클라우드 스토리지 기술동향—페타스케일을 넘어서
Cloud Storage Technology Trends—Beyond Peta-Scale
- 저자
- 박정숙, 이상민, 김홍연, 김영균 / 고성능컴퓨팅연구부 스토리지시스템연구실
- 권호
- 31권 4호 (통권 160)
- 논문구분
- 초지능 기술동향 특집
- 페이지
- 44-54
- 발행일자
- 2016.08.01
- DOI
- 10.22648/ETRI.2016.J.310405
- 초록
- 클라우드 스토리지에 대한 수요가 증가하면서 전 세계적으로 수십 페타바이트까지 지원 가능한 구축 사례들이 점점 늘어나고 있다. 그러나 소셜, 모바일, IoT와 같이 클라우드 스토리지를 이용하는 데이터가 기하급수적으로 증가하면서 2020년경에는 엑사바이트 시대에 진입할 것으로 예상되고 있다. 이처럼 급증하는 클라우드 환경에서의 데이터를 수용하기 위해서는 보다 고용량의 클라우드 스토리지 구축에 대한 필요성이 대두되고 있는 상황이다. 본고에서는 클라우드 환경에서 효율적인 스케일-아웃 방식의 클라우드 스토리지와 관련한 기술동향을 살펴보고 스토리지의 고용량화를 위해 해결해야 할 기술적 이슈들이 무엇인지 분석한다.
Share
Ⅰ. 서론
현재 전 세계적으로 클라우드 스토리지는 페타스케일 수준으로 많은 구현 및 적용 사례들이 있다. 그러나 IoT, 빅데이터, 소셜, 모바일 등에 의한 데이터가 급격히 증가할 것으로 예상되면서 이를 수용할 수 있는 더 대규모화된 클라우드 스토리지에 대한 필요성이 대두되고 있다.
IDC에 의하면 2020년에 디지털 데이터의 생산량은 약 44,000 엑사바이트 규모로 엄청난 증가가 예상된다[1]. 이러한 데이터의 증가는 (그림 1)에서 보는 바와 같이 IoT, 소셜, 모바일 기기 등에 의해 생성되는 데이터가 두드러진 원인으로 분석된다.
(그림 1)
2020년 디지털 데이터 생산량 예측

<출처>: Dell, “Dell Solutions Tour 2013,” Sept. 2013, http://www.slideshare.net/dellenterprise/dell-solution- tour-copenhagen.
첫 번째, IoT와 관련하여서 2014년 Gartner 발표 자료에 따르면, 사물 인터넷을 통해 2020년에 26억 개의 사물이 약 30,000EB/년 데이터를 생산하고 90% 이상의 데이터가 클라우드에 저장될 것으로 전망된다[2]. 두 번째, 스마트폰, 태블릿, 웨어러블 개인 단말기 등의 급속한 확산으로 개인의 이미지나 영상 등의 고품질 비정형 데이터는 지속적으로 증가되고 있어서 클라우드 사업자는 조만간 개인에게 제공하는 클라우드 스토리지 용량 증가 문제 해결에 직면할 것으로 예상된다. IDC는 2020년 디지털 데이터 생산량 약 44,000EB 중에서 80%가 비정형 데이터 타입이고, 비정형 데이터의 70%는 고화질의 이미지와 동영상일 것으로 예측된다[1].
이렇게 생산된 데이터는 단순히 저장/공유하던 기존 클라우드 스토리지 기술과는 달리, 데이터 축적/활용/재사용 등을 통해 유의미한 정보생성뿐만 아니라 새롭고 다양한 비즈니스를 창출할 수 있도록 빠르고 효율적인 데이터 처리가 가능한 스토리지 기술을 요구한다.
또한, 기후 변화, 자원 탐사, 물질/생물 구조 해석, 인간 뇌 시뮬레이션 등 과학적 난제를 처리하는 데에 엑사스케일 컴퓨팅 기술이 요구되므로, 2020년 엑사스케일 컴퓨팅 시대를 대비해 미국, 유럽, 일본, 중국 등 기술 개발 경쟁이 가속화되고 있는 시점이다[3][4]. 따라서 이를 지원할 수 있는 고용량과 고속의 스토리지 기술에 대한 관심도 증가하고 있다.
이러한 현상분석을 통해, 생산되는 광대한 양의 데이터를 효율적으로 저장하고 처리할 수 있는 더 큰 용량의 클라우드 스토리지 개발은 필수적으로 진행되어야 하는 기술임을 알 수 있다. 그러나 기존의 페타스케일 스토리지 기술은 한계에 다다랐기 때문에 고용량화를 달성하기 위해서는 여러 가지 기술적인 이슈들을 해결해야 할 것으로 예상된다.
이와 관련하여 미국 Lawrence Berkeley National Lab은 엑사스케일 스토리지의 기술적 도전 과제들을 엑사바이트까지 수평적 저장 용량 확장, 기하급수적으로 증가하는 메타데이터 처리, 잦은 고장에 따른 방대한 데이터 실시간 복구, 저장장치의 소비전력 절감을 포함하여 4가지로 언급하고 있다[5]. 이 기술적 이슈들은 엑사스케일 스토리지뿐만 아니라 현재의 클라우드 스토리지의 규모를 확장하기 위해서도 반드시 해결되어야 하는 기술 이슈이다.
따라서 본고에서는 클라우드 스토리지의 국내외 기술 현황과 고용량 클라우드 스토리지를 위해 해결해야 하는 주요한 이슈들에 대해 기술하고자 한다. 본고에서의 클라우드 스토리지는 서버 수를 추가함으로써 시스템의 처리 성능을 향상시키는 스케일-아웃(scale-out) 방식에 의한 스토리지 기술들만을 대상으로 한다.
본고의 내용은 다음과 같다. 제 Ⅱ장에서는 국내외 클라우드 스토리지 기술동향에 대해 살펴본다. 제 Ⅲ장에서는 클라우드 스토리지의 확장성과 관련한 분석 결과를 기술한다. 제 Ⅳ장에서는 클라우드 스토리지의 내결함성과 관련한 분석 결과를 기술한다. 마지막으로 제 V장에서 본고의 결론을 맺는다. 고 관련 분야의 ICT 기술들의 동반 성장에 기여할 수 있을 것으로 예상된다.
Ⅱ. 클라우드 스토리지 기술동향
본 장에서는 국내외의 클라우드 스토리지 기술동향을 살펴보고자 한다.
