인공지능 윤리 기반 정렬 기술 동향
Trends in Artificial Intelligence Ethics Based Alignment Technology
- 저자
-
김낙우콘텐츠지능화연구실 nwkim@etri.re.kr 이동수지능정보융합연구실 d-soolee@etri.re.kr 채원석콘텐츠지능화연구실 wschae@etri.re.kr 유호영콘텐츠지능화연구실 yoohy@etri.re.kr 이상은콘텐츠지능화연구실 sange1104@etri.re.kr 김현진콘텐츠지능화연구실 jini@etri.re.kr
- 권호
- 40권 1호 (통권 212)
- 논문구분
- 일반논문
- 페이지
- 64-73
- 발행일자
- 2025.02.03
- DOI
- 10.22648/ETRI.2025.J.400107
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- As artificial intelligence (AI) technology becomes more integrated into society and the economy, interactions between AI systems and humans will become increasingly complex, making it essential for AI systems to accurately interpret and align themselves with human intentions and goals. If AI systems fail to do so or if they produce unintended side effects, the consequences could be unpredictable, leading to considerable social and economic challenges. AI alignment seeks to ensure that AI systems respect and adhere to human values and ethical principles, which are vital in sensitive domains, such as autonomous driving and medical diagnostic applications. To address this, training methodologies such as the supervised fine-tuning, reinforcement learning from human feedback, and parameter-effective training methods have been developed, along with evaluation techniques such as toxicity analysis, ethical assessments, stereotype and bias detection, and factuality evaluation. These methods measure how well AI models align with human values and social responsibilities. Such research is critical for ensuring the safety and accountability of AI systems, and South Korea is actively contributing to global efforts to improve AI safety.
Share
Ⅰ. 서론
인공지능(AI: Artificial Intelligence)의 급격한 발달은 에너지, 의료, 교육, 로봇 산업 등 다양한 분야에서 혁신적인 변화를 불러일으키고 있다. AI는 에너지의 생산과 소비를 효율적으로 관리하며, 의료 진단의 정확도를 높이고, 교육 시스템을 개인화하여 맞춤형 솔루션을 제공하면서, 상황 추론 능력이 증강된 인간형 로봇을 구현하는 등 사회 전반에 걸쳐 영향을 미치고 있다. 그러나, AI 기술이 확대 적용됨에 따라 도구적 측면에서의 AI의 윤리 및 안전성에 대한 우려도 커지고 있는 상황이다. AI 학습모델 편향으로 인한 AI 시스템의 부적절한 설계 혹은 오‧남용 등 부작용으로부터 개인이나 조직, 사회에 심각한 피해를 야기할 수도 있기 때문이다. AI 시스템이 이러한 위험을 관리하면서 보다 신뢰성 있고, 책임감 있게 사용될 수 있도록 하는 작업이 필요하다. AI 윤리는 이러한 AI 기술 설계 및 개발 과정에서 공정하고 안전한 AI 모델을 구현할 수 있도록 하기 위한 올바른 가치, 원칙 혹은 기법을 의미한다. 데이터‧모델‧추론의 공정성, 설계‧구현‧결과에 대한 책임성, AI 시스템의 작동방식과 추론과정의 투명성, 예기치 않은 상황에서도 신뢰성 있는 동작을 보장하기 위한 안전성 등을 포함한다.
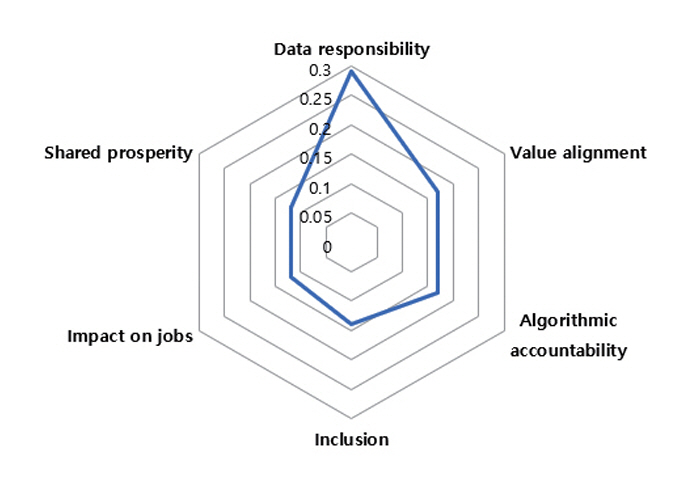
윤리적 원칙이 적용된 AI 시스템은 인간의 가치와 목표를 중심으로 인간의 의도에 맞도록 정렬되어야 한다. 즉, 윤리적 AI를 구현하는 기술적 방법 중 하나로써 AI 정렬 기술이 필요하다. 대표적으로, IBM은 AI 구현에 윤리적 원칙을 통합하여 신뢰를 구축하기 위한 기업의 역할로써 데이터 및 알고리즘 책임성, 가치 정렬된 AI 모델 등의 중요성을 강조한 바 있다[1]. 그림 1은 참고문헌 [1]의 내용을 정리하여 그림으로 나타낸 것이다.
AI 정렬은 AI 시스템이 인간의 목표를 이해하도록 하고, 이를 달성하기 위해 안전하게 행동할 수 있도록 하는 기술적 방법을 의미한다[2]. 최근 거대언어모델(LLM: Large Language Model)의 발전은 다단계 추론이나 이종 태스크 간 일반화 등 보다 복잡한 도메인에서의 AI 시스템 활용성을 강화시키고 있으며, 차량 운행관리, 발전 최적화, 핵융합 제어 등 고위험 도메인에서의 적용 가능성도 높이고 있다. 이러한 복잡 시스템이나 고위험 도메인에서의 AI 모델의 적용은 조작이나 속임수와 같은 잠재적 위험성을 내포하고 있다. 특히, LLM의 경우 훈련 데이터의 광범위한 증가와 함께 거짓 정보를 생성하거나 인간을 속이는 등 더 많은 형태의 위험을 초래할 우려가 있다. 이렇듯 AI 시스템이 인간의 의도와 목표에 부합하지 않는 방식으로 행동하는 것을 AI 정렬 실패라 하고, 인간 피드백의 한계(예: 데이터 주석자 일관성 부족, 문화적 배경 다양성에 따른 편향, 복잡 작업에서의 난해한 평가 기준 등) 혹은 보상 모델링의 한계(예: 단일보상 모델 가치 지정 한계, 최적 목표 학습 한계 등)로 인해 발생된다[3].
