인공지능 컴퓨팅 프로세서 반도체 동향과 ETRI의 자율주행 인공지능 프로세서
Trends in AI Computing Processor Semiconductors Including ETRI's Autonomous Driving AI Processor
- 저자
-
양정민프로세서연구그룹 jmyang38@etri.re.kr 권영수프로세서연구그룹 yskwon@etri.re.kr 강성원지능형반도체연구본부 kangsw@etri.re.kr
- 권호
- 32권 6호 (통권 168)
- 논문구분
- 4차 산업혁명 선도를 위한 ICT소재부품기술 특집
- 페이지
- 57-65
- 발행일자
- 2017.12.01
- DOI
- 10.22648/ETRI.2017.J.320607
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- Neural network based AI computing is a promising technology that reflects the recognition and decision operation of human beings. Early AI computing processors were composed of GPUs and CPUs; however, the dramatic increment of a floating point operation requires an energy efficient AI processor with a highly parallelized architecture. In this paper, we analyze the trends in processor architectures for AI computing. Some architectures are still composed using GPUs. However, they reduce the size of each processing unit by allowing a half precision operation, and raise the processing unit density. Other architectures concentrate on matrix multiplication, and require the construction of dedicated hardware for a fast vector operation. Finally, we propose our own inAB processor architecture and introduce domestic cutting-edge processor design capabilities.
Share
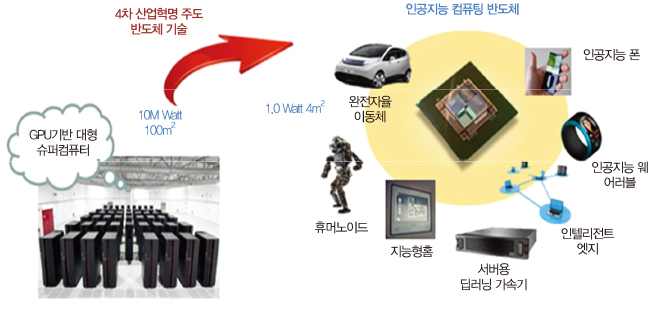
Ⅰ. 서론: 인공지능 반도체 기술 개발 필요성
인간은 대화와 집안일, 기계 정비 등을 도맡아 하는 스타워즈의 C-3PO를 시작으로 의체(義體)와 전뇌(電脳)를 기반으로 미래 사회의 치안을 담당하는 공각기동대의 쿠사나기 소령을 지나, 네트워크와 두뇌의 연결로 초연결, 초자아 상태로 발전한 트랜센던스의 윌 캐스터까지 각종 미디어를 통해 인공지능 반도체 기술에 대한 상상을 해왔다. 인간의 명령과 그에 대응하는 단순 동작을 수행해왔던 컴퓨터는 스스로 학습하고 새로운 연결을 강화하는 방식으로 아키텍처의 패러다임을 전환하였다. 우리는 이러한 변화를 인간의 자존심을 무너뜨린 ‘알파고’라는 인공지능 프로그램을 통하여, ‘대부분 인류가 예상하였던 것보다 이른’ 2016년에 경험하였다. 그리고 이러한 인공지능 기술의 중심에는 인공지능 반도체가 있다.
인공지능 반도체는 대량의 입력 정보를 이용하여 서비스에 최적화된 사고 및 추론, 행동 및 동작을 구현한다. 이 인공지능 반도체 기술에 다층신경회로망(MLP: Multi-layer perceptron)과 신경망 회로(Neural net)의 개념이 도입되면서 인공지능 기술의 응용 분야가 다양화, 다변화되기 시작했다[(그림 1) 참조]. 지능형 개인서비스를 위한 디바이스(모바일 기기, 지능형 스마트폰 등), 자율이동체(자율주행 자동차, 자율이동형 드론, 물품 수송), 서버형 딥러닝 가속기, 지능형 헬스케어(인공지능 의사, 원격 진료, 웨어러블 헬스케어 기기), 군용장비(무인비행체, 탐지형 로봇), 사회 서비스(금융-예측서비스, 범죄 감시) 등, 인공지능에 의한 기술 혁신은 ICT 소재부품 분야의 질서를 바꿔놓을 것이 자명하다. 하지만 모든 반도체 부품 분야가 그러했듯, 인공지능 반도체 기술도 상용화 과정에 있어 성능과 전력이라는 기술 병목을 안고 있다.