1. 국내 기술동향
국내에서는 인터넷 포털, 클라우드, 통신 사업자 등에서 페타스케일 스토리지 구축 사례가 증가하고 있다.
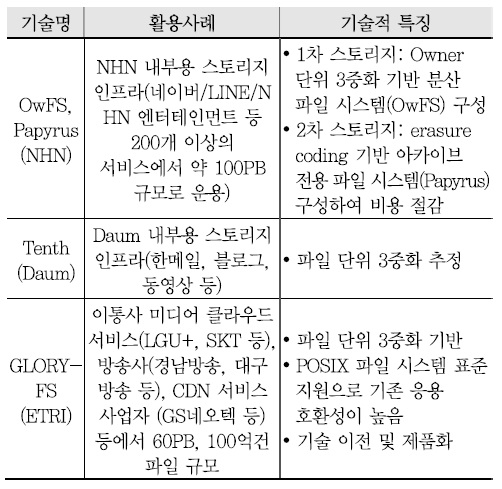
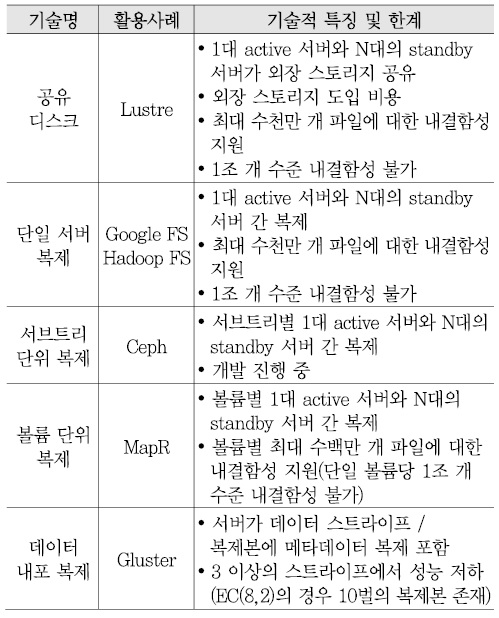
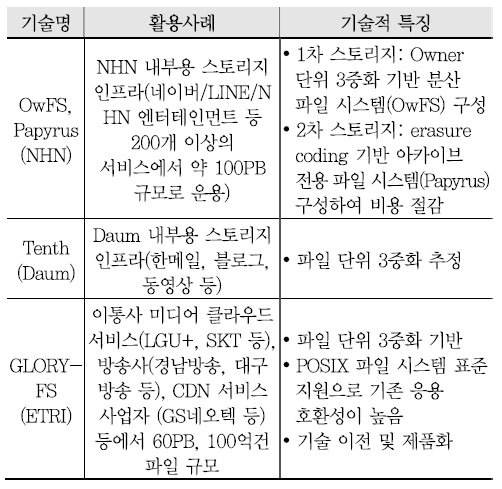
대표적인 인터넷 포털 업체인 NHN, 다음커뮤니케이션즈는 자체적으로 페타바이트 규모를 지원하는 분산 파일 시스템을 개발하여 자사 서비스에 활용하고 있으며, 한국전자통신연구원은 자체 개발한 기술의 보급 및 발전에 힘쓰고 있다. 현재까지 개발된 분산 파일 시스템의 기술적 특징을 비교하면 <표 1>과 같다[6]-[8].
현재까지 국내 분산 파일 시스템은 누적 데이터 규모가 100페타급, 100억개 파일 이상으로 증가함에 따라 독립적인 수십 페타스케일 스토리지를 다수 구축함으로 인한 관리 복잡도 증가, 내결함성 지원을 위한 데이터 3중화에 따른 비용 증가 등의 문제에 직면하고 있다.
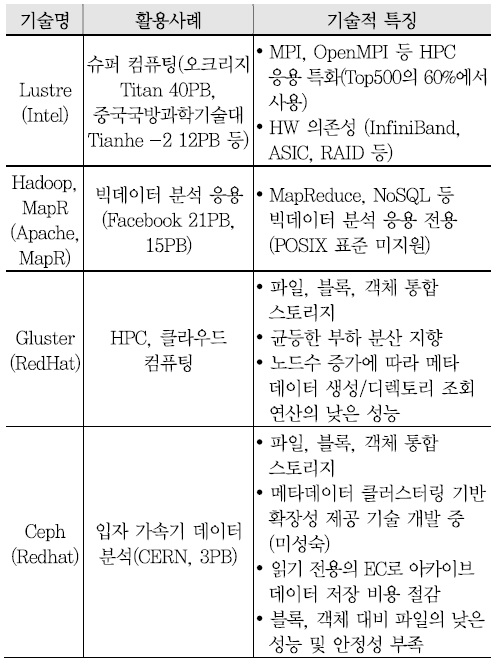
2. 국외 기술동향
Ⅲ. 클라우드 스토리지 확장성 기술분석
클라우드 스토리지는 메타데이터와 데이터가 별도의 노드에 저장/관리되므로 확장성이 지원되기 위해서는 데이터와 메타데이터에 대한 확장성을 동시에 고려하여야 한다. 따라서 본 장에서는 스토리지의 확장성 이슈를 데이터 확장성과 메타데이터 확장성으로 나누어 기술하고자 한다.
1. 데이터 확장성
데이터 확장성의 지원은 성능 저하를 최소화하면서 얼마나 많은 서버들을 연결하여 저장 공간을 확보할 수 있을 것인가와 관련이 있다.
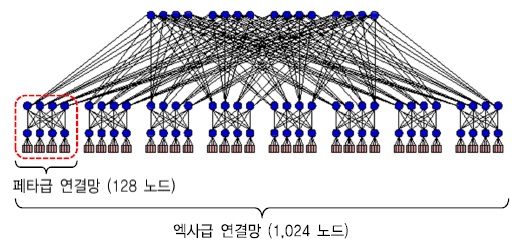
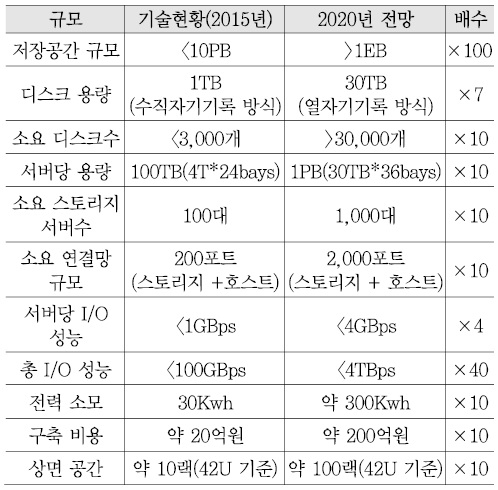
이에 대한 분석을 하기에 앞서, 시스템 규모 확장을 위해서 필요한 구성 요소들이 어느 정도 증가되어야 하는지 이해하기 위해 엑사스케일 스토리지를 지원하는 경우를 고려하여 예측해 보았다[<표 3> 참고].
