 빨리 active 역할을 수행할 수 있다. 이러한 방법을 시스코는 Stateful Switchover(SSO)라 하고, 주니퍼는 Graceful Routing Engine Switchover(GRES)라 한다.
다음은 가장 큰 혼란을 야기하는 NSR이다. 비록 전환 시간을 줄이기 위해 상태정보를 이용한다 하더라도 control plane switchover의 문제는 switchover로 인해 라우팅 프로토콜의 adjacency가 깨진다는 점이다. 즉, 임의의 라우터 R의 active control plane이 정지하면 인접 라우터는 peering session이 끊어졌음을 감지하게 된다. 물론 standby control plane이 active control plane의 역할을 넘겨받아 동작하게 되면 인접 라우터들과 다시 adjacency를 설정하게 되지만, 적어도 이 시간 동안 인접 라우터들은 자신의 또 다른 인접 라우터들에게 라우터 R이 더 이상 유효한 라우터가 아님을 알리게 되며, 이에 따라 인접 라우터들은 새로운 데이터 전달 경로(path)를 찾게 된다. Switchover 결과로 standby control plane이 active 역할을 수행하게 되면, 인접 라우터들과 adjacency를 다시 설정하고, 자신이 정상 동작함을 통지함으로써 모든 라우터가 최적의 경로를 다시 계산하게 된다. 그런데 이러한 일련의 상황은 네트워크를 매우 불안정하게 만들 수 있다. 따라서 non-stop routing을 제공하면서 가장 중요한 고려사항은 peering session 단절로 인한 영향을 방지하거나 적어도 최소화하는 것이다.
Control plane switchover 동안 adjacency 단절의 제어를 위한 방법의 하나는 graceful restart(GR) protocol extension이다. 만약 라우터의 control plane이 정지하면 인접한 라우터(helper router)들은 곧바로 자신의 이웃 라우터들에 해당 라우터가 가용하지 않음을 통보하지 않고 임의의 시간(grace period) 동안 기다리도록 한다. 그 시간 동안 장애에 빠진 라우터의 control plane이 정상 동작상태로 복구되고, grace period 종료 전에 peering session을 복구하면, 일시적으로 끊어졌던 peering session은 인접 라우터 너머의 네트워크에 영향을 주지 않게 된다. 그러나 GR protocol extension에도 다음과 같은 문제가 있다.
- 인접 라우터 역시 GR protocol extension을 지원해야 함.
- 만약 control plane 또는 라우터가 완전히 고장 난 경우, grace period는 전체 네트워크 경로 정보의 재 수렴을 느리게 할 수 있음.
최신 non-stop routing은 standby control plane이 switchover 후에 새로운 peering session을 설정하는 대신에 기존 peering session을 그대로 이용할 수 있도록 라우팅 프로토콜의 상태와 adjacency maintenance activities를 인지하고 유지한다. 그렇게 함으로써 인접 라우터들은 switchover를 인식하지 못하게 되며, non-stop routing은 라우터 내부 프로세스로 동작하기 때문에 이웃한 인접 라우터들이 어떠한 종류의 protocol extension도 지원할 필요가 없게 된다.
지금까지 설명한 이러한 용어의 혼동은 여러 벤더들이 이들 용어를 각자 자기들 입맛대로 다르게 사용하는 데서 비롯됐다. 일례로 주니퍼의 경우 graceful restart를 graceful restart라 하지만, 시스코는 graceful restart가 라우팅에 적용됨에도 불구하고 non-stop forwarding awareness라 부른다.
다음 절에서는 네트워크 장치의 가용도를 높이기 위한 중요 기술에 대해 좀 더 자세히 살펴보고자 한다. 이해를 돕기 위해 본고에서는 현재 서비스를 제공하는 라우팅 엔진을 active 라우팅 엔진이라 하고, 여분의 라우팅 엔진은 standby 라우팅 엔진이라 한다.
1. 라우팅 엔진 다중화
라우팅 엔진의 다중화는 동일한 라우팅 플랫폼에 여러 개의 라우팅 엔진을 설치함을 말한다. 이들 중 하나는 active로 동작하며, 나머지들은 active 라우팅 엔진의 고장에 대비해 standby로 대기한다. 하나의 라우팅 엔진을 가진 라우팅 플랫폼 보다 두 개의 라우팅 엔진을 가진 라우팅 플랫폼상에서 네트워크 경로에 대한 재수렴이 더 빨리 이루어진다[11].