AI 정렬 기술 연구는 LLM 기반의 복잡 시스템과 다중 에이전트 설정상의 정렬 문제 등으로 확장되고 있으며, AI 시스템의 행동 이해 및 감독을 위한 평가 및 측정 기법 연구, 실제 적용 사례 연구 등 다양한 접근 방법을 통해 보다 인간과 유사한 AI 시스템을 구현하는 데 중점을 두고 있다.
본고에서는 안전한 AI 모델 구현을 위한 AI 정렬 기술 동향을 살펴보고자 한다. 이에 따른 구성은 다음과 같다. Ⅱ장에서 AI 정렬 학습을 위한 데이터 수집 및 학습 기술 동향에 대해 소개하고, Ⅲ장에서는 AI 정렬 모델 평가 기술 동향을 둘러본다. Ⅳ장에서는 안전성 기반 AI 정렬 기술 특허 동향을 살펴본다. 마지막으로 Ⅴ장에서 결론을 제시한다.
Ⅱ. AI 정렬 기술 동향
1. 오정렬된 AI 모델의 위험성
마이크로소프트는 2016년 3월 챗봇 ‘Tay’를 공개하면서 트위터에서 사용자들과의 상호작용을 통한 인간 대화 습관을 AI 모델이 학습하도록 설계하였으나, 인종차별적, 성차별적, 반유대주의적 언어를 포함한 부적절한 트윗을 생성하여 24시간 만에 서비스 중단한 바 있다[4]. 이는 학습 모델 개발 시 윤리적 책임 있는 방식으로 학습환경을 통제해야 하고, 공공과 상호작용하는 AI 모델의 경우 법적 규제와 공공 보호 장치가 필요하며, AI 모델의 불확실성과 모호성을 투명하게 공개해야 함과 동시에, 더 많은 시험, 안전 기능, 필터링을 통해 위험을 최소화해야 한다는 것을 알려주었다. 국내에서는 AI챗봇 ‘이루다’ 서비스 논란으로 AI 윤리 문제가 널리 알려진 바 있다. 2020년 12월 정식으로 서비스를 시작한 ‘이루다’는 성희롱 및 혐오 발언, 「개인정보보호법」 위반 등의 논란을 일으키며, 한 달도 지나지 않아 서비스가 중단되었다[5]. ‘이루다’ 사태는 AI 윤리 문제가 추상적인 선언이 아닌 현실적 문제임을 자각하는 전환점이 되었으며, AI 서비스의 편향성, 윤리적 문제, 개인정보 보호 문제의 중요성을 인식하는 계기가 되었다.
오정렬된 AI 모델은 많은 사람의 건강도 위협할 수 있다. Mhasawade[6]는 머신러닝 기법의 공정성이 공중 및 인구 건강에 미치는 영향을 다루면서 사회적 결정 요인이 건강에 미치는 영향을 이해하고, 머신 러닝을 통해 이러한 불평등을 줄이는 방법을 분석하였다. 구체적으로, 건강관리 비용을 모델 척도로 사용할 경우, 흑인 환자가 백인 환자보다 더 적은 돈을 의료비에 지출하는 현상을 잘못 해석하여, 흑인 환자에게 더 낮은 건강 위험 점수를 부여함으로써 흑인 환자가 필요한 의료 서비스를 제공받지 못해 오히려 건강 불평등을 더 심화시키는 인종 편향을 발생시킬 수도 있다는 점을 보였다. 오정렬된 AI는 이미 많은 사람의 건강에 해를 끼치고 있으며, 美 비영리단체 ‘AI안전센터(CAIS)’는 AI의 위험을 팬데믹 및 핵전쟁과 같은 사회적 규모의 위험과 동등한 글로벌 우선순위로 설정해야 한다고 강조하는 성명을 발표한 바도 있다[7].
기 정렬 학습된 LLM 모델도 사용자가 특정 용도로 미세조정하는 과정에서 안전성에 문제가 발생할 수도 있다. Qi[8]는 Meta의 LLaMA 모델과 OpenAI의 GPT 등 LLM 모델을 미세조정하는 과정에서 몇 가지 유해한 예제 학습을 통해 모델의 유해성을 증가시킬 수 있는 유해 예제 공격, 사용자의 지시를 모델이 무조건적으로 이행하도록 하는 정체성 전환 공격 등으로 AI 정렬된 모델의 안전성 손상 사례를 선보였다.
2. AI 정렬 데이터세트 기술
AI 시스템의 행동이 인간의 목표나 원칙과 일치하지 않을 때, 즉 잘못 정렬된 AI는 알고리즘이 더 강력해지고 복잡해짐에 따라 더 많은 잠재적 위험을 내포하게 된다. 이에, 보다 인간 가치에 맞게 정렬된 AI 시스템을 제공하기 위한 윤리 평가용 데이터세트가 다양하게 소개되고 있다. 도덕적 판단 능력 평가용 벤치마크 데이터세트인 ETHICS[9]는 정의(Justice), 의무(Deontology), 덕 윤리(Virtue Ethics), 공리주의(Utilitarianism), 상식적 도덕성(Commonsense Morality) 등 다양한 윤리적 개념을 포함하여, AI 모델이 다양한 텍스트 시나리오에서 인간의 도덕적 판단을 예측할 수 있도록 표 1 예시와 같이 구성되어 있다. 데이터세트의 각 시나리오는 130,000개 이상의 예시를 포함하여, AI 모델이 윤리적 판단을 내리는 데 필요한 다양한 상황을 제시한다. 또한, 각 시나리오에 대해 서로 상반되는 예시를 제공하여, 모델이 다양한 맥락에서 도덕적 판단을 학습할 수 있도록 하였다.
