3D 딥러닝 기술 동향
Recent R&D Trends for 3D Deep Learning
- 저자
-
이승욱CG/Vision기술연구그룹 tajinet@etri.re.kr 황본우CG/Vision기술연구그룹 bwhwang@etri.re.kr 임성재CG/Vision기술연구그룹 sjlimg@etri.re.kr 윤승욱CG/Vision기술연구그룹 suyoon@etri.re.kr 김태준CG/Vision기술연구그룹 taejoonkim@etri.re.kr 최진성CG/Vision기술연구그룹 jin1025@etri.re.kr 박창준CG/Vision기술연구그룹 chjpark@etri.re.kr
- 권호
- 33권 5호 (통권 173)
- 논문구분
- 일반논문
- 페이지
- 103-110
- 발행일자
- 2018.10.01
- DOI
- 10.22648/ETRI.2018.J.330511
- 초록
- Studies on artificial intelligence have been developed for the past couple of decades. After a few periods of prosperity and recession, a new machine learning method, so-called Deep Learning, has been introduced. This is the result of high-quality big- data, an increase in computing power, and the development of new algorithms. The main targets for deep learning are 1D audio and 2D images. The application domain is being extended from a discriminative model, such as classification/segmentation, to a generative model. Currently, deep learning is used for processing 3D data. However, unlike 2D, it is not easy to acquire 3D learning data. Although low-cost 3D data acquisition sensors have become more popular owing to advances in 3D vision technology, the generation/acquisition of 3D data remains a very difficult problem. Moreover, it is not easy to directly apply an existing network model, such as a convolution network, owing to the variety of 3D data representations. In this paper, we summarize the 3D deep learning technology that have started to be developed within the last 2 years.
Share
Ⅰ. 머리말
최근의 핫 이슈인 딥러닝은 여러 가지 응용 분야에서 기존의 전통적인 비전 기반의 접근방법(Hand Crafted Feature)보다 월등한 성능을 보여준다[1]. 특히 그중에서 합성 곱(Convolution) 기반의 네트워크[2]는 영상 인식, 자연어 처리, 게임 등의 많은 분야에서 우수한 결과를 보여줌으로써 더 많은 딥러닝 연구 및 응용 사례를 만들어내고 있다. 딥러닝 기술은 초기의 암흑기를 거쳐 몇 번의 위기를 극복하고 지금의 중흥기를 맞이하고 있다[3]. 현재 가장 활발히 연구되고 있는 분야는 2D 영상 분야로 비교적 데이터 획득이 용이하고, 현재 개발된 대부분의 네트워크이 정해진 크기의 벡터 데이터를 처리하는데 최적화되어 있기 때문이다.
2D 딥러닝은 초기에는 식별 모델(Discriminative Model)을 이용하여 영상 분석, 인식 분야에 적용되었다. 2014년 Ian J. Goodfellow[4]가 GAN(Generative Adversarial Network), 즉 생성 모델(Generative Model) 기반 네트워크를 제시하면서, 새로운 전환점을 맞이하게 되었다. (그림 1)은 ‘the-gan-zoo’라는 GitHub 포스트의 그림으로 최근 GAN 논문의 빠른 증가 추세를 확인할 수 있다.
(그림 1)
GAN 논문의 증가 추이
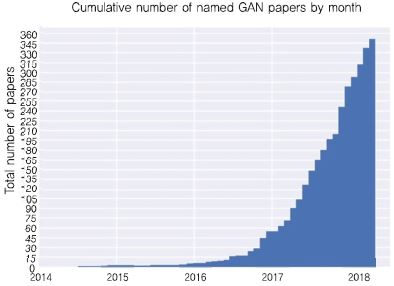
[출처] Printed with permission from A. Hindupur, “the GAN Zoo,” GitHub Apr. 19, 2017. https://deephunt.in-/the-gan-zoo-79597dc8c347
3D 데이터를 이용한 학습은 2D 데이터의 학습과는 다른 양상을 보인다. 가장 큰 차이점은 학습용 데이터의 확보가 어렵다는 점이다. 1D 혹은 2D의 경우 녹음기, 카메라 등 다양한 방법으로 데이터를 확보할 수 있지만, 3D의 경우는 학습 데이터 확보가 쉽지 않다. 그러나 최근 저가 3D 스캐너의 보급과 기존 3D 모델 데이터가 DB화되면서 3D 학습 데이터를 확보가 비교적 용이해졌다. 다음은 대표적인 3D 모델 데이터 DB는 다음과 같다.