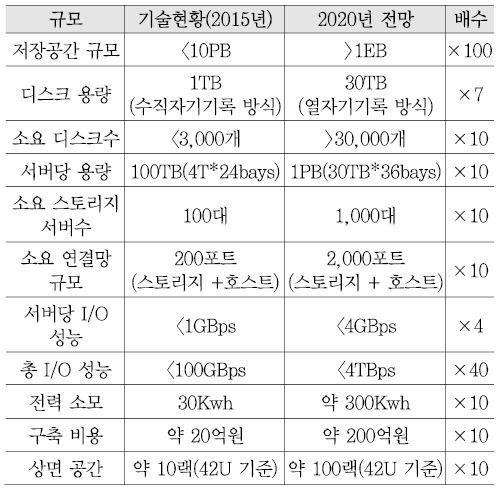
그 결과, 디스크 고용량화를 감안하더라도 10 페타바이트 스토리지 구축에 필요한 서버, 디스크, 연결망의 부품 수와 전력, 공간 등 거의 모든 구성 요소들이 엑사스케일 스토리지를 위해서는 약 10배 이상 증가할 것으로 예상된다.
<표 3>에서 볼 수 있듯이, 수백 노드 정도로 구성되는 페타스케일 연결망의 규모를 대용량화하기 위해서는 노드 수가 천 노드 이상 확장될 것으로 예측되므로 데이터 확장성 지원을 위해서는 그 규모에 적합한 확장성을 갖는 스토리지 연결망 구조가 필수적으로 고려되어야 한다. 또한, 운영비용도 데이터 확장성에 직접적인 영향을 미친다.
그러므로 데이터 확장성에 관한 이슈들은 스토리지 연결망 확장성과 운영비용 부분으로 나누어 분석한다.
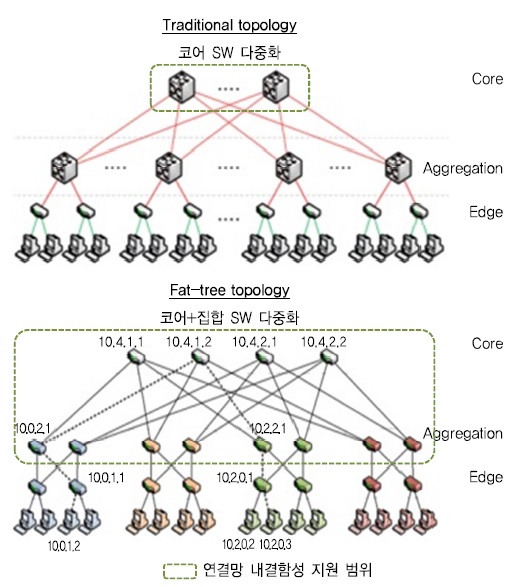
가. 스토리지 연결망 확장성
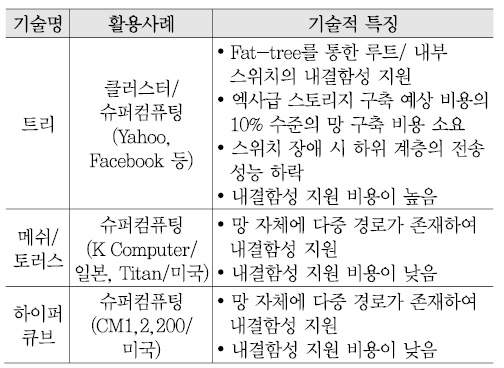
지금까지 페타스케일 스토리지에서는 스위치를 사용한 트리(fat-tree) 토폴로지를 주로 이용해 왔다[14]. 이 토폴로지는 아직까지 스토리지 연결망으로 가장 일반적으로 사용되지만, 사전 규모 예측에 따른 설계가 필수적으로 선행되어야 하며, 페타스케일에서 보다 큰 규모로의 점진적인 확장 등 최초 설계 규모를 벗어난 확장 시 전면적인 트리 재구성에 대한 부담이 발생할 수 있다.
(그림 2)에서는 트리 토폴로지 기반으로 엑사스케일 스토리지를 구성할 경우의 연결망 구성을 예로 도출해 보았다. 그 결과, 36포트 스위치를 가정하더라도 규모 증가에 따른 연결망이 매우 복잡해짐을 알 수 있다.

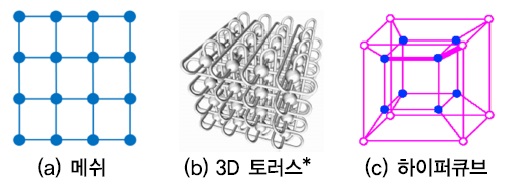
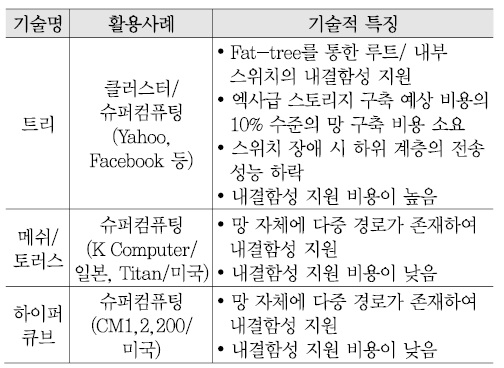
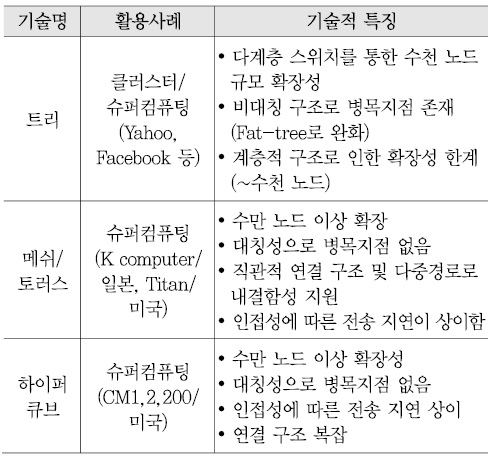
엑사스케일 컴퓨팅 시스템들을 참고하면[3][4], 수천~수만 노드 규모의 연결망 구축 시 트리 토폴로지의 확장성 한계를 극복하기 위한 대안으로 메쉬, 2D/3D 토러스 구조나 하이퍼큐브 토폴로지를 고려해 볼 수 있다 [(그림 3) 참고][15][16].