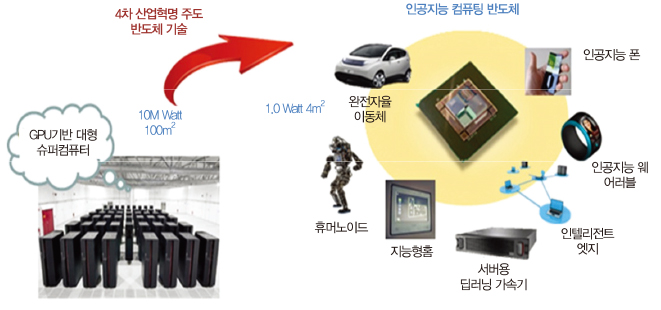
인공지능 컴퓨팅의 태동기에는 성능 문제를 해결하기 위해 대량의 CPU(Central processing unit), GPU(Graphics processing unit) 기반 분산 컴퓨팅 기법이 활용되었다. 하지만 인공지능 컴퓨팅에 요구되는 연산량의 급증은 기존 CPU, GPU 기반 아키텍처가 수용할 수 있는 범위를 벗어나 기존의 폰-노이만 아키텍처에 위협을 가하고 있다. 딥러닝이 적용된 인공지능은 현재 개발된 가장 빠른 모바일 프로세서의 약 1,000배 이상의 성능을 요구하며, 이를 기반으로 만들어진 몇몇 기업의 음성비서 제품은 수 킬로와트 이상의 전력을 소모해 상용화에 어려움을 겪고 있다. 설상가상으로 지난 수십 년간 반도체 산업의 발전을 지배해왔던 ‘무어의 법칙(Moore’s law)’은 7nm 수준의 반도체 제작 공정 스케일링(Technology scaling)의 물리적 한계에 부딪히며, 현재 발전이 정체된 상황이다[1].
이 문제를 해결하기 위해 학계와 산업계에서는 다양한 방식의 접근 방법을 제시하고 있다. 인공지능 컴퓨팅을 위한 인공지능 가속 프로세서 아키텍처, 초병렬 프로세서, 뉴로모픽 디바이스, 3D integration, PIM(Processing in memory) 등이 그것이다. 다음 장에서는 이러한 인공지능 컴퓨팅 가속 및 초병렬 프로세서와 관련된 국내외 기술 동향을 분석하고, ETRI의 본 연구그룹에서 설계 중인 인공지능 전용 프로세서 inAB(Intelligent Aldebaran)의 아키텍처에 대해 간략히 설명할 것이다. 마지막으로 국내 소재부품산업의 인공지능 반도체 기술 혁신에 대한 대응 전략에 대해서도 언급할 것이다.
Ⅱ. 해외 인공지능 반도체 기술 동향
1. 병렬 컴퓨팅 반도체
병렬 컴퓨팅 기술은 반도체의 공정 스케일링의 한계에 따른 성능정체를 극복하기 위해 2000년대 초부터 주목받기 시작했다. 현재 정부 차원의 정책적인 지원을 바탕으로 글로벌 기업의 매니코어 프로세서 기술 선점을 위한 연구가 활발히 진행되고 있다. 특히 중국은 정부 차원의 장기 기술 개발 지원의 좋은 예로, 최근 CAS(국가과학원, Chinese academy of science)를 중심으로 자체 개발한 매니코어 프로세서 SW26010을 적용한 슈퍼컴퓨터 ‘Taihulight’를 발표하였다[(그림 2) 참조].
(그림 2)
SW26010[2]

[출처] J. Dongarra, “Report on the Sunway TaihuLight System,” University of Tennessee, Tech Report UT-EECS-16-742, June 2016.
SW26010은 SMIC 공정에서 1.4GHz의 동작주파수를 목표로 64-bit RISC(Reduced instruction set computer) processor ISA(Instruction set architecture)를 개발한 Jiangnan Computing Lab과, 이를 기반으로 260코어 아키텍처 및 반도체를 설계한 National High Performance Integrated Circuit Design Center의 공동 개발로 진행되었다.
SW26010을 40,960개 장착한 Sunway Taihulight 슈퍼컴퓨터는 93.01 PFLOPS(Floating point operations per second)의 성능을 지니고 있으며[3], 2016년 기준 전 세계에서 가장 성능이 좋은 슈퍼컴퓨터로 평가되었다.