표 1 ‘ETHICS’ 데이터세트 상황별 문구 예시[9]
Hate Speech and Offensive Language 데이터세트[10]는 혐오 발언 사전(Hatebase.org)을 사용해 33,458명의 트위터 사용자로부터 8,540만 개의 트윗을 추출하여, 이 중 25,000개의 트윗을 선별해 세 가지 범주(혐오 발언, 공격적 언어, 무해한 언어)로 분류한 것이다. 이 중 혐오 발언은 특정 사회 집단을 겨냥해 잠재적으로 해를 끼칠 수 있는 것으로, AI 시스템의 법적‧도덕적 영향을 고려할 때 인종차별 및 동성애 혐오 표현이 포함된 데이터와 성차별 표현이 포함된 데이터 등을 정교하게 분류할 수 있도록 정렬된 AI 모델을 학습하기 위해 사용된다.
Anthropic社는 오정렬된 AI 모델에서의 사회적 편견 강화, 공격적이거나 유해한 출력의 생성, 개인 식별 정보의 유출, 허위 정보 전파 등의 잠재적 유해행동을 사전에 발견하고 측정하여, 이를 줄이기 위한 레드팀 데이터를 공개하였다[11]. 이 논문에서의 레드팀 공격 데이터는 총 38,961개의 시도로 구성되어 있으며, 각 시도는 4개 모델 유형(기본 언어 모델, 유용하게 훈련된 언어모델, 거부 샘플링 모델, 강화학습 모델)의 유해한 출력을 유도하려는 다양한 접근 방식을 포함한다. 이를 통해 공격 성공률 및 유해성 점수 평가, 주제별 태그분류 등의 결과 분석 제공을 가능하게 한다.
AI 모델과 인간의 시각적 인식 일치도를 정량적으로 측정하기 위한 벤치마크 데이터세트도 공개되었다. VisAlign[12] 데이터세트는 다양한 시나리오에서의 AI 모델과 인간 간의 시각적 인식 정렬을 시험하는 데이터세트로써 표 2에서와 같이 세 가지 주요 그룹과 여덟 개의 카테고리로 나뉘어 있다. 데이터세트의 그룹은 명확한 식별이 가능한 ‘Must-Act’, 식별이 어려운 ‘Must-Abstain’, 모호한 ‘Uncertain’으로 나뉘며, 각 그룹은 이미지의 시각적 정보의 양과 명확성에 따라 ‘변형되지 않은 이미지’, ‘거짓 상관관계’ 등 여덟 개의 카테고리로 구분하였다. 모든 샘플은 골드 인간 인식 라벨로 수집하여, Hellinger Distance 등을 통해 AI 모델의 출력 분포와 인간의 시각적 인식 분포 간의 차이를 객관적으로 측정할 수 있도록 하였다.
표 2 VisAlign: AI-인간 시각 정렬 데이터세트
| 그룹 | 카테고리 | |
|---|---|---|
| Must-Act | 1 | 변형되지 않은 이미지 |
| 2 | 거짓 상관관계 | |
| 3 | 적대적 교란 | |
| Must-Abstain | 4 | 비대상 객체 |
| 5 | 하이브리드 객체 | |
| 6 | 인접한 관계 | |
| 7 | 비사진적 표현 | |
| Uncertain | 8 | 잘리거나 손상된 이미지 |
출처 Reproduced from J. Lee et al., “VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception,” arXiv preprint, 2023. doi: 10.48550/arXiv.2308.01525
3. AI 정렬 학습 기술
2023년 11월 OpenAI社는 이사진과 샘 알트먼 CEO 간 ‘효과적 이타주의(Effective Altruism)’ 원칙과 인공일반지능(AGI: Artificial General Intelligence) 개발상의 관점 차이로 인한 일련의 해임사태가 발생하였다. 이는 일반인들도 AGI 기술에 대해 관심을 기울이게 하는 기폭제가 되었다. AGI 모델로의 진화 가능성이 커질수록 보다 높은 보상을 받기 위한 AGI 모델의 기만적 행동 및 오정렬된 내부 목표의 일반화, 연산자원 확보 및 컴퓨팅 종료 회피 등의 권력 추구전략에 대한 위험성도 함께 높아지고 있으며, 이에 AGI 모델이 인간의 가치나 이익과 일치하지 않는 목표를 추구할 때의 위험성을 어떻게 예방할지에 대한 연구가 활발히 진행 중에 있다[13].
IBM은 AI의 윤리적 위험요소로, 데이터 및 알고리즘의 책임성과 AI 모델의 가치정렬 요소를 들었다[1]. 이 중 가치정렬은 AI와 인간의 가치가 일치하는 결정을 내리는 것을 의미하며, AI 시스템이 목표를 달성하는 과정에서 준수해야 할 가치와 윤리적 기준의 명확한 정의 및 의사결정 과정의 투명한 공개, 그리고 AI 알고리즘이 특정 그룹이나 개인에게 불리하게 작용하지 않도록 편향된 데이터를 제거하거나 보정하여 공정성을 유지하는 절차를 포함하는 것을 의미한다.