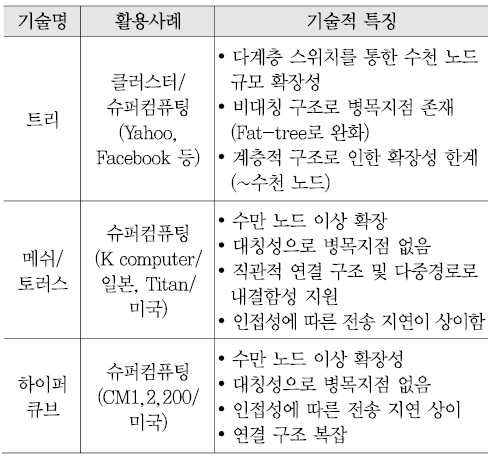
나. 시스템 운영비용
운영비용도 데이터 확장성을 위해서 고려해야 할 중요한 요소이다. 스토리지 시스템의 운영비용은 서버와 스위치를 포함한 구성 요소들의 개수, 차지하는 공간, 사용 전력의 양과 직접적인 관련이 있다.
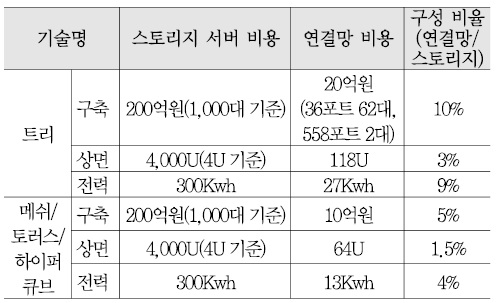
<표 5>는 엑사스케일 스토리지 구축을 예로 들어서 트리와 토러스 토폴로지 기반의 스토리지 서버 구축 비용과 네트워크 구축 비용을 계산해 본 것이다. 스토리지 서버의 수는 <표 3>을 참고하여 4U 크기의 서버 1,000대를 기준으로 하였다.
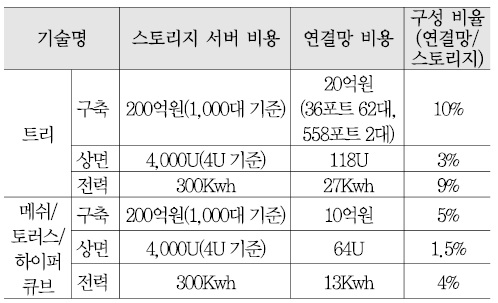
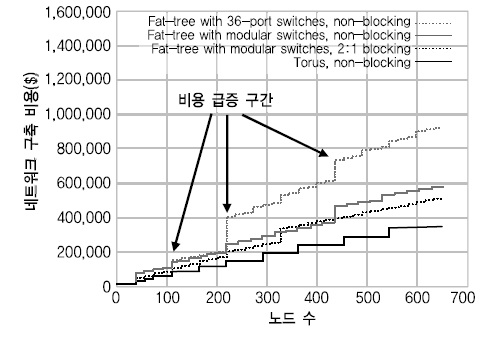
<표 5>를 통해서 알 수 있듯이, 운영비용은 스토리지 연결망에 의해서 큰 차이가 난다. 스토리지 연결망은 스토리지 서버 운영비용의 약 10% 정도로 상당히 큰 비중을 차지하고 클라우드 스토리지의 규모 확장 시에 비용 부담이 발생하기 때문에 더 경제적인 스토리지 연결망 기술을 도입할 필요가 있다. 트리 구조의 대안으로 고려할 수 있는 메쉬, 토러스, 하이퍼큐브 등을 이용하면 연결망 구축 비용을 절반 정도 절감할 수 있을 것으로 기대된다. 단, 이 경우는 인접한 노드만이 직접 통신할 수 있는 토폴로지 한계를 해결하는 기술에 대한 도전이 필요하다.
(그림 4)는 Cluster design에서 제공하는 툴을 이용해 트리와 토러스 토폴로지 상의 노드 수 증가에 따른 비용 증가 정도를 살펴보았는데[17], 토러스 구조에서의 비용이 가장 낮음을 알 수 있다.
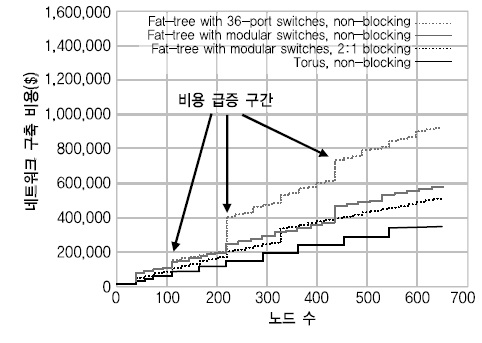
2. 메타데이터 확장성
메타데이터 확장성은 시스템에서 지원 가능한 파일 수와 메타데이터 연산 성능에 의해 표현될 수 있다.
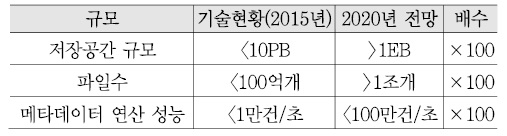
<표 6>은 엑사스케일 스토리지를 구축한다고 가정할 때 현재 기술에 비해 지원해야 하는 파일 수와 메타데이터 연산 성능을 예측해 보았는데, 거의 100배 정도 증가할 것으로 예상된다.
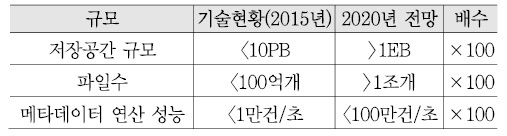
이와 같이, 클라우드 스토리지의 용량이 확장됨에 따라 파일 메타데이터의 개수 및 처리 성능도 비례하여 개선되어야 하는 것은 메타데이터 확장성을 위해서는 기본적으로 해결되어야 하는 이슈이다.