• ShapeNet: 가구, 자동차 등 태깅된(Annotated) 3D 모델을 제공. ShapeNetCor(55 카테고리, 51,300개 모델)와 ShapeNetStem(ShapeNet-Core의 부분 집합, 12,000개 모델)으로 구성 (https://www.shapenet.org/).
• Human3.6M: 남성 6인, 여성 5인의 배우에 의해 17가지 시나리오로 생성된 3.6백만 개의 자세 데이터 DB, 모션 정보 및 관련 태깅 포함(http://vision.imar.ro/human3.6m/description.php).
• SceneNet: 가상 합성을 통해 생성된 5만 개 이상의 실내 장면 DB, 세그먼테이션 정보 등 다양한 목적의 GT(Ground Tools) 제공(https:// robotvault.bitbucket.io/scenenetrgbd.html).
• ModelNet: 인체 포함하는 다양한 객체를 CAD 기반 3D 모델 제공(662 카테고리, 127,915개 모델, http://modelnet.cs.princeton.edu/).
• IKEA Dataset: MIT와 가구회사 IKEA가 구축한 3D 가구 DB(IKEAobject와 IKEAroom으로 구성, http://ikea.csail.mit.edu/).
• CAESAR DB: 유럽과 미국인 5천 명에 대한 고품질 스캔 데이터(질감 및 모션 정보 없음, http:// store.sae.org/caesar/).
각 DB는 인식, 세그먼테이션, 복원 등 다양한 응용영역에서 관련 연구에 활용 중이다.
본 고는 Ⅰ 개요를 시작으로 Ⅱ. 2D 딥러닝과 3D 딥러닝 기술 비교, Ⅲ. 3D 딥러닝 알고리즘 소개 및 Ⅳ. 결론으로 끝맺고자 한다.
Ⅱ. 2D 딥러닝과 3D 딥러닝 비교
본 장에서는 2D 딥러닝과 3D 딥러닝을 비교한다. 기본적으로 3D 데이터는 2D 데이터에 비해 정보량이 많을 뿐만 아니라 앞서 서술한 바와 같이 데이터 확보가 쉽지 않아 학습에 많은 어려움이 있다. 또한, 2D 영상과 3D 데이터 구조에서도 차이가 존재한다.
(그림 2)는 CNN(Convolutional Neural Network)을 이용한 전형적인 인식 네트워크 구조로 이때 사용되는 2차원 영상 데이터는 2차원 배열의 구조와 채널(RGB)을 가지는 단일한 형태의 구조로 정의된다. 이와 같은 전형적인 격자 구조에 합성 곱 필터를 적용하여 사용자가 원하는 네트워크를 구성할 수 있다. 그러나 3D 데이터의 경우 데이터의 표현 방법이 정해져 있지 않고 다양한 형태로 표현된다. 3D 딥러닝에서는 이러한 다양한 형태의 데이터 표현을 지원하는 네트워크를 모델링 하는 것이 중요한 연구 주제이다.
(그림 2)
격자 구조를 가지는 정형화된 2차원 영상 데이터 구조
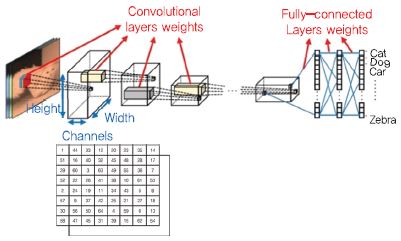
[출처] M. Astrid and S.I. Lee, “Deep compression of convolutional neural networks with low-rank approximation,” ETRI J. vol. 40 no. 4, Aug. 2018, pp. 421-434, KOGL Type 4.