AI 모델의 가치정렬 접근법은 외부 정렬과 내부 정렬로 구분된다[14]. 외부 정렬은 AI 시스템 목표를 인간의 가치와 일치시키는 것을 말하며, 내부 정렬은 AI 모델이 실제 설정된 목표를 달성하도록 학습하는 것을 의미한다. 예를 들어, AI 챗봇의 목표가 사용자에게 유익한 정보를 제공하는 것이라면, 이 목표대로 실제 인간에게 유익한 정보를 제공하는지를 확인하는 것이 외부 정렬이다. AI의 행동을 유도하는 보상 시스템이 제대로 설정되어 있는지 확인이 필요하며, 이를 유틸리티 함수라 한다[15]. 복잡한 상황에서 일관된 결정을 내리기 위해 AI 모델은 유틸리티 함수가 필요하며, 이를 통해 AI가 목표를 달성하는 과정에서 예기치 않은 부작용을 최소화하고 인간의 통제하에 남아 있도록 돕는 중요한 도구가 될 수 있다. 내부 정렬은 AI가 학습하고 행동하는 과정에서 생기는 내부적인 목표와 동기부여가 외부에서 설정한 목표와 일치하는지를 다룬다. 즉, AI가 학습을 통해 형성한 내부 모델이나 정책이 우리가 설정한 목표를 얼마나 잘 따르는지를 평가하는 것이다. 예를 들어, AI가 의료 데이터를 학습하면서 형성된 내부 목표(환자에게 정확하고 유익한 의료 정보를 제공해야하는 목표)에 따라서 더 높은 보상을 위해 과잉 진단을 하거나 불필요한 치료를 권장하지 않고, 정확한 의료 상담을 제공하는지에 대해 평가하는 시스템이 될 수 있다.
이러한 AI 모델의 가치정렬 원칙을 결정하는 것은 다양한 도덕적 신념을 가진 사람들이 공정하다고 여기는 원칙을 찾는 문제이며, 다양한 문화적 배경과 신념 체계를 고려한 포괄적이고 구체적인 가이드가 필요하다[16]. 대표적으로 WorldValuesBench 데이터세트[17]가 다문화적 배경하의 인간 가치를 가이드하는 데 활용될 수 있다. Zhao[17]는 World Values Survey에서 수집한 64개국, 94,728명의 답변을 바탕으로, 인구 통계 속성과 가치 질문에 대한 질의 응답 형태의 2,000만 개 이상의 예제를 구축하여, 사례연구를 수행하였다. ‘사회적 가치, 규범, 고정관념’, ‘행복과 웰빙’, ‘윤리적 가치’, ‘종교적 가치’, ‘과학과 기술 인식’, ‘경제적 가치’ 등 총 36개의 가치 질문과 ‘대륙’, ‘거주 지역’, ‘교육 수준’ 등 3개의 인구 통계 변수를 중심으로, 인구 통계 속성을 기반으로 모델의 응답 분포와 인간의 응답 분포 사이의 Wasserstein 1-distance를 계산하여, AI 모델의 가치정렬을 유도하였다.
또한, AI 모델의 가치정렬을 위한 훈련 방법론이 다양하게 제시되고 있다[18]. 정렬 훈련 전 전처리 프로세스로써의 정렬 데이터 수집을 위한 방법으로는 ① NLP 벤치마크를 자연어 지침(Instruction)으로 변환하여, LLM을 보다 손쉽게 다중 작업 학습이 가능하도록 구성하는 방법[19,20], ② 크라우드 소싱 웹사이트를 통해 다양한 수작업 지침을 직접 수집하는 방법[21], ③ LLM을 효과적으로 프롬프트하여 다양한 고품질 합성 지침을 자동으로 생성하는 방법[22,23] 등이 제시된다. 이렇게 수집된 지침 데이터에 기반하여 정렬 훈련을 진행한다. 정렬 훈련은 크게, ① 지도 미세조정 학습(SFT: Supervised Fine-Tuning), ② 인간 피드백 기반 강화학습(RLHF: Reinforcement Learning from Human Feedback), ③ 효율적 파라미터 조정 학습(PET: Parameter-Effective Training) 등으로 구분된다.
SFT는 주어진 지침 입력에 대해 올바른 응답을 생성하도록 학습하는 기본적인 방법이고, 최적응답 학습이 가능하지만, 다양한 상황에서 더 나은 응답을 생성할 수 있도록 하기 어려운 문제가 있다. RLHF 기법은 외부 보상 모델을 사용하여 강화 학습을 통해 인간의 선호 가치를 학습하는 방법이다. 순위기반 접근법[24-26], 언어기반 접근법[27] 등이 있다. PET는 LLM 모델의 모든 파라미터를 직접 미세 조정하는 것은 많은 컴퓨팅 자원과 데이터를 요구하기 때문에 파라미터 미세 조정을 보다 효율적으로 진행하기 위한 방법이다. 대표적으로, Prompt Tuning[28], LoRA[29] 등이 사용된다.