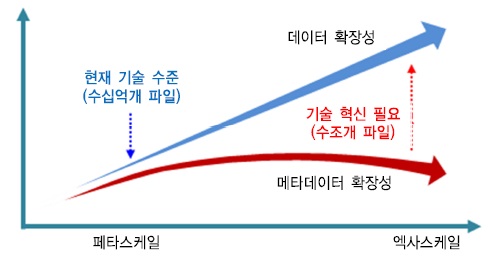
하지만, (그림 5)에서 보는 바와 같이 수십억 개 파일들을 처리할 수 있는 현재의 메타데이터 처리 기술로는 용량의 증가에 따른 메타데이터 처리 성능이 따라가지 못하고, 엑사스케일까지 확장되면 메타데이터 처리가 불가능한 수준이다. 따라서 메타데이터 확장성 지원을 위해서는 기본적으로 이 이슈가 해결될 수 있어야 한다.
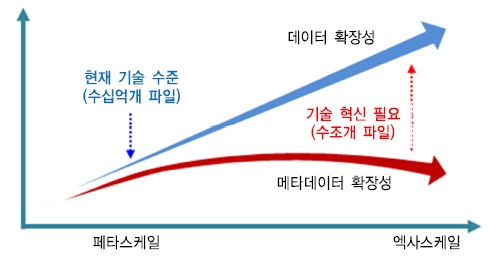
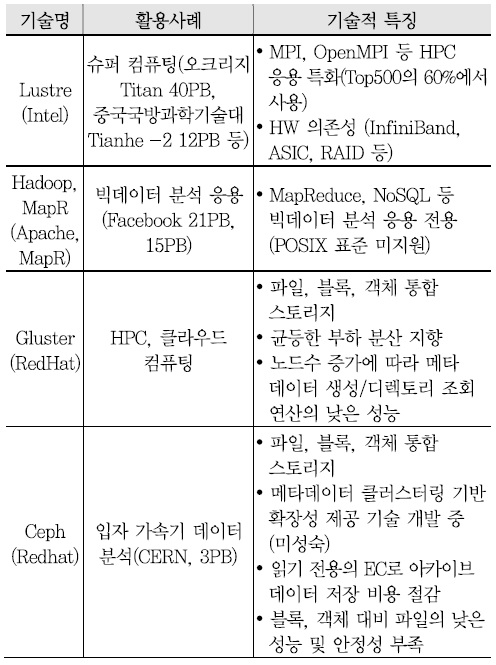
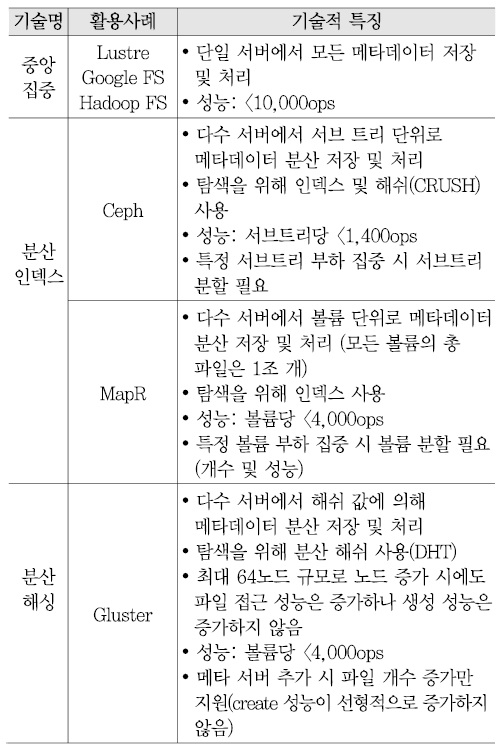
이와 관련된 현재의 메타데이터 확장성 지원 기술들을 살펴보면, 메타데이터 처리 방식은 크게 중앙집중 방식, 분산 인덱스 방식, 분산 해싱 방식으로 나눌 수 있다. 현재의 메타데이터 확장성과 관련한 기술들의 특징 및 한계는 <표 7>과 같다[9]-[13].
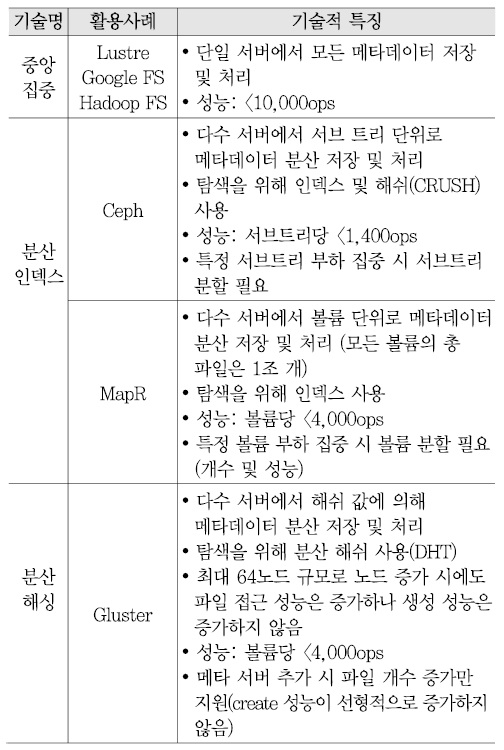
실제로 중앙 집중형 메타데이터 관리 기술과 분산형 메타데이터 관리 기술에 대해 메타데이터 성능 측정을 수행해 보았다. Lustre, Google File System, Hadoop File System 등을 포함한 중앙 집중형 메타데이터 관리 방식에서 단일 메타데이터 서버 구조의 처리 성능은 1,000~10,000ops, 저장 가능한 파일 개수는 수 백만~수 천만 개가 한계인 것으로 나타났다.
그리고 Ceph, Gluster 등과 같은 분산형 메타데이터 관리 방식은 메타데이터 처리 성능과 파일 수를 선형 확장시키는 메타데이터 분산 기술이 시도되었으나 성능 확장성 한계, 파일 누적에 따른 성능 저하, 낮은 완성도 등 기술적인 한계가 존재한다[(그림 6) 참조].

Ⅳ. 클라우드 스토리지 내결함성 기술분석
스케일-아웃 클라우드 스토리지는 구조적으로 내결함성 확보에 어려운 측면이 있다. 스토리지 서버나 디스크를 추가해 줌으로써 저장공간뿐 아니라 성능을 확장시킬 수 있는 것이 구조적인 장점인데 반해 관리 자원의 증가가 장애 지점의 증가로 바로 이어질 수 있는 구조적인 취약성을 동시에 내포하고 있다.