본 고에서 사용하는 용어, 3D 딥러닝 응용 및 알고리즘 분류는 2017년 CVPR의 3D Deep Learning Tutorial[5]의 구분 기준을 따른다.
1. 다양한 3D 데이터 표현 방법(3D Data Representation)
• Polygonal Mesh: 가장 일반적으로 산업계에서 사용되는 포맷으로 3D 정점(Vertex), 다각형 면(삼각 혹은 사각형의 면) 등으로 구성된 3D 데이터[(그림 3) 참조].
(그림 3)
Polygonal Mesh Data
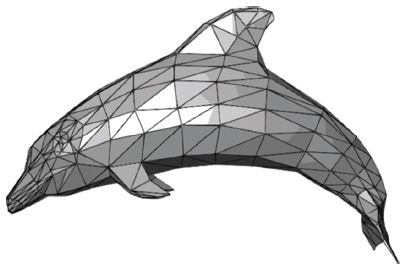
[출처] Chrschn, An example of a polygon mesh, WiKimedia, Mar. 2007, Public Domain.
• Volume Data: 일반적으로 복셀(Voxel: 부피를 가지는 픽셀 정보)로 정의되는 3D 데이터로 의료 및 과학 데이터 시각화 및 분석에 사용[(그림 4) 참조].

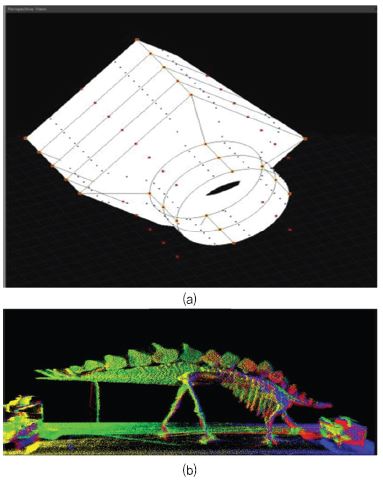
• Point Data: 3D 공간 위치 및 색상 정보를 포함하는 포인트 정보. 3D 스캐너의 일반적인 출력 형태로 사용되며 계측학, 시각화 등에서 사용[(그림 5)] 참조.
(그림 5)
(a) 프리미티브 기반 3D 데이터와 (b)포인트 데이터
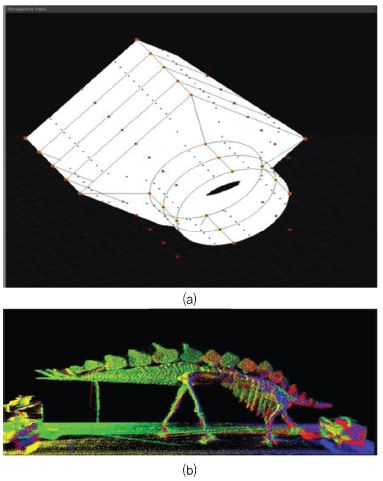
[출처] TLS2015A, Stegosaurus 3Dpoint Cloud, WiKimedia, Jan. 2017, CC-BY-SA 4.0.
• Primitive-Based Data: 수학적인 면, 선의 조합으로 만들어지 데이터로 각각의 컨트롤 포인트를 조작하여 면, 선을 변형하여 3D 데이터를 생성하며, CAD, CAM 등에서 사용.
• Multi-view Images: 3D 데이터에 대한 다 시점 영상으로 3D 모델 표현, 3D를 가시화하기 힘들 웹 환경이나, stereoscopy 등에서 사용[(그림 6) 참조].

위에서 설명한 5개의 3D 데이터의 표현 방법에서, Volume과 Multi-view 영상은 정형화된 형태(Rasterized-form)이므로, 기존 2D에서 사용하는 딥러닝 네트워크에 직접 적용할 수 있다. 그러나 나머지의 표현 방법은 정형화된 형태가 아니기 때문에 기존의 2D 네트워크를 직접 사용할 수 없다[(그림 2) 참고]. 즉, 이 경우는 데이터의 표현 방법에 적합한 네트워크를 설계하거나, 3D 데이터를 기존 네트워크에 적합한 형태로 가공해야 한다.