2. DNN 가속 가속 반도체
가. NVIDIA
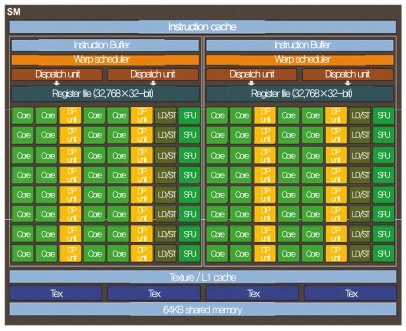
2000년대 초반, 기하 셰이더(Geometry shader)와 픽셀 셰이더(Pixel shader)의 개념을 처음으로 도입한 NVIDIA는 통합 셰이더(Unified shader)로 전 세계 그래픽스 시장을 장악하였다. 당시의 원천 기술은 다수의(Many) 작은(Small) 코어를 L1 캐시와 L2 캐시로 상호 연결한 아키텍처와 프로세서 기술이었다. 2000년대 중반부터는 그래픽스 처리 중심의 프로세서에서 매니코어 구조와 GPU 구조를 기반으로 한 GPGPU(General-purpose computing on graphics processing units) 개념을 발전시켰으며, 이를 기반으로 다양한 어플리케이션에 GPU 아키텍처를 적용하기 시작했다. 특히 DNN(Deep neural network)의 경우 방대한 연산량에 비해 각각의 연산은 복잡도가 높지 않고 반복적이기 때문에, GPU 기반 아키텍처의 높은 병렬성을 이용하여 효율적인 연산이 가능하다[(그림 3) 참조].
(그림 3)
파스칼 SM 아키텍처[4]
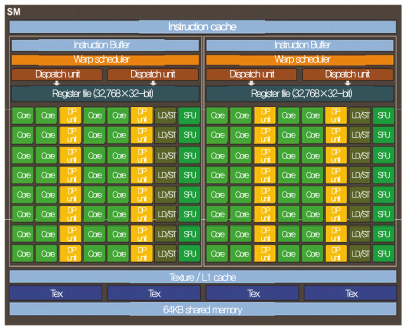
[출처] NVIDIA Corporation, “NVIDIA Tesla P100 whitepaper,” WP-08019-001-__v01.1, 2016, pp. 1–45.
최근에 개발된 파스칼 아키텍처는 기존 맥스웰(GM200)에서 24개였던 SM(Streaming multiprocessor) 수가 56개(GP100 기준)로 늘어나 부동소수점 계산에 강점을 보인다[4]. Single-precision, Double-precision 부동소수점 연산 성능은 각각 10.6TFLOPS, 5.3TFLOPS로 맥스웰 대비 1.5배 향상됐으며, DNN 연산에 널리 쓰이고 있는 Half-precision 연산 성능은 21.1TFLOPS로 개선되었다.
NVIDIA는 자사의 그래픽스 처리 프로세서(GPU) 기술을 기반으로 ADAS(Advanced driver assistance system) 프레임워크인 NVIDIA DRIVETM PX2를 개발하였으며, 이를 자율주행 SW 개발 장비인 DriveWorks에 이용하면 차량과 자전거, 보행자 등을 인식하고 구별할 수 있다. 또한, NVIDIA는 GPU Technology Conference Europe에서 자율주행차량용 AI super-computer chip인 Xavier를 발표하여 소비 전력 감소에 대한 NVIDIA의 기술 혁신 야심도 드러냈다. Xavier는 512개의 코어로 구성된 Volta architecture 기반의 GPU, 8개의 코어로 구성된 Custom ARM64 CPU, 새로운 CVA(Computer vision accelerator), 그리고 Dual 8K HDR를 지원하는 Video processor를 통합하여 20TOPS(Trillion operations per second)의 성능과 20W 소비 전력을 달성하였다.
나. Google
구글은 SW 및 빅데이터 센터 기반으로 인터넷 서비스를 전문으로 하는 기업이지만, 자사의 빅데이터 센터에 사용되는 서버를 기반으로 인공지능 등에 필요로 하는 특수 서비스의 필요성이 증대되면서 2015년부터 프로세서 반도체를 개발하기 시작했다.
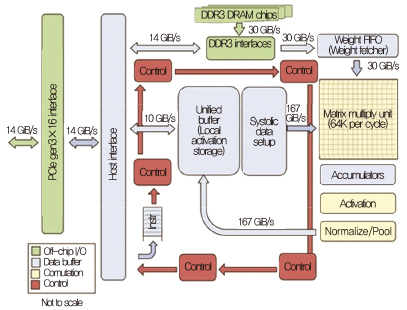
최근에는 DNN리서치(DNN research), 딥마인드(DeepMind), 무드스톡(Mood stocks) 등 머신러닝 기술 기업을 인수하여 내부 역량을 쌓아왔으며, 2016년 3월 구글 딥마인드 챌린지 매치에서 인공지능(알파고)이 바둑에서 프로기사를 처음으로 이기는 성과를 거두었다. 특히 CPU나 GPU 등 기존 프로세서에 기반을 둔 아키텍처로 예상되었던 알파고가 사실은 행렬 연산 처리를 위해 개발된 TPU(Tensor processing unit)임을 공개[5]함으로써, 기존 GPU보다 효율적인 딥러닝 가속 반도체 아키텍처를 제시하였다는 점에 의의가 있다[(그림 4) 참조].