2. Graceful Routing Engine Switchover
Routing Engine Switchover(RES)는 다중 라우팅 엔진이 있는 라우팅 플랫폼에서 하나의 라우팅 엔진이 고장나도 패킷전달을 지속할 수 있도록 한다. GRES는 네트워크 인터페이스 및 커널정보를 유지하며, 이로 인해 트래픽이 끊어지지 않고 계속 전달된다. 그러나 GRES는 control plane의 정보, 즉 라우팅 프로토콜의 경로 정보는 보존하지 않는다. 따라서 인접 라우터는 해당 라우터가 재시동함을 감지하고 개별 라우팅 프로토콜 표준 (specification)에서 규정하고 있는 방법으로 이러한 상황에 대처하게 된다[12].
Switchover 동안 빠른 복구 또는 라우팅 프로토콜 상태 정보의 유지를 위해서 GRES는 graceful restart 또는 non-stop active routing 기능과 연계하여 동작해야 하며, 만약 active 라우팅 엔진에서 라우팅 정보가 갱신되면, 곧바로 standby 라우팅 엔진에 변경된 라우팅 정보가 반영되어야 한다. 만약 standby 라우팅 엔진이 active 라우팅 엔진으로부터 keepalive 메시지를 정해진 시간 내에 수신하지 못하면, standby 라우팅 엔진은 active 라우팅 엔진이 장애라고 판단하고 active 라우팅 엔진의 권한을 갖게 된다. 그리고 패킷 포워딩 엔진은 이전 active 라우팅 엔진과 연결을 끊고, 새로운 active 라우팅 엔진과 연결을 설정하며, 재시동은 하지 않고, 트래픽 전달 역시 중단하지 않는다.
3. Non-Stop Active Routing
Non-stop active routing(NSR)은 네트워크 장치의 상황 변화에 대해 이웃한 인접 노드에 알리지 않고 active 라우팅 엔진에서 standby 라우팅 엔진으로의 전환을 가능하게 한다. NSR은 인터페이스와 커널정보를 유지하며, 추가로 두 라우팅 엔진에 라우팅 프로토콜 프로세스를 실행함으로써 라우팅과 프로토콜 세션정보 또한 유지한다. 그리고 커널에서 관리하는 TCP 연결 정보 역시 유지한다[13]. 이런 추가 정보를 유지함으로써 NSR은 독립적으로 동작하며, 라우팅 프로토콜 정보를 복구하는데 인접한 helper 라우터들에게 의지하지 않는다. 따라서 인접 라우터들이 GR protocol extension을 지원하지 않는 네트워크에 유리하다. 결과적으로 이러한 향상된 기능 때문에 NSR이 GR을 자연스럽게 대체하고 있다. 물론 NSR을 이용하기 위해서는 먼저 GRES를 활성화해야 한다.
NSR과 GR protocol extension은 모두 네트워크 장치의 가용성을 유지하여 궁극적으로 네트워킹 서비스의 고가용성을 보장하기 위한 기술이다. 이미 설명한 GR protocol extension은 라우터의 재시동을 필요로 하며, GR protocol extension을 실행하는 restarting 라우터는 자신의 라우팅 프로토콜 정보를 복원하기 위해서 인접 helper 라우터들의 도움을 받는다. 즉, restarting 라우터가 재시동을 하면 helper 라우터들은 자신이 유지하고 있는 라우팅 정보를 restarting 라우터에 제공한다.
반대로 NSR은 라우터의 재시동을 수반하지 않는다. Active 라우팅 엔진과 standby 라우팅 엔진은 라우팅 프로토콜 프로세스를 실행하고, 이웃 라우터들과 갱신정보를 교환한다. 만약 active 라우팅 엔진의 장애가 발생하면 라우터는 단순히 standby 라우팅 엔진이 이웃 라우터들과 라우팅 정보를 교환하도록 전환(switch-over)한다. 이러한 기능차이 때문에 하나의 라우터에서 GR과 NSR이 같이 실행될 수 없다.
4. 무중단 소프트웨어 업그레이드
In Service Software Upgrade(ISSU)는 control plane의 중단없이 트래픽의 손실을 최소화하면서 소프트웨어 업그레이드를 가능하게 한다. 이는 소프트웨어 업그레이드 동안 네트워크의 단절이 없기 때문이다.
ISSU는 이중화된 라우팅 엔진 플랫폼에서만 제공된다. 그리고 GRES와 NSR이 반듯이 활성화되어야 한다[14].
5. 고가용성 네트워크 운영체제 openN2OSTM
현재 전자통신연구원에서는 국가 R&D 과제로 네트워크 장비에 탑재되는 한국형 네트워크 운영체제인 openN2OS를 개발하고 있다. openN2OS는 스위칭, 라우팅 등 네트워크 운영체제의 기본 기능의 개발을 완료하였으며, 네트워크 장비 및 네트워킹 서비스의 고가용성 보장을 위한 NSR, ISSU, Checkpoint 서비스 및 SSO 등의 고가용성 기능들을 추가 개발 중이다.
