자율주행 인공지능 컴퓨팅 하드웨어 플랫폼 기술 동향
State-of-the-Art AI Computing Hardware Platform for Autonomous Vehicles
- 저자
-
석정희프로세서연구그룹 jhsuk@etri.re.kr 여준기프로세서연구그룹 cglyuh@etri.re.kr
- 권호
- 33권 6호 (통권 174)
- 논문구분
- 최신 반도체, 하드웨어 기술 동향 특집
- 페이지
- 107-117
- 발행일자
- 2018.12.21
- DOI
- 10.22648/ETRI.2018.J.330611
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- In recent years, with the development of autonomous driving technology, high-performance artificial intelligence computing hardware platforms have been developed that can process multi-sensor data, object recognition, and vehicle control for autonomous vehicles. Most of these hardware platforms have been developed overseas, such as NVIDIA’s DRIVE PX, Audi’s zFAS, Intel GO, Mobile Eye’s EyeQ, and BAIDU’s Apollo Pilot. In Korea, however, ETRI's artificial intelligence computing platform has been developed. In this paper, we discuss the specifications, structure, performance, and development status centering on hardware platforms that support autonomous driving rather than the overall contents of autonomous driving technology.
Share
Ⅰ. 서론
자율주행을 위해서는 사람의 눈과 귀와 같은 역할을 다양한 센서(카메라, 라이다, 레이다, 초음파 등)들과 이들 센서 데이터를 이용하여 주행 차량 주변의 객체 들을 인식하고 주행 상황을 판단하여 주행 경로를 설정하고 그에 맞는 차량 제어 명령어를 차량에 전달할 수 있는 시스템이 필요하다. 시스템은 소프트웨어와 하드웨어로 구분할 수 있다. 소프트웨어는 센서 및 하드웨어 장치들을 위한 장치 드라이버부터 운영체제, 객체 인식을 위한 알고리즘(최근은 딥러닝 알고리즘 사용) 소프트웨어, 주행 상황 판단 및 경로 설정을 위한 알고리즘 소프트웨어, 차량 제어 소프트웨어, V2X 통신을 위한 소프트웨어 등 다양하게 구성된다. 하드웨어는 카메라, 라이다, 레이다와 같은 다종의 센서들을 여러 채널을 동시에 실시간으로 인터페이스하는 부분, 딥러닝을 이용한 객체 인식, 주행 상황 판단 및 경로 설정의 실시간 수행을 위한 고성능 컴퓨팅 프로세서(CPU, GPU, FPGA, ASIC) 부분, 차량 제어(CAN, LIN)를 위한 부분, 시스템 간의 통신을 위한 부분 등으로 구성된다.
이러한 자율주행을 위해 필요한 하드웨어 기술은 초기에는 PC나 고성능의 서버를 여러 대를 사용하여 자율주행 차량에 적용되었으며 여기에 센서들을 연결하고 자율주행 차량에 필요한 소프트웨어들이 구동되는 형태였다, 그러나 최근 자율주행 기술이 발전하고 자율주행 관련 소프트웨어 테스트 단계를 넘어 점차 상용화를 위해 차량에 실장 할 수 있을 크기를 가지며 고성능을 지원하는 하드웨어 플랫폼에 대한 요구사항이 커졌고, 이에 따라 다종/다중 센서 데이터를 처리할 수 있고 고성능의 컴퓨팅 연산 성능을 지원하며 차량을 제어할 수 있는 통합 하드웨어 플랫폼들이 개발되고 있다. 대부분 엔비디아의 DRIVE PX[1], 아우디의 zFAS[2], Intel GO[3], Mobileye EyeQ[4], 바이두의 Apollo Pilot[5] 등의 해외 플랫폼이며 국내 에서는 한국전자통신연구원의 인공지능 드라이빙 컴퓨팅 플랫폼[6]이 개발되었다.
여기서는 자율주행 기술에 대한 전반적인 내용보다 앞서 설명한 자율주행이 가능하도록 지원하는 하드웨어 플랫폼 중심으로 규격, 구조, 성능 및 개발 현황 등을 소개한다.
Ⅱ. 해외 기술동향
1. 엔비디아 DRIVE PX
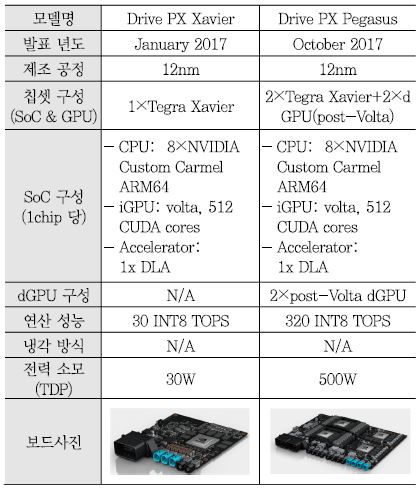
엔비디아는 GPU 기술을 기반으로 세계 1위의 그래픽 칩을 공급하는 기업이다. 엔비디아의 GPU는 2010년 중반부터 본격적으로 딥러닝 기술이 학계 및 산업 전반에 소개됨에 따라 현존하는 반도체 칩 기술 중 딥러닝 알고리즘을 가장 빠르게 처리할 수 있는 기술로 부상하여 컴퓨터 그래픽뿐만 아니라 딥러닝이 적용되는 다양한 응용 분야에 사용되고 있다. 딥러닝 기술이 적용되는 최적의 분야 중 하나가 자율주행이며 이에 적용할 수 있는 컴퓨팅 플랫폼으로 자사의 GPU 기술을 핵심으로 적용하여 Drive PX 플랫폼을 2015년 CES에서 선보였고 2016년 CES에서 Drive PX2를 공개 했다. 또한 2017년 1월에 Volta 구조의 GPU와 딥러닝 가속기(DLA)가 내장된 Tegra Xavier(SoC) 1개를 적용한 Drive PX Xavier를 발표했으며, 2018년 하반기 시장 공개를 위하여 2017년 10월에 Tegra Xavier 2개를 적용한 Drive PX Pegasus를 개발하고 있음을 발표하였다.
가. Drive PX and Drive PX2
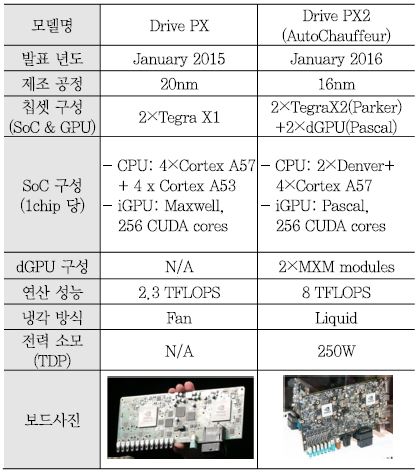
Drive PX는 2015년 CES, Drive PX2는 2016년 CES에서 발표되어 자율주행을 위한 플랫폼으로써 큰 관심을 받았다. <표 1>은 Drive PX와 Drive PX2의 주요 구성 및 성능을 비교한 표이다. Drive PX는 CPU core와 내장 GPU(iGPU)를 탑재한 Tegra X1 2개를 사용하여 2.3 TFLOPS의 32비트 부동소수점 연산 성능을 제공한다. Tegra X1의 CPU core는 ARM의 Cortex A57 4개, Cortex A53 4개가 적용되어 멀티 core를 지원한다. Tegra X1에는 Maxwell microarchitecture의 SMM (Maxwell Streaming Multiprocessor) 2개로 이루어진 GPU가 내장되어 있다. SMM은 Maxwell 구조의 SM(Streaming Multiprocessor)을 가리키며 각 SMM은 SIMT(Single Instruction Multiple Thread) 연산이 가능한 128개의 CUDA core로 이루어져 있어 CUDA API가 적용된 소프트웨어를 고속 병렬 처리할 수 있다.
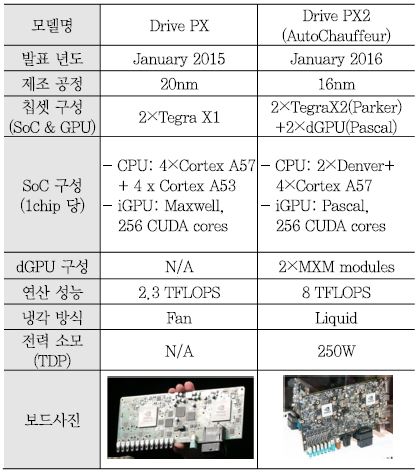
Drive PX2는 Drive PX를 기반으로 하고 있으나 사용된 SoC가 Tegra X1에서 Tegra X2로 변경되었으며 2개의 MXM(Mobile pci-eXpress Module) 슬롯을 제공하여 별도의 MXM 규격의 외장 GPU(dGPU)를 슬롯에 장착하여 전체 연산 성능을 8 TFLOPS 정도로 높였으며 이를 통해 자율주행 레벨 2~3을 구현할 수 차이점이 있다. Tegra X2는 Parker라는 코드명으로 불리기도 하는데 Denver CPU core 2개와 ARM Cortex 57 CPU core 4개를 탑재하고 있으며 Pascal 구조의 2개의 SM (Streaming Multiprocessor)를 통해 256개의 CUDA core를 내장하고 있다. Denver는 ARMv8-A 64/32 비트 명령어 셋을 처리할 수 있도록 ARM사와 라이센싱을 통해 엔비디아가 자체 설계한 7-way superscalar pipeline 구조의 CPU core이다. 개발 초기에는 ARM과 X86 명령어 처리를 모두 지원하도록 시작하였으나 인텔의 X86 라이센싱을 획득하지 못하여 ARM ARMv8-A 명령어 셋만 지원하도록 개발되었다.
(그림 1)는 Drive PX2의 전면 보드 사진이며 Tegra X2 2개가 PCB 보드에 실장 되어 있으며, (그림 1)는 Drive PX2의 후면 보드 사진으로서 MXM 슬롯 2개에 별도의 외장 GPU를 장착할 수 있도록 되어 있다. Drive PX2는 LPDDR4 메모리 인터페이스, 차량 인터페이스를 위한 CAN, LIN, FlexRay 및 UART, USB, 1/10 Gbit Ethernet 등의 인터페이스를 지원하며 전체 TDP(Thermal Design Power)는 250W이고 높은 발열 때문에 수냉식 냉각 방법을 사용한다[1].
(그림 1)
Drive PX2 보드: (a) Drive PX2 보드 전면 사진, (b) Drive PX2 보드 후면 사진