(그림 4)
TPU 아키텍처[5]
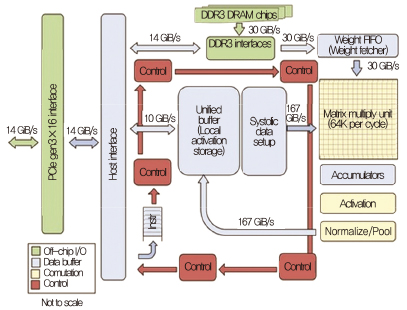
[출처] N.P. Jouppi et al., “In-datacenter Performance Analysis of a Tensor Processing Unit,” Int. Symp. Comput. Archit. (ISCA), Toronto, Canada, June 24–28, 2017, pp. 1–12.
다. Intel, Nervana, Movidius
인텔은 모바일 시장에서 실패한 이후, 대형, 고속의 데이터 센터 서버용 프로세서에 집중하여 다양한 프로세서 제품군을 생산 중이다. 2016년에 공개한 제온 파이(Xeon Phi) 7200 시리즈는 MIC(Many integrated core) 아키텍처로 칩 하나에 64~70개 이상의 코어를 탑재해 병렬 처리 속도를 높였으며 프로세서 하나에 3TFLOPS의 성능을 가진다.
이와 별개로 인공지능 반도체 시장 진출을 위하여 2015년에는 FPGA(Field programmable gate array) 선두 제조 업체인 알테라(Altera), 2016년에는 인지컴퓨팅 업체 사프론, 비전 프로세싱 솔루션 업체 모비디우스, 딥러닝 전문업체 너바나(Nervana) 등을 인수하였다.
너바나는 부동소수점 컴퓨팅 아키텍처 정밀도의 동적 변화에 의한 초병렬의 컴퓨팅을 목표로 설립되었으며, 인수되기 전 Nervana Engine 프로세서와 Python 기반 딥러닝 프레임워크인 Neon을 개발하였다.
Neon은 Assembler-level 최적화, Multi-GPU 지원과 Data flow 최적화를 통해 Theano, Caffe와 같은 다른 딥러닝 프레임워크와 비교하여 2배 이상 빠른 성능을 달성하였다. 이러한 Neon의 가속화를 위해 개발된 것이 딥러닝 ASIC(Application specific integrated circuit)인 Nervana Engine이며, HBM을 이용한 3D memory stack과 Interposer 기술을 이용한 빠른 외부 메모리 접근이 장점이다.
동적으로 정밀도를 바꿀 수 있는 FlexPoint 기술, 병렬화를 높이기 위한 Pipeline isolation, 칩 간 통신 병목 해결을 위한 6 bi-directional high-bandwidth links를 통해 NVIDIA의 Maxwell 기반 Titan X보다 10배 더 빠르게 수행할 수 있다.
인텔은 이러한 너바나의 기술을 기반으로 2017년 상반기에 코드명 레이크 크레스트(Lake Crest) 프로세서를 출시할 예정이며 너바나의 기술을 부팅 가능한 제온 프로세서에 결합한 나이츠 크레스트(Knights Crest)를 후속으로 출시할 예정이다.
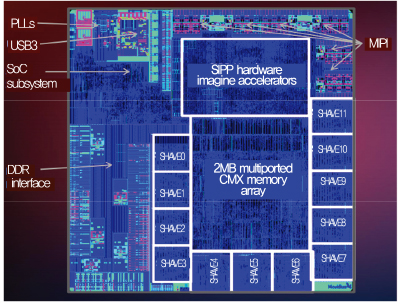
Movidius는 2010년을 전후로 뉴럴넷 가속을 위한 멀티코어 프로세서를 연구를 지속해왔으며, ISAAC, Myriad 1 개발을 기반으로 2016년 2월 Manycore vision processing unit인 Myriad 2 발표 후 인텔에 인수되었다.