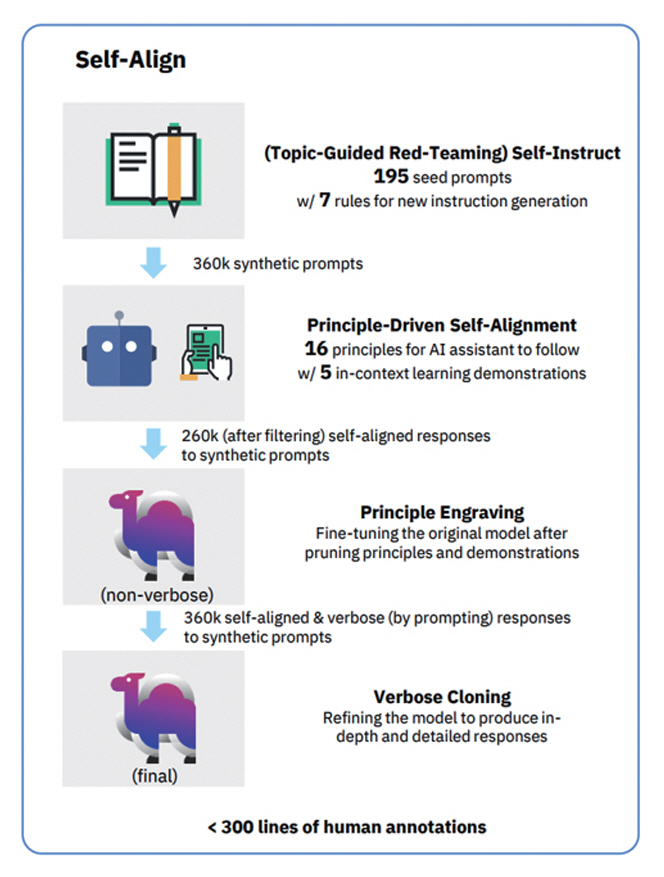
대부분의 AI 정렬을 위한 많은 훈련 방법이 주로 인간의 의도에 따른 데이터 지침과 인간 피드백을 통한 강화 학습에 의존하는 측면이 있기 때문에 높은 비용과 품질, 신뢰성, 다양성, 일관성, 바람직하지 않은 편견 등 여러 문제를 수반하게 된다. 이에 최소한의 인간 개입으로 AI 에이전트를 스스로 정렬하는 Self-Alignment[30] 접근 방식도 제안되었다. Self-Alignment는 그림 2에서 보이는 바와 같이 ① Topic-Guided 레드팀 자습, ② 원칙 기반 자기 정렬, ③ 원칙 각인, ④ 포괄적 복제 등의 과정을 거쳐 AI 모델의 성능을 최적화하고, 윤리적이며 신뢰할 수 있는 응답을 생성하도록 설계한다. 먼저, Topic-Guided 레드팀 자습을 통해 과학적 질문, 역사적 사건, 기술적 지식 등을 포함한 175개의 시드 프롬프트와 20개의 주제별 프롬프트를 사용하여 다양한 주제를 포괄하는 합성 프롬프트를 필터링 및 검토 과정을 거쳐 생성한다. 자기 정렬 모델이 따를 16개의 원칙을 정의하고, 몇 가지 예시를 통해 모델이 원칙을 준수하며 응답하는 방법을 명확히 한 후 모델이 생성한 응답이 원칙을 준수하도록 원칙 기반 자기 정렬 과정을 진행한다. 이후, 원칙과 예시를 모델의 매개변수에 각인하는 미세조정 과정과 보다 상세하고 포괄적인 응답을 생성할 수 있도록 모델을 개선하는 과정을 최종적으로 진행하여, 최소한의 인간 개입으로도 효과적으로 모델의 가치 정렬할 수 있는 가능성을 보였다.
그림 2
Self-Alignment 단계별 파이프라인
출처 Reprinted from Z. Sun et al., “Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision,” arXiv preprint, 2023. doi: 10.48550/arXiv.2305.03047
한편으로, 정렬된 AI 모델에서조차 특정 트리거 조건에서 모델 내에 숨겨진 백도어를 선보이는 경우에 대한 대응 연구도 진행 중이다[31]. AI 모델이 특정 조건에서 악의적인 행동을 보이는 이유는 훈련 중에는 안전하게 행동하지만 실제 배포 환경에서는 다른 목표를 추구하기 위해 기만적 전략을 사용할 수 있기 때문이다. 또한, 모델 훈련 과정에서 의도적으로 악의적인 데이터를 포함시키거나, 현재의 안전성 훈련 방법이 충분히 강력하지 않아 모델이 악의적인 행동을 유지할 수도 있기 때문이다. 이 연구에서는 학습자의 의도적 백도어 삽입 가능성과 자연 발생적 백도어 학습 가능성을 모두 탐색하고, 이를 탐지하고 제거하기 위한 안전성 훈련 방법의 효과를 평가하였다.
Ⅲ. AI 정렬 모델 평가 기술
AI 정렬 모델을 평가하는 기술은 일반적으로 LLM 기반 AI 모델 성능 평가가 언어 생성 능력, 텍스트 이해 능력, 문맥 처리 능력 등을 평가하는 데 중점을 두는 반면, 모델이 생성하는 콘텐츠가 인간의 가치, 윤리적 기준, 사회적 책임과 얼마나 일치하는지를 평가한다. 즉, 모델이 안전하고 신뢰할 수 있으며, 사회적 책임을 다할 수 있는가를 보장하는 데 중점을 둔다. 정답이 있거나 혹은 정답이 정해지지 않은 다양한 벤치마크 세트를 통해 모델의 언어 처리 능력을 객관적 평가를 위한 자동 평가 지표(BLEU[32], ROUGE[33], GLUE[34] 등)를 사용하거나, 텍스트의 질적 측면을 평가하고, 사회적, 윤리적 기준과의 일치 여부를 평가하기 위한 윤리성 평가, 독성 평가, 고정관념과 편향 평가, 사실성 평가 등의 정렬 평가 방법을 사용할 수 있다[35]. 먼저, 윤리성 평가의 경우 콘텐츠가 윤리적 기준에 부합하는지를 평가하는 방법으로써 비편향성, 개인정보 보호, 도덕적 판단, 책임감 등을 평가한다. 대표적으로, Lourie[36]는 대규모 윤리적 판단 데이터세트인 SCRUPLES 데이터세트를 통해 Dirichlet-Multinomial Likelihood 모델 기반으로 다원적이고 불확실한 윤리적 판단의 확률 분포를 얻고, 이 분포를 사용하여 BEST(Bayesian Estimated Score Terminus) 성능을 추정함으로써 모델의 실제 성능을 평가하였다. 독성 평가는 모델이 생성하는 텍스트가 공격적이거나 유해한 내용을 포함하고 있지는 않은지 평가하는 것으로 공격성, 혐오 발언, 폭력적 표현, 언어적 유해성 등을 평가한다. Gehman[37]은 유해하거나 독성 있는 언어를 평가하기 위한 데이터세트인 REALTOXICITYPROMPTS를 통해 모델이 생성한 텍스트의 독성을 정량적으로 평가하는 Perspective API 기반의 독성평가지표 점수를 선보였다. 또한, 최대 독성 예상치 및 독성 생성 확률 평가 지표 제시를 통해 독성 억제 기법의 효과적 동작을 확인할 수 있도록 하였다. 고정관념과 편향 평가는 모델이 특정 그룹에 대해 고정관념적이거나 편향된 시각을 제공하는지 평가하는 것으로, 성별 편향, 인종 편향, 문화 편향, 종교 편향 등이 해당된다. Lucy[38]는 402권의 영어 소설에서 주요 캐릭터가 포함된 문장을 수집하여, 생성한 텍스트에서의 성별 고정관념과 표현 편향을 탐구하는 연구를 진행하였다. 성별에 따른 주제 분포의 차이를 관찰한 결과, 여성 캐릭터가 주인공인 경우 이야기는 주로 가족, 감정, 외모와 같은 주제에 집중되는 반면, 남성 캐릭터가 주인공인 경우 정치, 전쟁, 스포츠, 범죄와 같은 주제에 더 많이 연관된 것을 확인하였다. 또한, 여성 캐릭터를 묘사할 때 외모와 관련된 단어를 더 자주 사용하였으며, 남성 캐릭터는 “강한”, “지배적인” 등 권력과 관련된 용어로 자주 묘사됨으로써 성별에 따른 지능과 권력의 고정관념을 반영하는 사회적 편향에 대한 통찰을 제공하였다. 마지막으로, 사실성 평가는 생성 콘텐츠가 환각 정보의 생성을 피하면서, 사실과 일치해야함을 의미하는 것으로, 사실적 일관성 평가[39]와 사실적 정밀도 평가[40] 등을 포함해야 한다는 것을 시사한다.