2. 3D 딥러닝의 응용분야
본고에서는 3D 딥러닝의 응용 분야는 3가지로 구분한다[5].
• 3D Geometry Analysis: 입력된 3D 데이터를 분석하는 것으로, 예를 들어 입력된 3D 모델의 분류(Classification), 구성 요소(Parsing/Seg-mentation), 모델 간 상관 관계(Correspon-dence) 정보를 추출하는 과정[(그림 7) 참조].
• 3D Synthesis: 입력 2D 혹은 불충분한 3D (Partial 3D) 데이터로부터 3D 데이터를 생성하는 과정[(그림 8) 참조].
• 3D-Asisted Image Analysis: 2D 입력에서 2D 혹은 데이터를 추출하는 응용에서 내부적으로 3D 데이터를 사용, 본 원고에서는 다루지 않음[(그림 9) 참조].
이외의 기타 응용으로 스타일 변형 등을 생각할 수 있다. 3D 입력으로 정보를 분석하고, 분석된 정보를 기반으로 3D 데이터의 스타일을 변형하는 방식이다[6].
3. 3D 학습 데이터 확장
딥러닝 기반의 기계 학습에서는 데이터의 확보가 매우 중요하다. 특히 3D 분야는 데이터 확보가 쉽지 않아, Data-Driven 기법으로 학습 데이터를 확장하는 연구가 필요하다.
Zheng[7]은 CAD 모델의 데이터 확장을 목적으로 소수의 3D 모델 집합에서 각 모델의 부분을 조합하여 다수의 새로운 모델을 생성하는 기술을 개발했다. 입력 모델의 각 부분의 역할(연결, 지지 등)을 자동으로 분석하여 생성된 모델의 기능적 유사성을 보장한다. Kalogerakis[8]는 88개의 의자 입력모델에서 870개의 의자 모델로 확장하는 연구를 발표했다[(그림 10) 참조].

Ⅲ. 3D 딥러닝 기술
본 장에서는 앞서 설명한 데이터 표현 방법 및 응용분야에 따른 다양한 3D 딥러닝 알고리즘을 설명한다. Ⅰ,Ⅱ장은 응용 분야별 기술을 소개하며, Ⅲ장은 Polygonal mesh를 직접 네트워크에서 사용하는 방법을 소개한다.
1. 3D Synthesis 기술
기존의 컴퓨터 비전 분야에서 카메라 정보, 객체 특징 등을 추출해 이를 기반으로 객체의 3D 정보를 유추하는 방식을 벗어나 최근에는 부족한 정보(한 장의 영상, 일부 영상, 시점 정보나 카메라 정보가 없는 다 시점 영상 등)로부터 학습을 통해 온전한 3D 객체의 외형을 유추하는 연구가 늘어나는 추세이다.
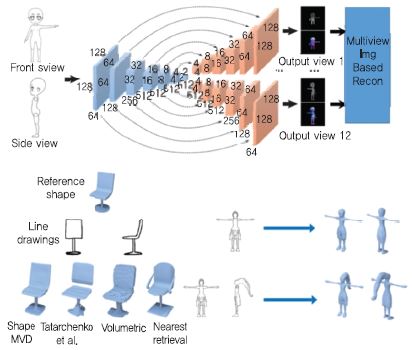
Kar[9]는 한 장의 영상으로부터 학습을 통해 특정 카테고리에 속한 객체의 3D 외형을 유추하는 연구 (학습 시 영상 주석, 영상에서 대상 객체 분할 필요)를 수행했다. Rock[10]은 한 장의 깊이 영상으로부터 유사한 3D 예제 모델을 검색하고 깊이 영상 정보와 3D 예제 모델의 변형을 통해 3D 객체의 온전한 외형을 유추했다. Lun[11]은 정면, 측면 스케치 영상을 입력으로 합성 곱 네트워크를 이용하여 360도 전방위 다 시점 영상을 생성하고, 이를 기반으로 기존의 다 시점 기반 3D 복원 기술로 3D 데이터를 생성하는 기술을 개발했다. 논문에서는 14개 뷰 학습을 이용하였으며, 입력 뷰의 증가에 따라 생성된 결과물의 품질이 향상됨을 보여준다. 이 방식은 3D 데이터를 다 시점 영상으로 표현하는 경우로, 기존 합성 곱 네트워크를 직접 적용할 수 있다[(그림 11) 참조].