Myriad 2는 특정 비디오 처리 작업을 가속하기 위한 Atomic imaging/vision engine으로, Multi-ported scratched memory인 Intelligent memory fabric, 128-bit vector VLIW(Very long instruction word) processor인 SHAVE(Stream hybrid architecture vector engine), UltraSPARC ISA processors를 기반으로 Heterogeneous architecture로 설계되었다. 개발된 칩은 TSMC 28nm HCMOS LP process로 제작되어 1W의 전력을 소모하며 80~150GFLOPS의 Video processing 컴퓨팅 성능을 달성하였다[6]. 이를 기반으로 모바일 단말기, HMD(Head mounted display) 등에서 활용이 가능한 SW 개발 장비과 Vision application을 제공한다[(그림 5) 참조].
(그림 5)
Myriad2 chip micrograph[6]
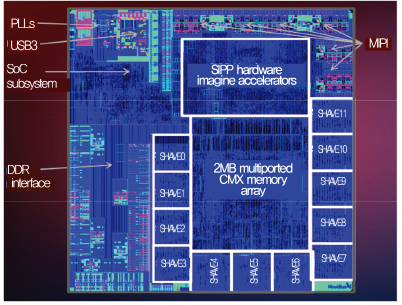
[출처] D. Moloney et al., “Myriad 2: Eye of the Computational Vision Storm,” Hot Chips Symp., Cupertino, CA, USA, Aug. 10–12, 2014.
라. Qualcomm
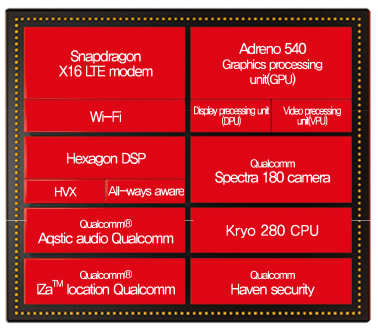
퀄컴은 뉴로모픽칩인 NPU(Neural processing unit) 제로스(Zeroth)를 스냅드래곤 820에 내장하여 출시하였으며, 2016년에는 제로스 플랫폼을 지원하는 스냅드래곤 뉴럴 프로세싱 엔진 SDK를 개발 배포하였다. 이후 공개된 스냅드래곤 835에는, 크라이요 280 CPU, 아드레노 540 GPU, 헥사곤 682 DSP등이 포함되어, 단말기에서의 인공지능 컴퓨팅을 지원하였다[7], [(그림 6) 참조]. 최근에는 Nauto와 협력하여 Zeroth를 이용한 차량용 인공지능 센서를 개발하고 있다.
(그림 6)
Snapdragon 835 아키텍처[8]
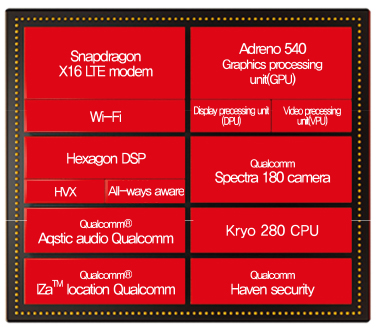
[출처] M. Humrick and R. Smith, “The Qualcomm Snapdragon 835 Performance Preview,” Anandtech, 2017. 3. 22.
마. IBM
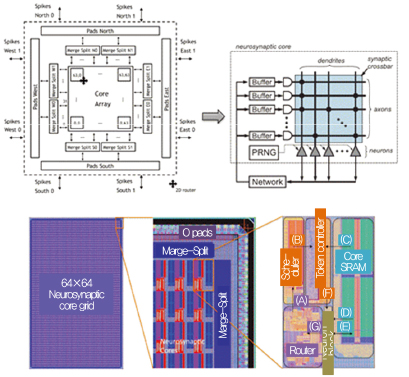
IBM의 TrueNorth는 SNN(Spiking neural net)의 개념을 최초로 CMOS로 구현한 매니코어 또는 병렬엔진 프로세서이다. DARPA(미국 방위고등연구계획국, Defense Advanced Research Projects Agency)는 SyNAPSE(Systems of Neuromorphic Adaptive Plastic Scalable Electronics) 프로젝트를 통해 포유류의 뇌를 모방한 전자두뇌 시스템 개발을 시작하였고, IBM은 SyNAPSE 프로젝트 후속으로 SRAM 어레이를 시냅스 모방 소자를 활용한 TrueNorth를 개발하였다. TrueNorth는 총 256M의 synapse가 집적되어, 1kHz tick을 이용한 동작에서 65mW의 전력 소모, 최대 58 GSOPS의 성능을 달성하였다[9]. 미국의 LLNL(Lawrence Livermore National Laboratory)에서는 16개의 TrueNorth array를 기본 단위로 하는 데이터센터를 구성하는 프로젝트를 진행 중이다[(그림 7) 참조].