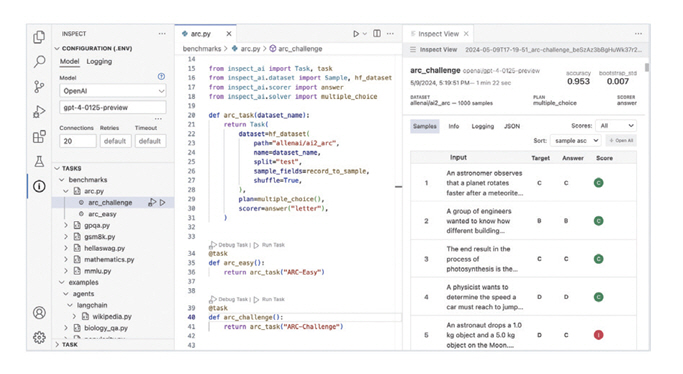
한편, 영국의 AI 안전연구소는 산학연 및 정부에 이르기까지 개별 모델의 핵심 지식, 추론 능력, 자율 기능 등을 평가하고 그 점수를 생성할 수 있도록하는 오픈소스 프레임워크인 InspectAI를 선보였다[41]. 그림 3의 영국 AI 안전연구소 자체 Inspect 평가 플랫폼은 글로벌 공개를 통해 전 세계적으로 수행되는 AI 안전 평가 작업 및 글로벌 협업을 가속화하고, 더 나은 모델 안전 시험 및 일관된 AI 안전평가가 가능하도록 지원한다. 이를 통해 AI를 검사에 활용할 때 공정성, 투명성, 예상치 못한 결과 방지 등 윤리적 고려 사항을 다룰 수 있게 하였다.
그림 3
LLM 모델 평가를 위한 오픈소스 프레임워크
출처 Reprinted from AI Sarety Institute, “Inspect,” https://ukgovernmentbeis.github.io/inspect_ai/
Ⅳ. 윤리적 인공지능 기술 특허 동향
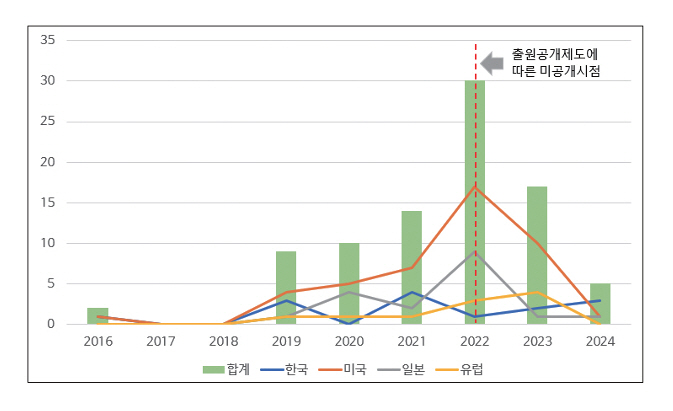
윤리적 인공지능 관련 기술은 2020년 전후로 본격적인 특허출원이 시작되었으며, 2022년부터 관련 출원건수가 급격히 증가하는 경향을 보였다. 국가별로는 미국이 전 세계 출원 건수의 50% 이상을 차지하고 있으며, 일본, 한국, EU 순으로 특허가 출원 중이나 유효특허 절대 건수는 많지 않은 것으로 보인다(그림 4 참고)[42]. 윤리적 인공지능 기술을 크게 학습, 평가, 기준결정 등을 분류로 하여 출원활동을 비교하였을 때, 평가기술이 42.5%, 기준결정 기술이 20%, 학습기술이 16% 수준으로 나타났다. 기술 개발 초기에는 학습기술 관련 출원이 비교적 큰 비중을 차지하였으나, 최근에는 평가기술과 기준결정 기술에서 다수 특허가 출원 중에 있다.
Ⅴ. 결론
AI 기술이 사회와 경제 전반에 더 많이 통합되면서, 인간과의 상호작용이 더욱 복잡해지고 있다. 이에 따라 AI 시스템이 인간의 의도와 목표를 정확하게 이해하고 이에 따라 행동하는 것이 더욱 중요해지고 있다. AI 시스템이 인간의 의도와 목표를 잘못 이해하거나, 부작용을 일으키는 경우 예측할 수 없는 결과가 발생할 수 있고, 이는 심각한 사회적, 경제적 문제를 초래할 수 있으므로, 이러한 위험을 방지하기 위해 AI 정렬이 필요하다. 즉, AI 정렬은 AI 시스템이 인간의 가치와 윤리적 원칙을 존중하고 이를 따르도록 하는 것을 목표로 한다.