[출처] NVIDIA Corporation, CES 2016 NVIDIA Press Event, Jan. 4, 2016, CC BY NC-ND 2.0.
나. Drive PX Xavier and Drive PX Pegasus
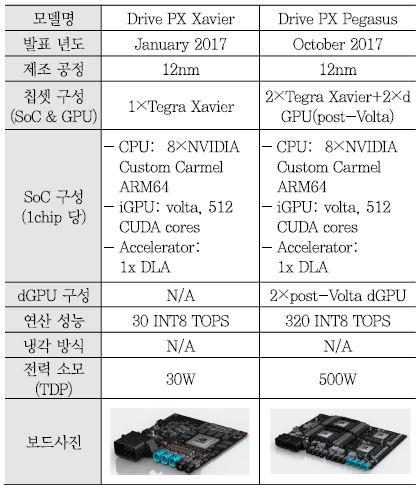
엔비디아는 2017년 CES와 2018년 CES에서 Drive PX2의 후속으로 Drive PX Xavier를 발표하였으며 Drive PX Xavier에 탑재된 SoC는 Drive PX2의 Tegra X2에서 (그림 2)의 Tegra Xavier로 변경되었다. Tegra Xavier는 ARM의 ARMv8(64비트) core 기반 엔비디아의 customization Carmel CPU core를 8개, Volta 구조의 512개 CUDA core 및 TPU(Tensor Processing Unit) 기반의 DLA(Deep Learning Accelerator)를 내장하고 있다. TSMC 12nm FinFET 공정으로 제작되었으며 면적은 300mm2이고 TDP는 30watt이다. 내장된 Volta GPU는 FP32/FP16/INT8의 멀티 precision을 지원하며 이를 통해 20 TOPS(INT8 기준)의 연산 성능을 가지며 내장된 DLA는 5 TFLOPS(FP16 기준) 혹은 10 TOPS(INT8 기준)의 성능을 제공한다. MIPI-CSI-3의 LVDS serial 카메라 인터페이스 16채널, LPDDR4, 1/10 Gbps Ethernet 등의 인터페이스를 지원한다.
(그림 2)
Tegra Xavier SoC