(그림 7)
TrueNorth, Neurosynaptic Core 아키텍처[9]
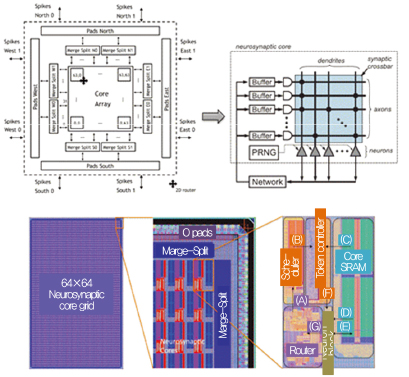
[출처] Y. Chen et al., “DianNao Family: Energy-Efficient Hardware Accelerators for Machine Learn-ing,” Commun. ACM, vol. 59, no. 11, Nov. 2016, pp. 105-112.
삼성전자에서는 TrueNorth를 기반으로 기존 스마트폰 AP보다10%의 전력으로 손동작을 인식하는 데 성공하였으며, Dynamic vision sensor에도 적용하여 1초에 2,000 frame의 이미지 패턴 인식에 성공하였다.
바. CAS
중국 CAS에서는 딥러닝 가속을 위해 DianNao 시리즈를 개발하였다. DianNao는 메모리의 성능 및 소모 에너지 최적화에 중점을 둔 CNN 및 DNN 가속기로, 128-bit 2GHz SIMD(Single instruction multiple data) processor보다 117.87배 빠른 연산성능과 21.08배 향상된 에너지 효율을 달성하였다. 또한, DianNao를 Multi-chip으로 확장하여 NVIDIA K20M GPU에 비해 450.65배의 연산성능 150.31배의 에너지 효율을 가지는 DaDianNao를 발표하였다. 이후에도 다양한 머신러닝 기법을 지원하는 PuDianNao, CNN 기반 이미지 처리에 특화된 ShiDianNao도 제안하였다[10].
한편 Instruction set 수준의 유연성 및 효율성을 위해 신경망 가속기를 위한 ISA cambricon도 개발하여, 코드 길이를 GPU, x86, MIPS에 비해 각각 6.41배, 9.86배, 13.38배로 압축하였다[11], [(그림 8) 참조].
(그림 8)
Cambricon chip micrograph[11]

[출처] S. Liu et al., “Cambricon: An Instruction Set Architecture for Neural Networks,” Int. Symp. Comput. Archit. (ISCA), Seoul, Rep. of Korea, June 18–22, 2016, pp. 393–405.
Ⅲ. inAB 프로세서 아키텍처
1. 기반기술과 기술 개발 방향
본 연구 그룹은 2006년부터 순수 국내 기술 기반의 프로세서 설계 및 아키텍처 연구에 매진해왔다. 그 결과로 개발된 것이 알데바란 프로세서(Aldebaran processor) 시리즈로, 각 세대에 따라 초저전력 기술, 매니코어 기술 등을 업그레이드하였다.
2006년 개발된 초소형 신호처리 프로세서(EMP)는 알데바란 프로세서의 모태가 되는 프로세서로서, 영상, 음성 등의 신호를 효율적으로 처리하기 위한 저전력 초소형 프로세서와 컴파일러, 임베디드 SW로 구성된다. EMP는 기술이전을 통해 다수의 양산품이 개발되어 그 성능을 검증받음과 동시에 국내 프로세서 기술 개발 부활의 신호탄이 된다.
2010년 개발된 에너지 스케일러블 벡터 프로세서(ESVP)는 세계 최고 수준의 에너지 효율성을 자랑하는 확장 가능한 벡터 프로세서로서, 옥타코어급 에너지 자율제어형 모바일 멀티 프로세서 기술과 병렬 컴파일러 원천 기술 확보에 큰 역할을 하였다.
이후 개발된 AB3, AB5 시리즈는 위 EMP와 ESVP를 기반으로 프로세서 아키텍처 독자 개발된 프로세서로써 초미세 공정(28nm)에서의 동작을 검증하였다. 특히 AB5 프로세서는 매니코어, 영상처리 IP, 특징점 추출 등 기능을 통합하였으며, ISO 26262 기능 안정성 기준을 만족하는 자율주행 차량용 프로세서이다.
상술한 인공지능 프로세서 개발을 위한 매니코어프로세서 아키텍처, 저전력 컴퓨팅 설계 등의 원천 기술은 본 연구그룹에 의해 모두 독자 개발되었으며, 양산화 과정을 통해 동작과 안정성을 검증하였다.