(그림 11)
ShapeMVD: (상단) 스케치 기반의 3D 생성 기술, (좌측하단)의자 그림에 대한 다양한 결과, (우측하단)입력 뷰의 개수에 따른 결과물의 품질 비교
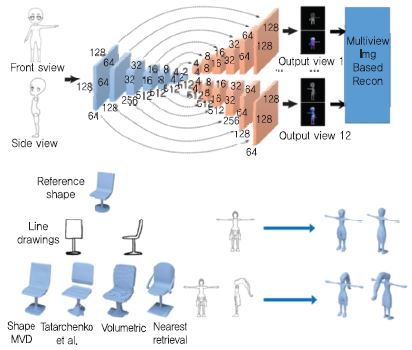
[출처] Reprinted with permission from Z. Lun, M. Gadelha, E. Kalogerakis, S. Maji, and R. Wang, “3D Shape Reconstruction from Sketches via Multi-view Convolu-tional Networks,” Sept. 2017, arXiv: 1707.06375.
Dibra[12]는 CAESAR DB를 기반으로 학습하여, 사람 전신을 촬영한 입력으로 이에 해당하는 이진(binary) 실루엣 영상들을 생성하여 사람 몸의 3D 외형 및 치수를 유추하는 연구 수행하였다. CAESAR DB는 Ⅰ장에서 명시한 바와 같이 형태(Shape) 정보만 포함해 Dibra에 의해 생성된 모델은 질감 정보가 존재하지 않는다.
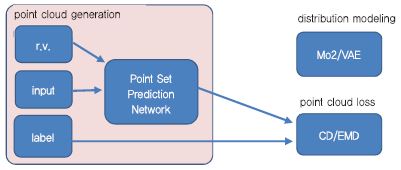
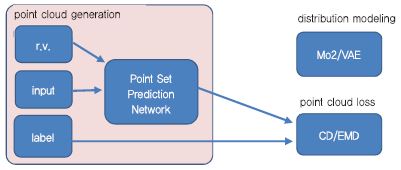
Fan[13]은 한 장의 사진으로부터 3D 객체의 포인트 클라우드 정보 기반 3D 데이터를 생성하는 기술을(PointOutNet) 개발했다. 포인트 데이터는 순서 정보가 없기 때문에 순환 불변(Permutation Invariance)의 특징을 가지고 있다. N 차원의 X개로 구성된 포인트 데이터 {P1, P2, P3, … PX}와 이를 임의로 순서를 변경한 {P3, P1, P2, … PX}는 같은 정보를 나타내는 데이터이다. 즉 이러한 정보를 네트워크에서 인코딩 하기 위해서는 대칭성(Symmetric)을 가지는 함수를 활성 함수로 사용해야 하는데, 일반적으로 최대값을 반환하는 MAX(‧) 함수를 사용한다[(그림 12) 참조].
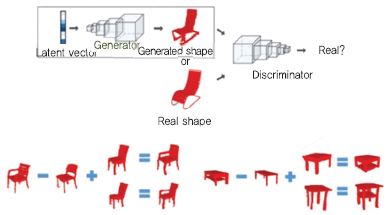
Wu[14]는 volume 데이터 기반 GAN을 개발하였다. DCGAN(Deep Convolutional Generative Adversarial Networks)과 비슷한 형태의 연산을 수행할 수 있게 한다[(그림 13) 참조].