그에 반해 클라우드 스토리지에 대한 신뢰성의 수준은 무정지 서비스를 요구하고 있다. 스케일-아웃 스토리지의 경우 물리적으로 분산 관리되는 데이터, 메타데이터와 이를 전송하는데 필수적인 네트워크에 대한 장애 대처 기능과 성능이 지원되어야 한다. 본 장에서는 현재 페타스케일 스토리지가 지원할 수 있는 내결함 기술 수준을 분석하고, 규모의 증가에 따라 발생 가능한 기술적 이슈와 대처 방안에 대해 기술하도록 한다.
1. 데이터 내결함성
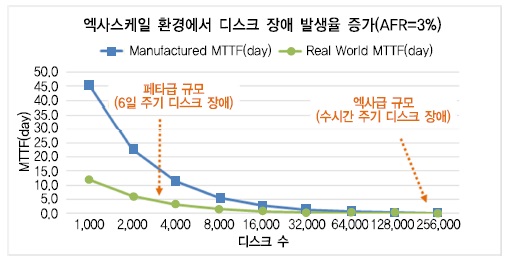
클라우드 스토리지의 규모가 커질수록 디스크 등의 부품 수 증가로 인해 장애 발생 주기(MTTF)가 장애 복구 시간(MTTR)보다 짧아지므로 데이터 내결함성 확보를 위해 비용 대비 효율적인 복구 기술이 요구된다.
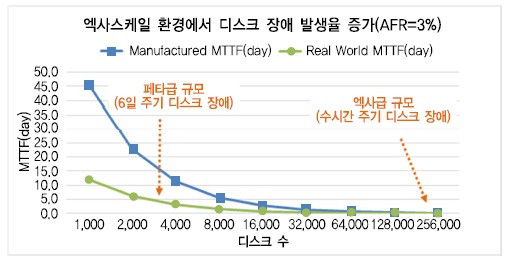
이와 관련하여 연간 디스크 고장율 평균 3%를 적용할 경우 디스크 장애 발생률을 예측해 보면, (그림 7)과 같이 페타스케일 수준은 약 6일에 1회 주기로 발생하지만, 그 주기가 짧아져 엑사스케일 규모까지 확장되면 수 시간 정도의 짧은 주기로 장애가 발생할 것으로 예상된다.
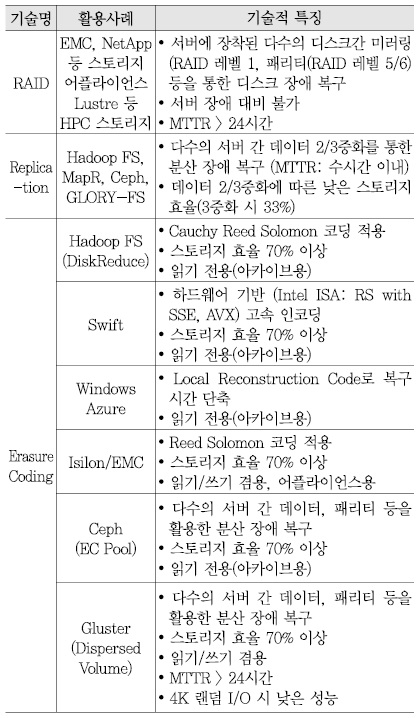
현재의 데이터 내결함성을 지원하기 위한 기술 수준을 조사한 결과는 <표 8>과 같다[10][13][18]-[20].
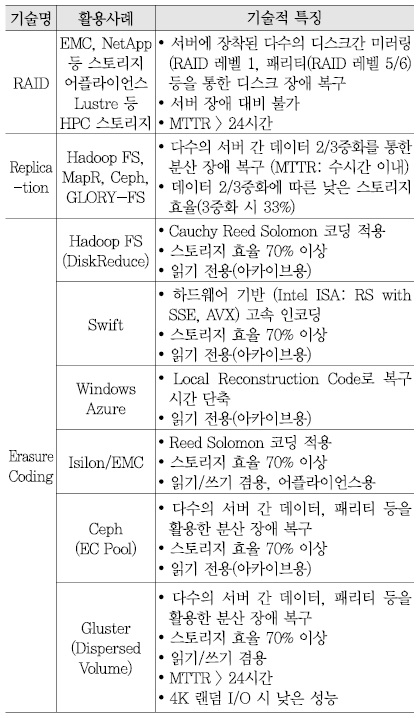
<표 8>을 참고하면, 기존 RAID 기술은 서버 장애에 대비할 수 없고 디스크 고용량화에 따라 평균 디스크 장애 복구 시간이 24시간 이상 걸려 클라우드 스토리지의 규모가 현재보다 커지면 적용이 힘들 것으로 판단된다.
두 번째 방법인 분산 파일 시스템에서 일반적으로 사용하는 복제(replication)는 데이터 3중화에 따른 낮은 스토리지 효율(33%)로 스토리지 구축 비용을 증가시킬 수 있다.
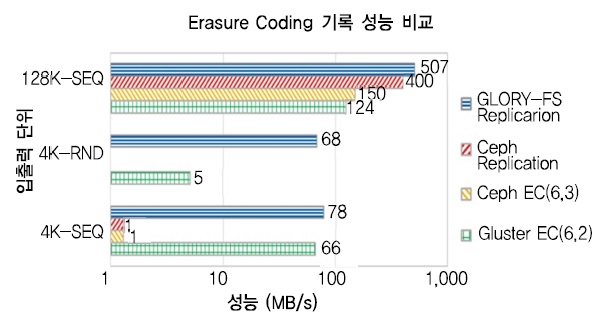
또한, 스토리지 효율을 70% 이상으로 개선할 수 있는 장점 때문에 최근 확산되고 있는 이레이저 코딩(Erasure Coding: EC) 기술은 실제로는 읽기 전용, 낮은 4K 랜덤 I/O 성능, 24시간 이상 평균 장애 복구 시간 등 기술적인 한계를 노출하고 있는 상태이다.
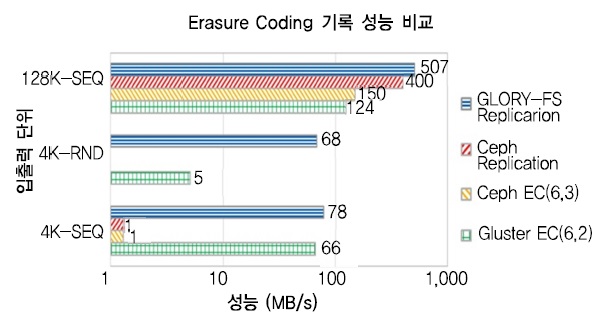
(그림 8)은 EC의 기록 성능을 측정한 결과이다. 복제 방법을 이용하는 GLORY-FS와 비교할 때, Ceph과 Gluster의 EC 기반 성능은 128K 순차, 4K 랜덤, 4K 순차 성능 모두 낮음을 알 수 있다. 특히 4K 랜덤 I/O의 경우에는 EC 기반 성능이 매우 저조하여 EC 기술을 고용량 클라우드 스토리지에 적용하기 위해서는 이 점도 극복되어야 할 대상으로 고려되어야 한다.