[출처] NVIDIA Corporation, GTC China - Jensen Huang Keynote, Sept. 26, 2017, CC BY NC-ND 2.0.
2017년 10월 GTC Europe에서 엔비디아는 완전 자율주행(레벨 5) 지원을 위한 Drive PX2 대비 10배 이상의 연산 성능 즉 320 TOPS(INT8 기준)를 가지는 Drive PX Pegasus를 2018년 하반기에 시장에 선보일 것이라고 발표하였다. <표 2>는 Drive PX Xavier와 Drive PX Pegasus의 구조 및 성능 비교를 나타낸다. Drive PX Pegasus는 Drive PX Xavier에서 사용된 Tegra Xavier SoC를 그대로 사용하면서 2개를 탑재하였다. 가장 큰 차이점은 구체적인 발표는 되지 않았지만 Volta 이후의 microarchitecture가 적용된 130TOPS 성능을 가지는 외장 GPU(TDP 220watt)를 개발하고 있으며 이 외장 GPU는 Drive PX2에서 적용된 PCI-express 기반의 MXM 슬롯을 통해 장착되는 것이 아니라 엔비디아의 고속 직렬 인터페이스인 NVLink 기반의 SXM2 mezzanine 슬롯으로 연결된다는 점이다. Drive PX Pegasus의 전체 연산 성능 320TOPS는 Tegra Xavier 2개를 적용한 60TOPS에 post-Volta 외장 GPU 2개를 적용한 260TOPS를 합산한 수치이다. 전체 TDP는 Tegra Xavier 2개의 60watt에 외장 GPU 2개를 적용한 440watt를 합한 500watt이다. 그리고 ASIL D 등급의 기능안전 인증에 맞게 설계되고 1TB 이상의 메모리 대역폭을 지원할 것으로 발표되었다.
2. 아우디 zFAS
아우디는 2014년과 2016년 CES에서 자사의 차량에 적용할 (그림 3)의 zFAS 컴퓨팅 플랫폼을 공개하였다. 자율주행 전용 컴퓨팅 플랫폼인 zFAS는 카메라 기반 객체 인식을 위하여 모빌아이 EyeQ3를 사용하고 센서 데이터의 처리 및 자율주행 관련 알고리즘의 연산을 위한 엔비디아 Tegra K1, 알테라 Cyclon V FPGA 및 차량 제어를 위하여 인피니언의 AURIX MCU를 탑재하였다.
(그림 3)
아우디의 자율주행 플랫폼 zFAS

[출처] NVIDIA Corporation, Audi zFAS prototype with Tegra VCM, Jan. 8, 2014, CC BY-NC-ND 2.0.
그리고 아우디는 2017년 7월 신형 아우디 공개 행사를 통해 2018년 신형 A8 차량에 세계 최초의 레벨 3 자율주행 기술을 적용할 것임을 선언하였다. 아우디는 (그림 4)의 A8 차량에 zFAS 보드를 장착하고 이를 통해 딥러닝 등 다양한 신기술을 적용하여 최초의 레벨 3 자율주행차, 최초의 딥러닝 적용 차량의 상용화, zFAS의 상용화를 이루겠다고 발표하였다.