2. inAB 프로세서
본 연구그룹에서 개발 중인 인공지능 프로세서 반도체 inAB는 2006년부터 개발해온 알데바란 프로세서를 기반으로 저전력, 초병렬 컴퓨팅 구현을 목표로 하고 있다.
가. 지능 정보 매니코어 프로세서 아키텍처
지능 정보 매니코어 프로세서는 하이퍼바이저 SW와 연동된 메인 프로세서와 ABSTC(병렬 나노코어, Aldebaran systolic core), 인터페이스로 구성된다.
메인 프로세서는 비정규성 알고리즘 코드를 구현할 수 있는 범용 프로세서 형태로 구성되며, 다양한 뉴럴넷 알고리즘을 효과적으로 동작시키기 위한 하이퍼바이저 SW와 연동하여 동작한다. 병렬 나노코어(ABSTC)는 정규성 알고리즘을 효율적으로 실행하기 위한 아키텍처로서, 배열형태의 나노코어와 효과적인 데이터 운용을 위한 버퍼 및 컨트롤러로 구성된다. 이 사이의 인터페이스는 다양한 시스템과의 범용성을 유지하면서 고속 동작이 가능한 시스템으로 구성하였다.
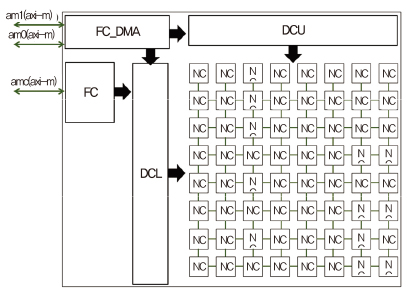
나. 병렬 나노코어(ABSTC) 아키텍처 설계 기술
병렬 나노코어 아키텍처는 다수의 나노코어를 배열 형태로 집적하고 데이터를 병렬 공급함으로써 뉴럴넷을 위한 산술연산을 동시다발적으로 실행하기 위한 아키텍처이다. 병렬 나노코어는 다음의 하위 기능 블록들로 구성되고 각각의 기능 블록들은 RTL(Register transistor level)로 구현 및 검증되었다[(그림 9) 참조].
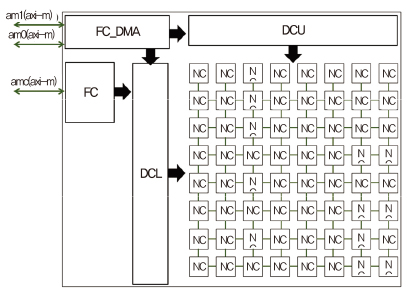
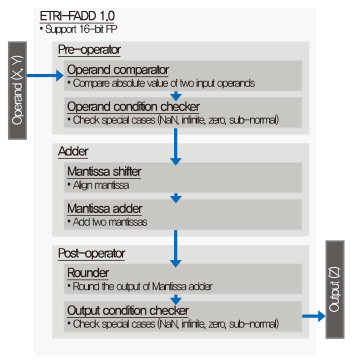
• SA(Systolic array): 부동소수점 연산기[(그림 10) 참조]를 포함한 나노코어(NC: Nano core)들의 배열로 반복적인 산술연산을 동시에 수행하기 위한 기능 블록.
• DC(Dataflow controller): 병렬 나노코어들에 피연산자(Operand) 데이터를 효율적으로 공급하고 연산 결과 데이터를 임시로 저장하기 위한 기능 블록.
• MM(Memory mover): 외부 메모리와 DC 내의 SRAM 사이의 데이터 이동을 담당하는 기능 블록.
• FC(Flow controller): 하이퍼바이저 SW에 의해 작성된 명령어들을 해석하여 ABSTC 전체 흐름을 제어하는 기능 블록.
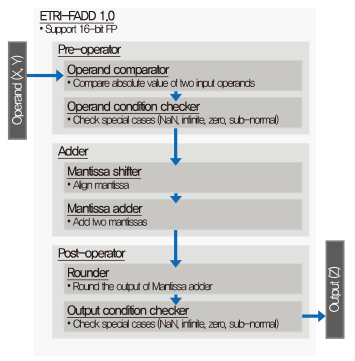
Ⅳ. 결론: 국내 반도체 기술 진보를 위하여
앞 장을 통해 해외 학계와 반도체 기업들의 인공지능 컴퓨팅 가속 반도체 개발 현황과 본 연구그룹이 개발 중인 매니코어 프로세서 아키텍처에 대해 알아보았다.