2. 메타데이터 내결함성
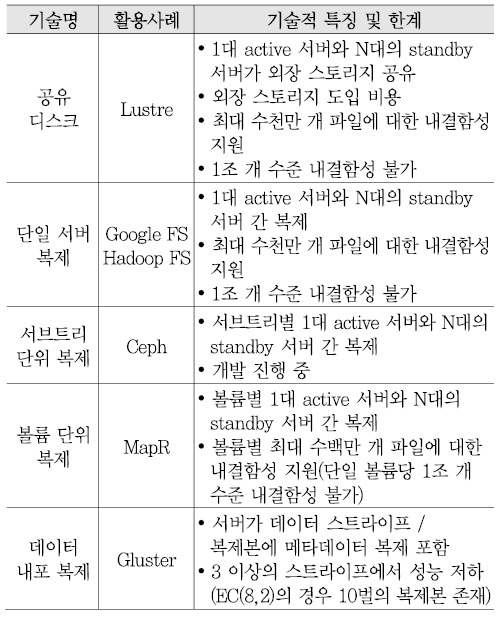
현재 메타데이터 내결함성 지원을 위해서는 공유 디스크 및 복제 기술에 기반하고 있으나, 공유 디스크 도입 비용 절감, 단일 볼륨당 매우 큰 파일 개수(예, 엑사스케일에서는 1조 개 파일) 지원, 성능 저하 최소화 등 기술적인 이슈 극복이 필요하다.
현재의 메타데이터 내결함성 지원과 관련한 기술 수준은 <표 9>와 같다[9]-[13].
<표 8>을 참고하면, active/standby 서버 기반으로 메타데이터가 저장된 외장 스토리지를 공유하는 구조는 메타데이터 서버와 외장 스토리지가 필요하며, 서버 처리의 성능 한계로 최대 수천만 개 파일 이상을 처리하기에는 어려움이 있을 것으로 예상된다. 외장 스토리지 없이 메타데이터를 active/standby 서버 간에 네트워크를 통해 복제하는 여러 방식들이 있으나, 지원 파일 수 제한(최대 수천만 건), 완성도, 성능 저하 등의 한계가 존재한다.
3. 연결망 내결함성
현재의 연결망 내결함성 지원과 관련하여 기술들의 기술적 특징 및 한계는 <표 1>과 같다[14]-[16].
현재 망 연결에 많이 사용되고 있는 트리 토폴로지를 보다 큰 규모의 클라우드 스토리지로 확장할 경우 내결함성을 위해 스위치 다중화 구성이 복잡하며 스위치 장애로 인한 성능 저하 및 접속 단절 범위가 광범위해지는 부담이 있다.
계층 스위치 다중화 구성(fat-tree)을 통해 스위치/링크 장애에 대한 내결함성 확보가 가능하나 다중화로 인한 스위치 개수 증가 및 스위치 장애 시 하위 계층의 성능 저하 혹은 연결 단절 현상 파급 문제가 존재할 수 있다[(그림 9) 참고].
(그림 9)
트리 구조에서의 연결망 내결함성 지원 구조
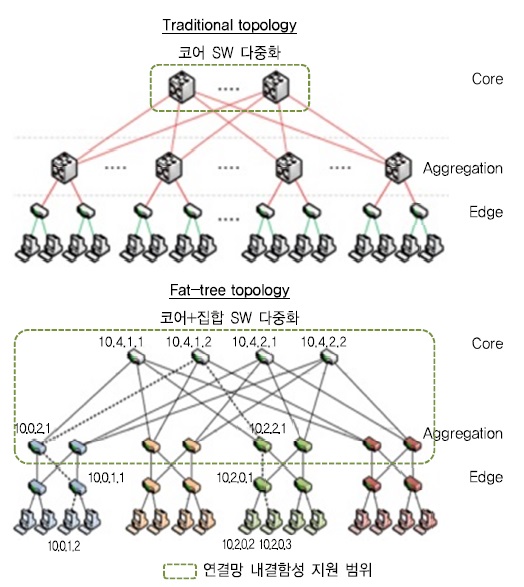
<출처>: M. Al-Fares and et al., “A Scalable, Commodity Data Center Network Architecture,” SIGCOMM, Aug. 2008, http://ccr.sigcomm.org/online/files/p63-alfares.pdf
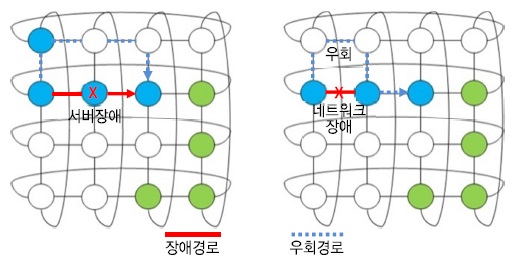
반면, 메쉬, 토러스, 하이퍼큐브 토폴로지에서는 모든 노드가 별도의 네트워크 스위치 없이 인접한 노드와 다차원 방향으로 직결되는 방식으로서, 노드 및 링크 장애 시 추가 비용 없이 인접한 우회 경로를 통한 내결함성 확보가 가능할 것으로 예상된다. (그림 10)의 토러스 토폴로지 구조를 참고하면, 특정 서버나 네트워크 링크에 장애가 발생할 경우 우회 경로 생성으로 내결함성 지원이 가능함을 알 수 있다.
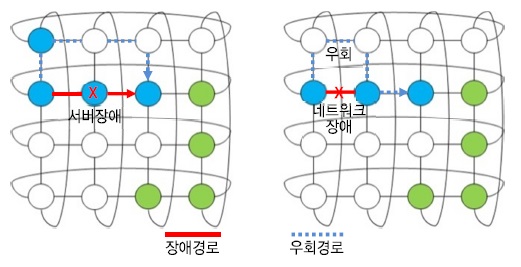
Ⅴ. 결론
본고에서는 클라우드 스토리지 기술 현황 및 스토리지의 대용량화를 위해 극복해야 할 기술적 이슈들에 대해 분석하였다.