아우디 A8의 zFAS에 인공지능 트래픽 잼 파일럿(AI Traffic Jam Pilot) 기능을 탑재하여 시속 60km 이하에서 레벨 3 수준의 자율주행 기능을 제공한다. 교통 체증이 있을 때 운전자는 ‘아우디 AI’ 버튼을 눌러 인공지능 트래픽 잼 파일럿 활성화시켜 자율주행 모드로 운전되며, 교통 체증이 해소되면 운전자 주행 모드로 전환할 수 있도록 시각 및 음성으로 알려 준다. 레벨 3 자율주행을 위하여 zFAS 뿐만 아니라 카메라, 레이다, 라이다 등 다양한 센서가 적용되었다. 카메라는 360도 전방위 검출을 위한 카메라 4개, 전면 카메라 1개를 사용하였다. 레이다는 전후방 및 좌우방 레이더 4개, 전방 장거리 레이더 1개를 사용하였다. 라이다는 발레오의 145도 회전형 저가형 라이다를 적용하였다. 이외에도 나이트 비전을 위한 적외선 센서 1개 및 초음파 센서 12개 등이 사용되었다[7].
3. 인텔 GO
독보적인 CPU 기술을 통해 반도체 시장을 주도하던 인텔은 최근 딥러닝 기술의 급속한 발달로 인한 엔비디아의 GPU 기술에 밀려 그 위상이 많이 흔들리고 있다. 그러나 인텔에서도 딥러닝 시장에 대응하기 위하여 2017년 3월 153억 달러를 들여 카메라 기반 자율주행 영상 인식 전문 기업인 모빌아이를 인수하고, FPGA(Field Programmable Gate Array) 반도체 기업 알테라, 인공지능 start-up 기업 모비디우스 등 여러 기업을 인수 합병하여 딥러닝 시장에 적용할 수 있는 제품 개발에 매진하고 있으며 그 일환으로 인델은 2017년 자동차, 5G 커넥티비티, 클라우드 환경에 모두 적용할 수 있는 통합 시스템 개발을 지원하는 자율주행 솔루션 인텔 GO를 개발하고 있음을 발표하였다. 또한, 2017년 5월 미국 캘리포니아 산호세에 자율주행 기술 연구소를 개설 하였고 Waymo 및 BMW와 자율 주행 자동차 기술과 관련 해 상호 협력하고 있음을 발표 등 자율주행 솔루션 및 부품 개발을 적극 추진 중이다.
인텔 GO에서는 인텔의 핵심 기술인 CPU 기술을 기반으로 딥러닝 영상 처리를 위한 모빌아이 및 모비디우스의 ASIC 기술, 알테라의 FPGA 기술을 통합 적용하였다. 그러나, 엔비디아의 GPU 기술은 적용되지 않아서 현재 대부분의 개발자가 사용하는 CUDA 기반의 딥러닝 가속 기술을 사용할 수 없는 문제점이 있으나 엔비디아의 Drive PX 대비 CPU 성능의 강점과 딥러닝 최적화된 ASIC, FPGA 기술을 통한 전력 효율성 향상을 기대할 수 있다.
인텔 GO는 (그림 5)의 Atom 프로세서를 적용한 버전과 (그림 6)의 Xeon 프로세서를 적용한 버전으로 개발되고 있다.
(그림 5)
Atom 프로세서 기반 인텔 GO

[출처] Антон Спиридонов / Hi-Tech@Mail.ru [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)]
(그림 6)
Xeon 프로세서 기반 인텔 GO