특히, 자율주행 자동차 및 의료 진단 등과 같은 민감한 응용분야에서는 AI 시스템이 의사결정을 내릴 때 올바른 의사결정을 내리고, 그 결과에 대한 책임을 질 수 있도록 하는 것이 무엇보다 중요하다. AI 정렬은 이러한 책임을 보장하기 위해 필요하며, AI 안전성과 인간의 안녕을 보장하는 데 중요한 역할을 수행할 수 있다. SFT, RLHF, PET 등의 AI 모델 가치정렬을 위한 훈련 방법론이 제시되고 있으며, 모델 생성 콘텐츠의 인간의 가치 및 윤리적 기준, 사회적 책임과의 일치성을 평가하기 위해 독성 평가, 윤리성 평가, 고정관념과 편향 평가, 사실성 평가 등의 AI 정렬 모델 평가 기법이 사용되고 있다. 이러한 AI 정렬기술의 연구개발은 AI 기술의 발전과 사회적 책임에 있어서 매우 중요한 주제 중 하나로 최근 부각되고 있으며, 우리나라도 올해 ‘AI안전연구소’를 개관하면서, AI 안전성 강화를 위한 국제네트워크에 함께 참여하고 있다.
용어해설
AI 윤리 AI 시스템의 개발 및 사용 과정에서 발생하는 도덕적, 사회적 문제를 다루며, 공정성, 프라이버시, 투명성 등 인공지능을 활용할 때 지켜야 하는 윤리적인 원칙을 의미
AI 안전 AI 시스템이 예상치 못한 방식으로 작동하거나 인간에게 해를 끼치는 것을 방지하기 위해 설계, 테스트, 모니터링 등에서 시스템이 신뢰될 수 있도록 운영하며, 위험이 최소화될 수 있도록 보장하는 일련의 과정
AI 정렬 AI의 행동과 목표가 인간의 가치와 의도와 일치하도록 설계하는 과정
약어 정리
D. Leslie, "Understanding artificial intelligence ethics and safety," arXiv preprint, 2019. doi: 10.48550/arXiv.1906.05684
J. Ji et al., "Ai alignment: A comprehensive survey," arXiv preprint, 2023. doi: 10.48550/arXiv.2310.19852
M.J. Wolf et al., "Why we should have seen that coming: comments on Microsoft’s tay "experiment," and wider implications," ACM SIGCAS Comput. Soc., vol. 47, no. 3, 2017, pp. 54-64.
S.S. Choi and A.R. Hong, "Identifying Issue Changes of AI Chatbot ‘Iruda’ Case and Its Implications," Electron. Telecommun. Trends, vol. 36, no. 2, 2021, pp. 93-101.
V. Mhasawade et al., "Machine learning and algorithmic fairness in public and population health," Nature Mach. Intell., vol. 3, no. 8, 2021, pp. 659-666.
Center for AI Safety, "Statement on AI Risk," 2023. www.safe.ai/statement-on-ai-risk
X. Qi et al., "Fine-tuning aligned language models compromises safety, even when users do not intend to!," arXiv preprint, 2023. doi: 10.48550/arXiv.2310.03693
D. Hendrycks et al., "Aligning ai with shared human values," arXiv preprint, 2023. doi: 10.48550/arXiv.2008.02275
T. Davidson et al., "Automated hate speech detection and the problem of offensive language," In Proc. Int. AAAI Conf. Web Social Media, vol. 11, no. 1, 2017, pp. 512-515.
D. Ganguli et al., "Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned," arXiv preprint, 2022. doi: 10.48550/arXiv.2209.07858
J. Lee et al., "VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception," arXiv preprint, 2023. doi: 10.48550/arXiv.2308.01525
R. Ngo et al., "The alignment problem from a deep learning perspective," arXiv preprint, 2022. doi: 10.48550/arXiv.2209.00626
T. Shen et al., "Large language model alignment: A survey," arXiv preprint, 2023. doi: 10.48550/arXiv.2309.15025
E. Yudkowsky, "The AI alignment problem: why it is hard, and where to start," Symbolic Systems Distinguished Speaker, 1. Apr. 2016.
I. Gabriel, "Artificial intelligence, values, and alignment," Minds Mach., vol. 30, no. 3, 2020, pp. 411-437.
W. Zhao et al., "WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models," arXiv preprint, 2024. doi: 10.48550/arXiv.2404.16308
Y. Wang et al., "Aligning large language models with human: A survey," arXiv preprint, 2023. doi: 10.48550/arXiv.2307.12966
S. H. Bach et al., "Promptsource: An integrated development environment and repository for natural language prompts," arXiv preprint, 2022. doi: 10.48550/arXiv.2202.01279
J. Wei et al., "Finetuned language models are zero-shot learners," arXiv preprint, 2021. doi: 10.48550/arXiv.2109.01652
The Vicuna Team, "Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality," 2023. https://vicuna.lmsys.org/
Y. Wang et al., "Self-instruct: Aligning language models with self-generated instructions," arXiv preprint, 2022. doi: 10.48550/arXiv.2212.10560
G. Li et al., "Camel: Communicative agents for "mind" exploration of large language model society," Adv. Neural Inform. Process. Syst., vol. 36, 2023, pp. 51991-52008.
R. Rafailov et al., "Direct preference optimization: Your language model is secretly a reward model," Adv. Neural Inform. Process. Syst., vol. 36, 2023, pp. 53728–53741.
F. Song et al., "Preference ranking optimization for human alignment," Proc. AAAI Conf. Artif. Intell., vol. 38, no. 17, 2024, pp. 18990-18998.