(그림 13)
Volumetric Generative Adversarial Network
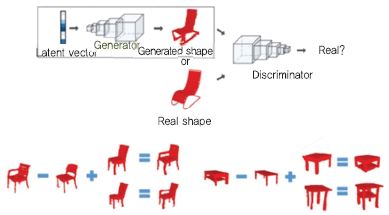
[출처] Reprinted with permission from J. Wu et al., “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling,” Proc. Int. Conf. Neural Inform. Process. Syst., Barcelona, Spain, Dec. 5-10, 2016, pp. 82-90.
Jackson[15]은 volume 데이터를 이용하여 한 장의 얼굴사진에서 3D 모델을 생성하는 기술을 개발하고 관련된 온라인 데모를 공개하였다. 기본적으로 기존의 얼굴 검출 라이브러리를 사용하여 얼굴 영역을 검출하고, 딥러닝 학습을 통해 3D를 얼굴을 복원한다. 참고로 동양인의 얼굴로 테스트를 하면, 코가 서양인과 같은 형태로 복원되는데, 이는 학습 DB가 서양인 위주로 되어있기 때문이다.
2. 3D Geometry Analysis
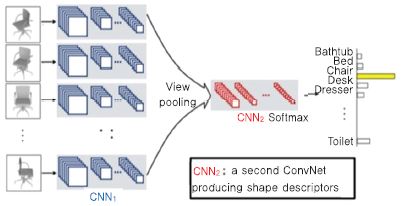
Su[16]는 다 시점 영상을 이용하여 3D 객체에 대한 인식 기술을 개발했다. 입력 3D 모델에 대한 다 시점 영상을 생성하고, 각 뷰 별로 convolution 네트워크를 수행한다. 다 시점으로 생성된 특징에 대해 view pooling을 수행하여 shape 서술자를 생성하기 위한 두번째 convolution 네트워크를 생성한다. 이렇게 생성된 shape 서술자에 softmax를 적용하여 최종 랭크를 출력한다. 이 논문에서는 학습 시간의 단축을 위해서 학습 데이터와 비슷한 분포의 데이터로 학습된 하이퍼 파라미터를 초기값으로 사용하여 선행 학습(Pre-training)하고 이후 자신의 데이터에 맞게 추가 상세 학습을(Fine-tuning)을 진행한다[(그림 14) 참조].
(그림 14)
다 시점 영상과 CNN을 이용한 3D 객체 인식
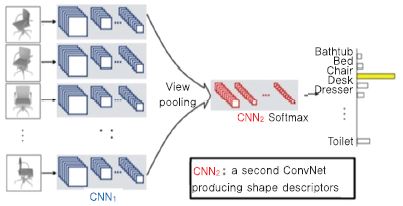
[출처] Reprinted with permission from H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view Convolutional Neural Networks for 3D Shape Recognition,” Sep. 2015, arXiv: 1505.00880.
Kalogerakis[17]은 파트 별로 세그먼테이션된 학습DB를 기반으로 다 시점 영상 기반 3D 형상 세그먼테이션을 수행하였다. 영상을 기반으로 하여 기존의 convolution 네트워크를 이용했으며 다 시점 영상의 정합을 위해 영상을 객체 표면에 프로젝션하는 기법을 이용하였다. 3D 객체의 전체 영역을 학습하기 위해 각 뷰에 대한 회전과 화각 변경을 수행하였다.
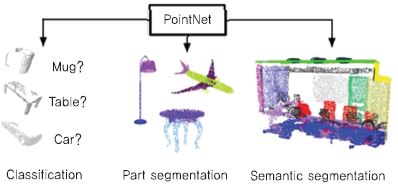
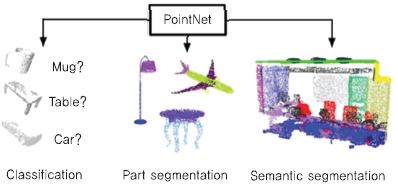
Qi[18]는 포인트 데이터 기반의 분류 및 세그먼테이션을 수행하는 PointNet을 개발하였다. 다 시점 기반의 알고리즘보다 분류 측면에서는 성능이 떨어지지만, 세그먼테이션 응용에서는 우수한 성능을 보여준다[(그림 15) 참조].