[출처] Антон Спиридонов / Hi-Tech@Mail.ru [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)]
인텔 GO Atom 버전은 Atom C3000 프로세서를 사용하며 1Gbps Ethernet을 통해 멀티 보드를 daisy-chain으로 연동할 수 있으며, 딥러닝 가속을 위한 Arria10 가속 모듈 및 ASIC 기반의 가속 모듈을 연동할 수 있다. 차량 제어를 위해 기능안전 ASIL D 등급의 인피니언의 AURIX MCU를 사용하였다. 2채널 DDR3/DDR4, 1Gbps Ethernet, CAN-FD, FlexRay, USB, UART, eMMC flash drive, V2X 등의 인터페이스를 지원한다.
인텔 GO Xeon 버전은 차세대 Xeon 프로세서를 사용하며 시스템당 2개의 CPU 보드로 구성된다. Atom 버전과 동일하게 딥러닝 가속을 위한 Arria10 가속 모듈 및 ASIC 기반의 가속 모듈을 연동할 수 있고, 인피니언의 AURIX MCU를 사용하였다. 멀티 채널의 DDR4, 10Gbps Ethernet, CAN-FD, FlexRay, USB, UART, Solid-state drive, V2X 등의 인터페이스를 지원한다.
인텔 GO는 자율주행 소프트웨어 개발을 위한 딥러닝 SDK, 컴퓨터 비전 SDK, OpenCL SDK, Sensor data labeling tool, Performance/Power analyzer, Optimizing Compiler, system level debugger 등으로 구성된 SDK(Software Development Kit)를 제공한다.
4. 모빌아이 EyeQ
모빌아이는 2004년 이스라엘에서 설립된 영상 기반의 ADAS(Advanced Driver Assistance Systems)용 EyeQ SoC를 전문적으로 개발하는 업체이며 2017년 3월 153억 달러의 막대한 금액으로 인텔에 인수되었다. EyeQ는 2008년 EyeQ1부터 2018년 EyeQ4까지 제작되었고 전세계적으로 차량 제조사 27개 업체, 협력 업체 200여 개 등에 적용되고 있는 카메라 기반의 ADAS 전용 SoC이다. (그림 7)은 EyeQ2를 사용하여 카메라 영상으로부터 차선을 인식하고 차선 이탈 시 경고를 운전자에게 알려주는 ADAS 시스템을 나타낸다. 모빌아이의 EyeQ SoC는 자율주행 플랫폼은 아니며 여러 차량 제조사 및 부품 업체의 ADAS 및 자율주행 플랫폼에 적용되는 영상 기반 인식 전용 칩으로 적용되는 형태이다. 특히 2015년 테슬라의 Model S의 autopilot의 영상 인식 칩으로 EyeQ3가 적용되었고 2016년 6월에는 autopilot 모드로 주행하던 Model S가 옆 차로를 주행하던 트럭과 충돌하여 운전자가 사망하는 사건이 발생하였고, 이후 테슬라는 모빌아이와의 협력을 청산하고 엔비디아의 Drive PX 플랫폼을 이용한 테슬라 Autopilot 버전 2를 개발하였다.
(그림 7)
EyeQ2가 적용된 lane guidance system

[출처] Binarysequence, The PCB and camera module from a Hyundai Lane Guidance camera module, Mar. 19, 2013, CC BY-SA 3.0
그럼에도 불구하고 모빌아이는 자율주행차 관련 기술 분야에서 크게 주목받고 있는 기업이며 특히 전세계 운전자 보조 시스템 시장의 70%를 차지하고 있으며 2017년까지 2천 4백만 개 이상의 EyeQ SoC가 판매되었다. 또한 EyeQ SoC를 이용하여 인텔, BMW, 아우디 등과 자율주행 플랫폼 개발에 현재 주력하고 있다.
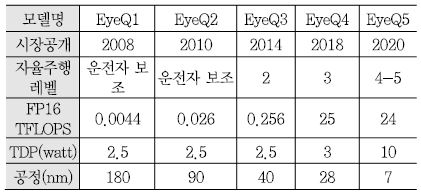
<표 3>은 모빌아이에서 발표한 EyeQ 시리즈 간의 비교 표이다. EyeQ1은 2004년에 개발 발표되고 시장에는 2008년에 공개되었다. EyeQ1과 EyeQ2는 자율주행이 아닌 차선, 차량, 보행자를 인식하여 알람을 주는 운전자 보조 기능을 수행하는 정도였고 EyeQ3와 현재 EyeQ4가 자율주행 레벨 2~3을 수행하는 용도이다.
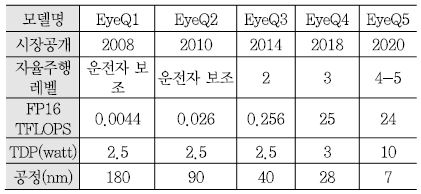
EyeQ3는 4개의 CPU core와 4개의 병렬 연산 처리를 위한 VMP(Vector Micro Processor)로 이루어져 있고 0.5GHz 클럭으로 동작한다. EyeQ4는 멀티 쓰레드 연산을 지원하는 MIPS CPU core 4개, EyeQ2 및 EyeQ3에서도 사용된 VMP 6개, 프로그램 가능한 하드웨어 가속기 역할을 하는 PMA(Programmable Macro Array) 2개, MPC(Multithreaded Processing Cluster) 2개로 구성되며 1GHz 클럭으로 동작한다. EyeQ3의 연산 성능이 0.256 TFLOPS(TDP 2.5watt)인 것에 비해 EyeQ4는 2.5 TFLOPS(TDP 3watt)로 10배의 성능 향상이 이루어 졌다. 모빌아이의 최신 EyeQ4는 중국의 전기차 벤처기업인 NIO의 ES8 모델에 세계 최초로 탑재되어 ES8의 장거리, 중거리, 단거리용 3안 카메라 영상 인식 처리를 수행한다[8]. 이전의 EyeQ3가 주로 단안 카메라 처리에 적용된 것에 비하여 EyeQ4는 자율주행 레벨 3를 위한 멀티 카메라 처리에 적용할 수 있음을 알 수 있다. 2018년 CES에서 인텔 부사장 겸 모빌아이 CEO인 암논 사슈아 교수는 자율주행 레벨 4~5 적용을 위해 2020년을 목표로 24 TFLOPS(TDP 10watt)의 성능을 제공하는 EyeQ5 개발을 진행 중 이며 EyeQ5는 앞서 설명한 인텔 GO 자율주행 플랫폼에 적용될 예정임을 발표하였다. EyeQ5 현재의 EyeQ4에 비해 DLA(Deep Learning Accelerator)가 추가 된 것이 큰 차이점이다[9].
5. 바이두 Apollo
2017년 4월 중국의 검색 서비스 업체 바이두는 자율주행플랫폼 개발을 위한 Apollo 1.0 프로젝트를 소개하며 프로젝트를 통해 개발된 자율주행 소프트웨어와 데이터를 공개하고 레퍼런스 하드웨어를 제공하겠다고 발표했고 이후 2018년 CES에서 Apollo 2.0인 Apollo Pilot을 (그림 8)과 같이 Chery 자동차에 탑재하여 자율주행 시험 주행을 시연하였다. Apollo Pilot에 사용된 하드웨어 플랫폼은 엔비디아의 Drive PX Xavier와 독일의 자동차 부품 생산 업체인 ZF사의 ProAI 컴퓨팅 기술을 적용하여 개발된 것으로 알려진다. 즉, Apollo 프로젝트의 인공지능 컴퓨팅 하드웨어는 독자적인 플랫폼을 개발하는 것보다 현재 개발되어 있는 플랫폼 기술을 적용하는 정도이고 자율주행에 필요한 오픈소스의 소프트웨어 개발에 중점을 두고 있다고 볼 수 있다.