프로세서 반도체 설계 기술은 ICT 소재부품 생태계의 세균과 같은 존재다. 가장 오래된 기술이자 동시에 가장 기본적인 기술이고, 눈에 보이지 않지만 모든 곳에 존재하며, 먹이사슬 가장 아래에서 생태계 전체를 떠받치는 기술이기 때문이다. ICT 기술의 유행은 해가 지나면 바뀌기 마련이다. 하지만 그 어떤 분야로 유행이 옮겨가도 그 기반은 프로세서 설계 기술에 있다.
국내 프로세서 반도체 설계 기술은 기술적인 원인과 정책적인 원인으로 인해 국가 단위의 핵심 기술 국산화가 더딘 상황이다. 유행하는 기술의 꽁무니만 쫓다 기반기술을 개발하지 못한 탓이다. 그러는 동안 프로세서 반도체 핵심 기술을 사용하고자 하는 국내 기업들은 값비싼 로열티를 지급하며 소수점 단위의 이윤으로 버티고 있다. 하지만 최근 불어오는 인공지능 기술에 대한 수요는 반도체 시장을 다시금 뚜렷한 강자 없는 난세로 만들었다. 반도체 공룡 기업과 학계 모두 인공지능 컴퓨팅에 적합한 아키텍처를 찾는데 시행착오를 거듭하고 있다. 이때 인공지능 반도체의 국가 단위 독자 기술 확보에 뒤처진다면 한강의 기적은 다시는 일어나지 않을 20세기의 유물로 남을 것이다. 우리나라에는 이미 세계적인 메모리 반도체 회사들이 있다. 이 경험을 토대로 정부와 학계와 기업이 긴밀하게 연계하면 인공지능 반도체 분야에서도 충분한 경쟁력을 가질 수 있을 것이다.
J. Dongarra, “Report on the Sunway TaihuLight System,” University of Tennessee, Tech Report UT-EECS-16-742, June 2016.
H. Fu et al., “The Sunway TaihuLight Supercomputer: System and Applications,” Sci. China Inform. Sci., vol. 59, July 2016.
N.P. Jouppi et al., “In-datacenter Performance Analysis of a Tensor Processing Unit,” Int. Symp. Comput. Archit. (ISCA), Toronto, Canada, June 24?28, 2017, pp. 1?12.
D. Moloney et al., “Myriad 2: Eye of the Computational Vision Storm,” Hot Chips Symp., Cupertino, CA, USA, Aug. 10?12, 2014.
Qualcomm Technologies, Inc., “Snapdragon 835 Mobile Platform Product Brief,” www.qualcomm.com, 2016.
M. Humrick, and R. Smith, “The Qualcomm Snapdragon 835 Performance Preview,” Anandtech, 2017. 3. 22.
Y. Chen, T. Chen, Z. Xu, N. Sun, and O. Temam, “DianNao Family: Energy-Efficient Hardware Accelerators for Machine Learn-ing,” Commun. ACM, vol. 59, no. 11, Nov. 2016, pp. 105-112.
(그림 2)
SW26010[2]

[출처] J. Dongarra, “Report on the Sunway TaihuLight System,” University of Tennessee, Tech Report UT-EECS-16-742, June 2016.
(그림 3)
파스칼 SM 아키텍처[4]
[출처] NVIDIA Corporation, “NVIDIA Tesla P100 whitepaper,” WP-08019-001-__v01.1, 2016, pp. 1–45.
(그림 4)
TPU 아키텍처[5]
[출처] N.P. Jouppi et al., “In-datacenter Performance Analysis of a Tensor Processing Unit,” Int. Symp. Comput. Archit. (ISCA), Toronto, Canada, June 24–28, 2017, pp. 1–12.
(그림 5)
Myriad2 chip micrograph[6]
[출처] D. Moloney et al., “Myriad 2: Eye of the Computational Vision Storm,” Hot Chips Symp., Cupertino, CA, USA, Aug. 10–12, 2014.
(그림 6)
Snapdragon 835 아키텍처[8]
[출처] M. Humrick and R. Smith, “The Qualcomm Snapdragon 835 Performance Preview,” Anandtech, 2017. 3. 22.
(그림 7)
TrueNorth, Neurosynaptic Core 아키텍처[9]
[출처] Y. Chen et al., “DianNao Family: Energy-Efficient Hardware Accelerators for Machine Learn-ing,” Commun. ACM, vol. 59, no. 11, Nov. 2016, pp. 105-112.
(그림 8)
Cambricon chip micrograph[11]

[출처] S. Liu et al., “Cambricon: An Instruction Set Architecture for Neural Networks,” Int. Symp. Comput. Archit. (ISCA), Seoul, Rep. of Korea, June 18–22, 2016, pp. 393–405.
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.