3. Geometric Deep Learing
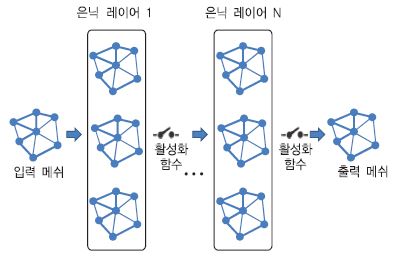
Ⅳ. 맺음말
앞서 살펴본 바와 같이 최근 2년 사이에 3D 딥러닝에 관련된 연구가 증가하고 있다. 그러나 3D 데이터는 기존의 데이터와는 달리 학습 데이터의 확보가 쉽지 않다. 3D 획득 센서가 널리 퍼지고 있지만, 학습에 사용될 만한 데이터는 부족하며, 학습에 사용될 수 있는 데이터도 가구 등의 특수한 형태에 한정적이다. 또한, 3D 모델에 대한 다양한 표현 방식으로 말미암아 기존의 학습 모델을 직접 사용하기에 적합하지 않다. 직접적으로 메쉬 모델을 다루는 논문이 소개는 되지만 아직 초기 단계이며, 많은 연구가 필요한 분야이다.
약어 정리
S. Khan and S.P.Yong, “A Comparison of Deep Learning and Hand Crafted Features in Medical Image Modality Classification,” Int. Conf. Comput. Inform. Sci., Kuala Lumpur, Malaysia, Aug. 15-17, 2016, pp. 633-638.
T. Kim, “CNN, Convolution Neural Network 요약,” Tawan.Kim Blog, Jan. 4, 2018. Available: http://taewan.-kim/post/cnn/
I. J. Goodfellow et al., “Generative Adversarial Nets,” Adv. Neural Inform. Process. Syst., Montreal, Canada, Dec. 8-13, 2014, pp. 1-9.
Z. Lun, E. Kalogerakis, R. Wang, and A. Sheffer, “Functionality Preserving Shape Style Transfer,” ACM Trans, Graphics (TOG), vol. 35, no. 6, Nov. 2016, pp. 209:1-209:14.
Y. Zheng, D. Cohen-Or, and H.J. Mitra, “Smart Variations: Functional Substructures for Part Compatibility,” Comput. Graphics Forum, vol. 32, no. 2, May, 2013, pp. 195-204.
E. Kalogerakis et al., “A Probabilistic Model for Component-Based Shape Synthesis,” ACM Trans. Graphics, vol. 31, no. 4, July 2012, pp. 55:1-55:11.
A. Kar, S. Tulsiani, J. Carreira, and J. Malik, “Category-Specific Object Reconstruction from a Single Image,” IEEE Conf. comput. Vis. Pattern, Recogn. (CVPR), Boston, MA, USA, June 7-12, 2015, pp. 1966-1974.
J. Rock, T. Gupta, J. Thorsen, J. Gwak, D. Shin, and D. Hoiem, “Completing 3D Object Shape from one Depth Image,” IEEE Conf. comput. Vis. Pattern, Recogn. (CVPR), Boston, MA, USA, June 7-12, 2015, pp. 2484-2493.
Z. Lun, M. Gadelha, E. Kalogerakis, S. Maji, and R. Wang, “3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks,” Sept. 2017, arXiv: 1707.06375.
E. Dibra, H. Jain, C. Öztireli, R. Ziegler, and M. Gross, “HS-Nets: Estimating Human Body Shape from Silhouettes with Convolutional Neural Networks,” Int. Conf. 3D Vision (3DV), Stanford, CA, USA, Oct. 25-28, 2016, pp. 108-117.
H. Fan, H. Su, and L. Guibas, “A Point Set Generation Network for 3D Object Reconstruction from a Single Image,” Dec. 2016, arXiv: 1612.00603.
J. Wu et al., “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling,” Proc. Int. Conf. Neural Inform. Process. Syst., Barcelona, Spain, Dec. 5-10, 2016, pp. 82-90.