Ⅲ. 국내 기술 동향
현대자동차 그룹은 ADAS 및 자율주행 레벨 3 이하에서는 모빌아이 플랫폼을 채택하고 레벨 4 이상에서는 엔비디아의 플랫폼을 적용하는 것으로 알려지고 있으나 실제적으로는 다양한 회사의 기술을 모두 고려하는 있는 것으로 보인다. 현대자동차 그룹은 레벨 4 자율주행차 개발을 위해 미국 스타트업 기업 오로라와 협업하고 있다고 발표했으며 엔비디아 역시 오로라와 Drive Xavier를 이용한 하드웨어 플랫폼을 개발하고 있는 상황이다.
네이버의 네이버랩스는 2017 서울모터쇼에서 IT 업체 최초로 국토부 임시주행 허가를 받은 자율주행 레벨 3 수준의 자율주행 자동차를 발표하였고 자율주행 하드웨어 플랫폼의 개발보다는 차량 자기 위치 인식, 사물의 인식 및 분류, 상황 판단 등 인공지능을 활용한 인지 중심의 자율주행 소프트웨어 기술 고도화에 중점을 두고 개발하고 있다. 2018년 5월에는 만도의 레이더 및 카메라 등 자율주행을 위한 차량 센서 기술 협력을 위해 만도와 자율주행기술 공동연구개발을 위한 MOU를 체결하였다.
국내 대부분의 업체들은 독자적인 자율주행 플랫폼을 개발하기보다는 해외의 자율주행 플랫폼을 활용하여 자율주행 자동차 및 관련 부품 개발에 적용하고 있는 상황이고 한국전자통신연구원에서는 자율주행 시장의 해외 기술 의존을 해소하고자 2016년에 인공지능 드라이빙 컴퓨팅 하드웨어 플랫폼 버전 1과 2017년에 버전 2를 발표하였다.
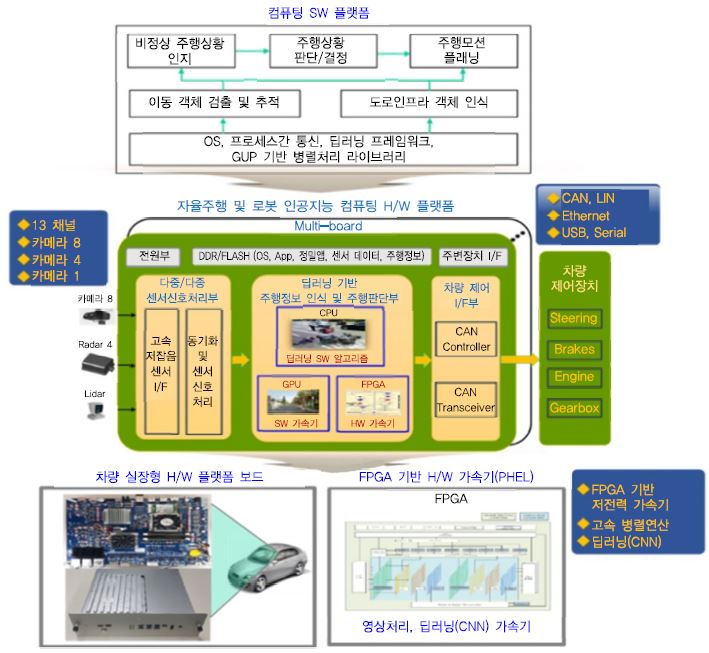
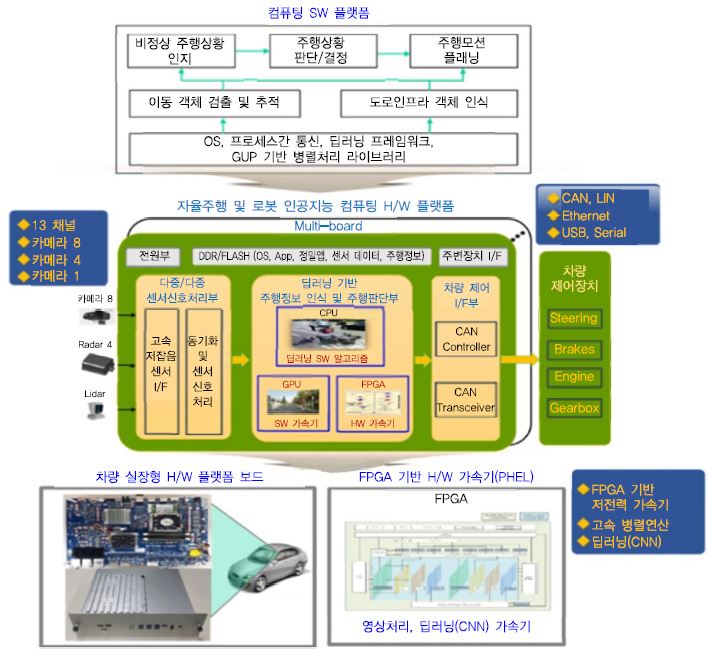
한국전자통신연구원의 인공지능 드라이빙 컴퓨팅 하드웨어 플랫폼은 자율주행 차량뿐만 아니라 로봇, 산업용 인공지능 시스템을 위한 하드웨어 플랫폼 기술로서, 카메라, 레이다, 라이다의 다중 센서 데이터를 실시간으로 입력받아 CPU, GPU, FPGA를 통해 고속으로 인공지능(딥러닝) 알고리즘을 처리할 수 있다. 자율주행 차량에 적용할 경우 다종 다채널의 센서 데이터로부터 객체를 인식하고, 주행 상황을 인지, 판단하여 주행 모션 플래닝을 수행할 수 있는 고성능의 컴퓨팅 프로세서를 지원하며 차량 제어를 위한 인터페이스를 함께 제공한다. (그림 9)는 센서 입력부터 알고리즘 처리, 차량 제어로 이어지는 프로세싱 흐름에 따른 자율주행 차량용 인공지능 컴퓨팅 하드웨어 플랫폼의 개념적 구조를 나타낸다. 객체 인식에 필요한 다종/다중의 센서 입력을 고속으로 동기화시키고 CPU의 제어를 통해 GPU에서 영상 딥러닝 알고리즘을 SW 병렬처리하며 FPGA 기반의 PHEL(Primitive HW Engine Lib.) 가속기를 통해 딥러닝 전처리 및 고속 병렬 연산을 GPU와 동시에 수행할 수 있다. 인식된 주행정보로부터 주행 경로를 결정하고 차량 제어를 위한 커맨드를 생성하며, 이는 CAN 인터페이스를 통해 차량 운행 장치들을 제어하게 된다[6].
(그림 9)
한국전자통신연구원의 인공지능 컴퓨팅 하드웨어 플랫폼 개념도
[출처] Kentaro IEMOTO, Baidu Map Car GMIC 2016, Beijing, Arp. 29, 2016, CC BY-SA 2.0.
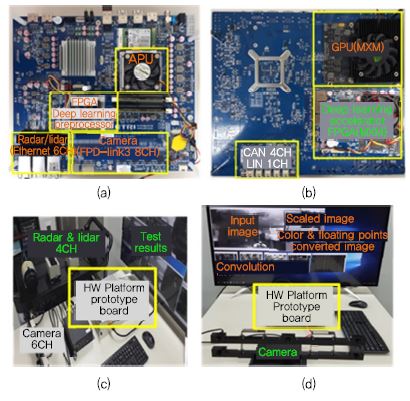
(그림 10)의 (a)와 (b)는 자율주행 및 로봇 인공지능 컴퓨팅 하드웨어 플랫폼을 구현한 PCB 시작품의 각 모듈 및 외부 인터페이스 등을 나타낸다. CPU와 GPU가 통합된 AMD의 APU(Accelerated Processing Unit)를 메인 프로세서로 사용한다. APU는 2.1~3.4GHz(터보)로 동작하는 4개의 x86 CPU 코어를 가지며 내장 GPU는 800MHz로 동작하는 R7 CU(Compute Unit) 8개로 구성되어 있으며 DDR4 2400을 지원하고 TDP는 35W이다. Full-HD 카메라 8채널을 FPD-link3의 직렬 LVDS 카메라 I/F를 통해 실시간으로 입력받을 수 있다. 레이다와 라이다는 CAN 4채널 또는 기가비트 이더넷 6채널 통해 연결될 수 있다. 