현재 클라우드 스토리지의 기술은 페타스케일의 단계까지 와 있고, 국내외적으로는 GLORY-FS, OwFS, Lustre, Hadoop 등 구축 사례들도 많이 있다. 그러나 소셜, 모바일, IoT 등에 의한 기하급수적인 데이터 증가 속도 및 이에 대한 효율적인 저장과 처리의 필요성에 의해 규모가 더 큰 클라우드 스토리지에 대한 요구가 발생되고 있다.
이러한 클라우드 스토리지의 대용량화는 전력, 비용, 성능 등을 포함하여 현재 많이 구축되고 있는 페타스케일 스토리지에 사용되는 기술로는 그 한계에 직면해 있다. 본고에서는 그러한 기술 요소들의 한계성에 대해 분석해 보았다.
클라우드 스토리지 구성 기술 요소들의 혁신을 통한 고용량화된 클라우드 스토리지는 모바일, 소셜, 빅데이터, IoT 각 분야에서 융합 수요를 창출할 것으로 예상되며, 산업 분야의 데이터 저장 플랫폼으로서 다양한 서비스 산업을 창출할 수 있는 견인차 역할을 할 것으로 예상된다.
또한, 이러한 상황에서 모바일, 빅데이터, IoT, UHD 등 기술들의 발전으로 향후 폭증하게 될 데이터를 효율적으로 저장할 수 있는 세계 최고의 기술적 해결책을 확보하는 것은 매우 중요할 것이다. 또한 국가적으로 요구되는 환경, 안전, 우주, 의료, 복지, 국방 등을 위해 국가적으로 요구되는 데이터 저장 플랫폼 기술을 확보함으로써 국가 ICT 기술 경쟁력을 제고할 수 있고 관련 분야의 ICT 기술들의 동반 성장에 기여할 수 있을 것으로 예상된다.
용어해설
분산 파일 시스템 복수 개의 서버들을 네트워크로 연결하여, 사용자들에게 같은 파일 접근 공간을 제공해 주는 시스템
스케일-아웃 방식 시스템을 구성하기 위해 접속된 서버의 대수를 늘려 서버 처리 능력을 향상시키는 방식
클라우드 스토리지 인터넷을 통해 데이터를 저장, 액세스하고 공유하는 스토리지 시스템으로서, 스토리지 인프라를 유지 관리하는데 드는 비용이 필요 없고 어디서나 데이터 액세스가 가능함.
약어 정리
J. Gantz and D. Reinsel, “Digital Universe in 2020: Big Data, Bigger Digital Shadow, and Biggest Growth in the Far East-United States,” IDC, Feb. 2013.
Gartner, “Gartner Says the Internet of Things Installed Base Will Grow to 26 Billion Units by 2020,” Dec. 12th, 2013, http://www.gartner.com/newsroom/id/2636073
Greenrushwars, “K Computer and Exascale Computing: The New Wave,” Jan. 20th, 2014, http://wondergressive.com/k-computer-exascale-computing/
OLCF, “Titan: Paving the Way to Exascale,” 2011, https://www.olcf.ornl.gov/wp-content/uploads/2011/10/ Titan_PavingTheWay_10-6-11.pdf
J. Shalf, S. Dosanjh, and J. Morrison, “Exascale Computing Technology Challenges,” VECPAR, LNCS, vol. 6449, 2011, pp.1-25.
윤석찬, “실시간 빅데이터 기술 현황 및 Daum 활용 사례 소개,” 다음커뮤니케이션즈, http://www.nexr.co.kr/upload/ bigdata_daum.pdf
SUN Microsystems, “Lustre File System: High-Performance Storage Architecture and Scalable Cluster File System,“ White Paper, Dec. 2009.
Hadoop, “HDFS Architecture Guide,” Apache Software Foundation, https://hadoop.apache.org/docs/r1.2.1/hdfs_ design.html#Introduction
Gluster, “Cloud Storage for the Modern Data Center: An Introduction to Gluster Architecture, ” http://moo.nac.uci.edu/~hjm/fs/An_Introduction_To_Gluster_ArchitectureV7_110708.pdf
S.-A. Hamid, “Performance Analysis of Wormhole Routing in Multicomputer Interconnection Networks,” Ph.D thesis, University of Glasgow, 2001.
F. Harary, J.P. Hayes, and H.-J. Wu, “A Survey of the Theory of Hypercube Graphs,” vol.15, no.4, Computer & Mathematics and Applications, 1988, pp. 277-289.
H. Weatherspoon, “Data Center Network Topologies: FatTree,” 2014, http://www.cs.cornell.edu/courses/cs5413/ 2014fa/lectures/08-fattree.pdf
Azure, “Microsoft Azure: Cloud Computing Platform and Services,” https://azure.microsoft.com/en-gb/
(그림 1)
2020년 디지털 데이터 생산량 예측
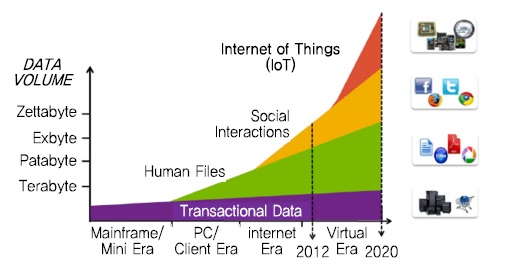
<출처>: Dell, “Dell Solutions Tour 2013,” Sept. 2013, http://www.slideshare.net/dellenterprise/dell-solution- tour-copenhagen.
(그림 3)
확장성 제공 가능한 네트워크 토폴로지 대안들
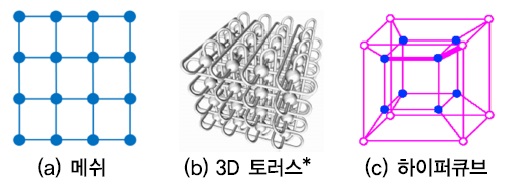
* <출처>: RIKEN, Fujitsu, Limited, ”Japan's Next-Generation Supercomputer Configuration is Decided: Architecture Based on Scalar System,” July 2009, http://www. fujitsu.com/global/about/resources/news/press-releases/2009/0717-01.html
(그림 6)
노드 수 증가에 따른 Gluster의 분산 메타데이터 성능

<출처>: Gluster, “Gluster Scale-Out Tests: An 84 Node Volume,“ May 9th, 2014, http://blog.gluster.org/2014/05/ gluster-scale-out-tests-an-84-node-volume/
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.