Ⅴ. 결론
현재 국내외 모든 산업분야에서 발생하는 생산, 유통, 소비에 이르기까지 일련의 활동들은 통신 네트워크를 배제하고는 진행이 거의 불가능하다. 특히 최근 들어 발생한 대형사고들로 인해 통신 네트워크의 중요성이 더욱 부각되고 있다. 따라서 재해 재난에 대비한 공공 안전 분야뿐 아니라 국방, 항공 우주, 원자력, 발전 등과 같은 미션 크리티컬 분야의 네트워크 연결성 및 시스템 그리고 이를 이용하여 제공되는 서비스에 대한 높은 신뢰성 요구를 더이상 간과하기 어려운 상황이다.
본고에서는 이러한 다양한 분야에 활용되는 가장 기본이며 핵심인 네트워크의 신뢰성 향상을 위해 산업계를 중심으로 진행되고 있는 표준화 동향으로 SCOPE alliance와 SAForum의 동향을 소개했으며, 네트워킹 서비스의 고가용성을 확보하기 위한 대안으로 SAForum에서 제정한 고가용성 미들웨어 및 미들웨어가 제공하는 서비스에 대해 알아보았다. 그리고 미들웨어 서비스 중 가용도 제어를 위한 AMF와 다중화 기술에 대해 살펴보고, 네트워크 장비에 활용되는 고가용성 향상 기술들 역시 소개하였다.
국내 네트워크 산업의 침체 속에서 국내 장비 업체들이 기술 경쟁력을 발판으로 국외 대형벤더와 경쟁을 통해 재도약의 기회를 모색해야 하는 중요한 시점에 산업 패러다임의 변환에 능동적으로 빨리 대응하여 어떠한 상황에서도 안정적인 네트워크 연결성을 보장하는 통신장비를 만들기 위해서는 고가용성 미들웨어의 활용이 하나의 대안이 될 것으로 생각된다. 이와 관련하여 주요 국외 통신장비 업체의 주도로 SAForum에서 규정한 표준을 따르면서 개발이 진행되고 있는 공개 소스 소프트웨어인 OpenSAF에 대한 활용 및 SAForum의 규격을 수용한 고 가용성 미들웨어의 연구개발에 대한 투자 역시 심각하게 고민해 봐야 할 것이다.
약어 정리
AIS
Application Interface Specification
AMF
Availability Management Framework
ATCA
Advanced Telecommunication Computing Architecture
CBA
Component Based Architecture
CGBP
Carrier Grade Base Platform
COTS
Common Off The Shelf
CSI
Component Service Instance
FIB
Forwarding Information Base
GR
Graceful Restart
GRES
Graceful Routing Engine Switchover
HPI
Hardware Platform Interface
ISSU
In Service Software Upgrade
NSF
Non-Stop Forwarding
NSR
Non-Stop Routing
RES
Routing Engine Switchover
RIB
Routing Information Base
SAForum
Service Availability Forum
SG
Service Group
SI
Service Instance
SMF
Service Management Framework
SSO
Stateful Switchover
SU
Service Unit
I. Crnkovic, M. Larsson, and O. Preiss, “Concerning Predictability Independable Component Based Sys-tems: Classification of Quality Attributes,”Architecting Dependable Systems Ⅲ, LNCS, vol. 3549, 2005, pp. 257-278.
J. Gray and D.P. Siewiorek, “High-Availability Computer Systems,” Computer, vol. 24, no. 9, Sep. 1991, pp. 39-48.
N. Wang, D. Schmidt, and C. O'Ryan, “Component-Based Software Engineering: Putting the Pieces toGether,” Addison-Wesley Professional, 2001.
J.C. Laprie, “Dependability - Its Attributes, Impairments and Means,” Predictably Dependable Computing Systems, Springer, 1995, pp. 3-24.
Service Availability ForumTM, Application Interface Specification, “Availability Management Framework,” SAI-AIS-AMF-B.04.01, Sep. 2011.
M. Toeroe and F. Tam, “Service Availability: Principles and Practice,” A John Wiley and Sons, 2012.
Juniper Networks, “Understanding High Availability Features on Juniper Networks Routers,” June 25th, 2014, www.juniper.net
Juniper Networks, “Understanding Graceful Routing Engine Switchover in the Junos OS,” June 25th, 2014, www.juniper.net
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.