보드 전면의 FPGA에는 다채널 프레임 그래버, 영상 스케일러, 칼라 변환기, 부동소수점 변환기와 같은 딥러닝 영상 전처리기가 탑재되어 있고 PCIe Gen2 4lane을 통해 APU와 연결된다. 보드 후면의 PCIe Gen3 8lane의 2개의 MXM 슬롯을 통해 외장 GPU와 딥러닝 가속기가 탑재되는 FPGA 모듈을 연결할 수 있다. 플랫폼은 CPU, GPU, FPGA와 같은 이기종 프로세서들을 PCIe 인터페이스를 통해 연동하여 8TFLOPs 이상의 연산 성능을 제공하여 다양한 프로세서들을 사용하여 딥러닝 알고리즘을 수행할 수 있다.
(그림 10)
한국전자통신연구원의 인공지능 컴퓨팅 하드웨어 플랫폼 프로토타입 보드: (a) PCB 전면, (b) PCB 후면, (c) 멀티 센서 인터페이스, (d) 딥러닝 영상 가속기
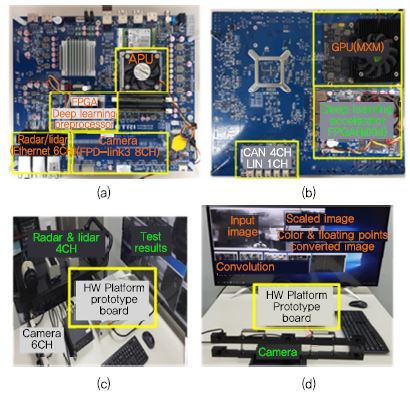
[출처] J.H. Suk et al., “A Heterogeneous and High Performance Driving Computing Hardware Platform for Autonomous Vehicles,” IEMEK Symp. Embedded Technol., Jeju, Rep. of Korea, May 24-25, 2018.
(그림 10)의 (c)는 HD 카메라 6채널, radar 1채널, lidar 3채널을 동시에 입력받아 데이터를 처리하는 테스트 장면을 나타내고 (d)는 HD YUV 입력 영상을 딥러닝 영상 전처리기를 통해 영상 프레임을 그래빙하고 스케일 다운하고 RGB 영상으로 변환한 후 32비트 부동소수점으로 변환하여 3D synapse 연산 구조를 가지는 convolution 가속기를 통해 convolution 연산을 수행한 결과를 보여준다. 딥러닝 영상 전처리기 및 convolution 가속기는 모두 FPGA를 통해 구현되었고 PCIe 인터페이스를 통해 APU와 연동된다.
한국전자통신연구원의 인공지능 드라이빙 컴퓨팅 하드웨어 플랫폼은 2019년 초에 버전 2에서 인텔의 Xeon CPU, AN-FD, 10Gpbs Ethernet 등을 새롭게 적용한 버전 3를 발표할 예정이다.
Ⅳ. 결론
현재 자율주행 기술을 적용한 자동차들이 도로 위를 시험 주행하고 있고 일부 기술에 대해서는 상용 차량에 적용되어 판매되고 있는 상황이다. 세계 유명 자동차 제조사뿐만 아니라 해외 굴지의 반도체 및 IT 소프트웨어 전문 기업들도 자율주행 자동차 시장을 겨냥하여 자율주행 솔루션 개발을 위해 막대한 자금 및 인력을 투입하여 개발에 매진하고 있으나 국내의 기술 개발 현황은 일부 대기업 위주로 해외 제품을 고액의 기술도입 비용을 지불하며 사용하고 있는 실정에 있다. 국내 중소중견 기업이 자율주행 시장 진입 및 확산을 할 수 있도록 국내 기술의 자율주행 플랫폼 개발을 위해 지속적인 노력을 기울여야 할 것이다.
약어 정리
ADAS
Advanced Driver Assistance Systems
APU
Accelerated Processing Unit
CU
Compute Unit
DLA
Deep Learning Accelerator
FPGA
Field Programmable Gate Array
MPC
Multithreaded Processing Cluster
MXM
Mobile pci-eXpress Module
PHEL
Primitive HW Engine Lib.
PMA
Programmable Macro Array
SIMT
Single Instruction Multiple Thread
SM
Streaming Multiprocessor
SMM
Maxwell Streaming Multiprocessor
TDP
Thermal Design Power
TPU
Tensor Processing Unit
VMP
Vector Micro Processor
(그림 1)
Drive PX2 보드: (a) Drive PX2 보드 전면 사진, (b) Drive PX2 보드 후면 사진