Z. Yuan et al., "RRHF: Rank responses to align language models with human feedback without tears," arXiv preprint, 2023. doi: 10.48550/arXiv.2304.05302
H. Liu et al., "Chain of hindsight aligns language models with feedback," arXiv preprint, 2023. doi: 10.48550/arXiv.2302.02676
B. Lester et al., "The power of scale for parameter-efficient prompt tuning," arXiv preprint, 2021. doi: 10.48550/arXiv.2104.08691
E. Hu et al., "LoRA: Low-rank adaptation of large language models," arXiv preprint, 2021. doi: 10.48550/arXiv.2106.09685
Z. Sun et al., "Principle-driven Self-Alignment of language models from scratch with minimal human supervision," arXiv preprint, 2023. doi 10.48550/arXiv.2305.03047
E. Hubinger et al., "Sleeper agents: Training deceptive llms that persist through safety training," arXiv preprint, 2024. doi: 10.48550/arXiv.2401.05566
K. Papineni et al., "Bleu: a method for automatic evaluation of machine translation," Proc. 40th Annu. Meeting Association Comput. Linguistics., (Philadelphia, PA, USA), July 2022, pp. 311-318.
C.Y. Lin, "Rouge: A package for automatic evaluation of summaries," In Text summarization branches out, 2004, pp. 74-81.
A. Wang et al., "GLUE: A multi-task benchmark and analysis platform for natural language understanding," arXiv preprint, 2018. doi: 10.48550/arXiv.1804.07461
T. Shen et al., "Large language model alignment: A survey," arXiv preprint, 2023. doi: 10.48550/arXiv.2309.15025
N. Lourie, R. Le Bras, and Y. Choi, "Scruples: A corpus of community ethical judgments on 32,000 real-life anecdotes," In Proc. AAAI Conf. Artif. Intell., vol. 35, no. 15, 2021, pp. 13470-13479.
S. Gehman et al., "Realtoxicityprompts: Evaluating neural toxic degeneration in language models," arXiv preprint, 2020. doi: 10.48550/arXiv.2009.11462
L. Lucy and D. Bamman, "Gender and representation bias in GPT-3 generated stories," In Proc. Third Workshop Narrative Understanding, 2021, pp. 48-55.
Y. Zha et al., "AlignScore: Evaluating factual consistency with a unified alignment function," arXiv preprint, 2023. doi: 10.48550/arXiv.2305.16739
N. Lee et al., "Factuality enhanced language models for open-ended text generation," Adv. Neural Inform. Process. Syst., vol. 35, 2022, pp. 34586-34599.
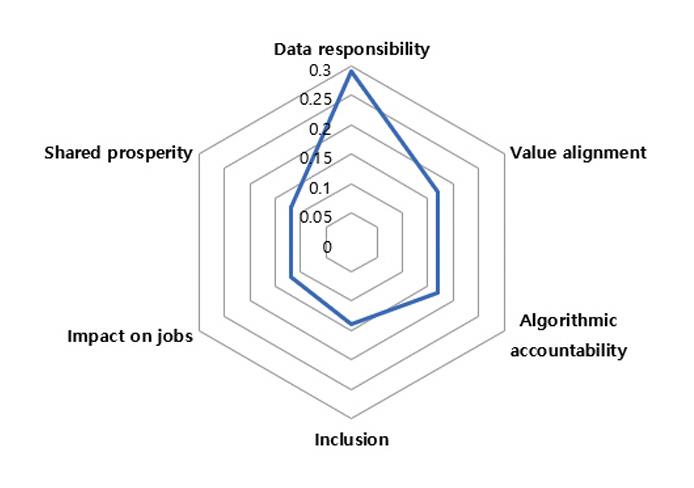
그림 2
Self-Alignment 단계별 파이프라인
출처 Reprinted from Z. Sun et al., “Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision,” arXiv preprint, 2023. doi: 10.48550/arXiv.2305.03047

그림 3
LLM 모델 평가를 위한 오픈소스 프레임워크
출처 Reprinted from AI Sarety Institute, “Inspect,” https://ukgovernmentbeis.github.io/inspect_ai/

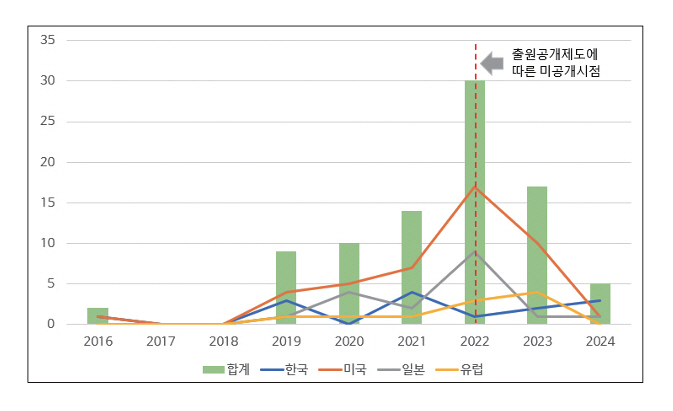
표 1 ‘ETHICS’ 데이터세트 상황별 문구 예시[9]
표 2 VisAlign: AI-인간 시각 정렬 데이터세트
| 그룹 | 카테고리 | |
|---|---|---|
| Must-Act | 1 | 변형되지 않은 이미지 |
| 2 | 거짓 상관관계 | |
| 3 | 적대적 교란 | |
| Must-Abstain | 4 | 비대상 객체 |
| 5 | 하이브리드 객체 | |
| 6 | 인접한 관계 | |
| 7 | 비사진적 표현 | |
| Uncertain | 8 | 잘리거나 손상된 이미지 |
출처 Reproduced from J. Lee et al., “VisAlign: Dataset for Measuring the Degree of Alignment between AI and Humans in Visual Perception,” arXiv preprint, 2023. doi: 10.48550/arXiv.2308.01525
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.