A.S. Jackson, A. Bulat, V. Argyriou, and G. Tzimiropoulos, “3D Face Reconstruction demo,” Available: http://cvl-demos.cs.nott.ac.uk/vrn/
H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view Convolutional Neural Networks for 3D Shape Recognition,” Sept. 2015, arXiv: 1505.00880.
Kalogerakis, Averkiou, Maji, Chaudhuri, “3D Shape Segmentation with Projective Convolutional Networks,” IEEE Conf. Comput. Vis. Pattern, Recogn. (CVPR), Honolulu, HI, USA, July 21-26, 2017, pp. 6630-6639.
C.R. Qi et al., “PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation,” Apr. 2017, arXiv: 1612.00593.
(그림 1)
GAN 논문의 증가 추이
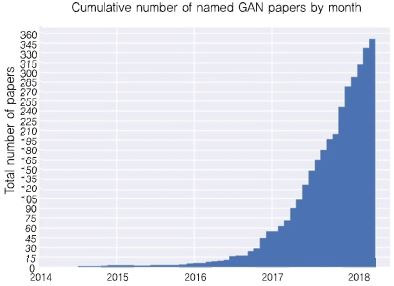
[출처] Printed with permission from A. Hindupur, “the GAN Zoo,” GitHub Apr. 19, 2017. https://deephunt.in-/the-gan-zoo-79597dc8c347
(그림 2)
격자 구조를 가지는 정형화된 2차원 영상 데이터 구조
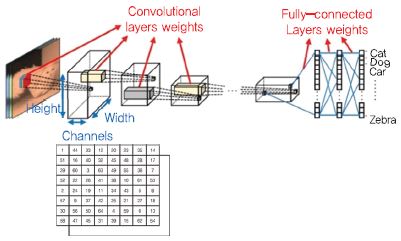
[출처] M. Astrid and S.I. Lee, “Deep compression of convolutional neural networks with low-rank approximation,” ETRI J. vol. 40 no. 4, Aug. 2018, pp. 421-434, KOGL Type 4.
(그림 3)
Polygonal Mesh Data
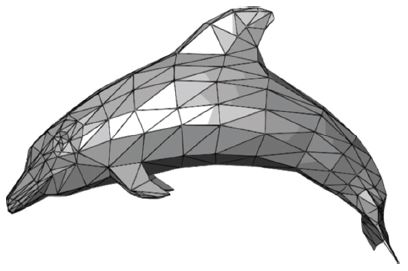
[출처] Chrschn, An example of a polygon mesh, WiKimedia, Mar. 2007, Public Domain.

(그림 5)
(a) 프리미티브 기반 3D 데이터와 (b)포인트 데이터
[출처] TLS2015A, Stegosaurus 3Dpoint Cloud, WiKimedia, Jan. 2017, CC-BY-SA 4.0.

(그림 10)
입력 모델(녹색)에서 신규 모델(파란색)생성

[출처] Reprinted with permission from E. Kalogerakis et al., “A Probabilistic Model for Component-Based Shape Synthesis,” ACM Trans. Graphics, vol. 31, no. 4, July 2012, pp. 55:1-55:11.
(그림 11)
ShapeMVD: (상단) 스케치 기반의 3D 생성 기술, (좌측하단)의자 그림에 대한 다양한 결과, (우측하단)입력 뷰의 개수에 따른 결과물의 품질 비교
[출처] Reprinted with permission from Z. Lun, M. Gadelha, E. Kalogerakis, S. Maji, and R. Wang, “3D Shape Reconstruction from Sketches via Multi-view Convolu-tional Networks,” Sept. 2017, arXiv: 1707.06375.
(그림 13)
Volumetric Generative Adversarial Network
[출처] Reprinted with permission from J. Wu et al., “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling,” Proc. Int. Conf. Neural Inform. Process. Syst., Barcelona, Spain, Dec. 5-10, 2016, pp. 82-90.
(그림 14)
다 시점 영상과 CNN을 이용한 3D 객체 인식
[출처] Reprinted with permission from H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view Convolutional Neural Networks for 3D Shape Recognition,” Sep. 2015, arXiv: 1505.00880.
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.