[출처] NVIDIA Corporation, CES 2016 NVIDIA Press Event, Jan. 4, 2016, CC BY NC-ND 2.0.
(그림 2)
Tegra Xavier SoC

[출처] NVIDIA Corporation, GTC China - Jensen Huang Keynote, Sept. 26, 2017, CC BY NC-ND 2.0.
(그림 3)
아우디의 자율주행 플랫폼 zFAS

[출처] NVIDIA Corporation, Audi zFAS prototype with Tegra VCM, Jan. 8, 2014, CC BY-NC-ND 2.0.

(그림 5)
Atom 프로세서 기반 인텔 GO

[출처] Антон Спиридонов / Hi-Tech@Mail.ru [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)]
(그림 6)
Xeon 프로세서 기반 인텔 GO

[출처] Антон Спиридонов / Hi-Tech@Mail.ru [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)]
(그림 7)
EyeQ2가 적용된 lane guidance system

[출처] Binarysequence, The PCB and camera module from a Hyundai Lane Guidance camera module, Mar. 19, 2013, CC BY-SA 3.0
(그림 8)
바이두 자율주행 자동차

[출처] Kentaro IEMOTO, Baidu Map Car GMIC 2016, Beijing, Arp. 29, 2016, CC BY-SA 2.0.
(그림 9)
한국전자통신연구원의 인공지능 컴퓨팅 하드웨어 플랫폼 개념도
[출처] Kentaro IEMOTO, Baidu Map Car GMIC 2016, Beijing, Arp. 29, 2016, CC BY-SA 2.0.
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.