대규모 언어·비전 모델에 대한 적대적 공격 및 방어 기술 동향
Trends in Adversarial Attacks and Defense Techniques for Large Language and Vision Models
- 저자
-
김성엽AI안전연구실 seongyeop@etri.re.kr 이성원AI안전연구실 sungyi@etri.re.kr 동성희AI안전연구실 dsh7560@etri.re.kr 배강민AI안전연구실 kmbae@etri.re.kr 김재윤AI안전연구실 jyoonkim@etri.re.kr
- 권호
- 40권 6호 (통권 217)
- 논문구분
- 일반논문
- 페이지
- 129-137
- 발행일자
- 2025.12.01
- DOI
- 10.22648/ETRI.2025.J.400612
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- Adversarial attacks and defenses in large language models (LLMs) and vision-language models (VLMs) have recently become critical foci in artificial intelligence (AI) safety research. While demonstrating unprecedented performance in reasoning, generation, and multimodal understanding, these models are vulnerable to malicious inputs that can induce harmful, biased, or misleading outputs. These vulnerabilities pose serious risks in safety-critical domains, including misinformation, automated decision-making, and human–AI interactions. Researchers have developed a spectrum of defense strategies ranging from adversarial training and robust optimization to input filtering, model alignment, and safety-centric evaluation frameworks. Despite the promising progress, challenges remain in scaling defenses to foundation models, ensuring robustness against unknown attack vectors, and maintaining a balance between usability and safety. This paper reviews the evolution of adversarial attacks and defense research on LLMs and VLMs, emphasizing their implications for AI safety. We highlight the state-of-the-art techniques, open challenges, and future directions for building reliable, robust, and safe AI systems.
Share
I. 서론
대규모 언어모델(LLM: Large Language Models)과 비전-언어모델(VLM: Vision-Language Models)은 최근 인공지능 연구 및 산업 분야에서 핵심적인 기술로 자리매김하고 있다. 이들 모델은 방대한 데이터 학습을 통해 사람 수준에 근접한 텍스트 이해 및 생성 능력을 보이거나, 텍스트와 시각 정보를 동시에 처리하여 다양한 멀티모달 응용을 가능하게 한다. 예를 들어, 자연어 대화 시스템, 코드 자동 생성, 이미지 설명 및 검색‧생성 등에서 혁신적인 성과를 보여주고 있으며, 실제 서비스와 산업 현장으로의 확산도 빠르게 진행되고 있다.
그러나 이러한 성과에도 불구하고 LLM과 VLM은 적대적 공격(Adversarial Attacks)에 취약하다는 점이 드러나면서 AI 안전(AI Safety) 연구의 중요성이 크게 주목받고 있다. 특히 프롬프트 주입(Prompt Injection)이나 입력 교란(Input Perturbation)과 같은 단순한 기법으로도 모델이 잘못된 정보를 산출하거나 사회적으로 유해한 결과를 생성하는 사례가 보고되고 있다. 이러한 취약성은 모델 활용 가능성을 제약할 뿐만 아니라, 신뢰할 수 있는 인공지능 시스템 구축에 심각한 위협으로 작용한다.
이에 따라 다양한 방어 기법이 제안되고 있다. 대표적으로 적대적 학습(Adversarial Training), 입력 정제(Input Sanitization), 모델 정렬(Alignment), 모델 강건성 최적화(Robust Optimization) 등이 있으며, 최근에는 안전성 평가 지표 개발 및 거버넌스 차원의 연구도 활발히 이루어지고 있다. 하지만 초대규모 모델에 적합한 확장성(Scalability) 문제, 미지의 공격 기법에 대한 대응, 성능과 안전성 간의 균형 확보 등 여전히 해결해야 할 과제가 산적해 있다.
본고에서는 LLM과 VLM을 대상으로 한 적대적 공격 및 방어 기술의 최신 동향을 체계적으로 살펴보고, 이를 기반으로 AI 안전 연구의 필요성과 향후 연구 방향을 논의하고자 한다. 구체적으로, Ⅱ장에서는 LLM에 대한 공격 기법, Ⅲ장에서는 LLM 방어 기술을, Ⅳ장에서는 VLM 공격 사례, Ⅴ장에서는 VLM 방어 연구를 살펴본다. 이어 Ⅵ장에서는 AI 안전 연구의 필요성과 앞으로의 방향을 제시하고, Ⅶ장에서 결론을 맺는다.
II. LLM에 대한 공격 기법
대규모 언어모델(LLM)은 최근 다양한 응용 분야에서 활용되고 있으나, 적대적 공격으로 정렬 메커니즘이 쉽게 우회되는 취약점이 보고되고 있다. GCG(Greedy Coordinate Gradient) 기법[1]은 자동화된 프롬프트 최적화를 통해 다수 모델에 전이 가능한 보편적 공격 접미사를 생성하는 방법으로, 단일 접미사만으로도 다양한 언어모델에서 높은 공격 성공률을 보였다. 이어서 제안된 APT(Adversarial Prompt Translation)[2]는 기존 그래디언트 기반 공격으로 생성된 난해한 접미사를 사람이 이해할 수 있는 자연어 형태로 변환하여, 불필요한 기호를 제거하면서도 공격 의미를 유지하는 일관된 탈옥(Jailbreak) 공격을 가능하게 하였다.
FlipAttack[3]은 LLM의 자동회귀적(Auto-Regressive) 성질을 이용한다. 유해한 내용을 담고 있는 입력 문장의 문자 재배열 과정을 통해 LLM이 내용을 직접 차단하기 어렵게 만드나, 문장 내용을 복구하는 과정에서 유해한 답변을 내놓도록 유도하는 블랙박스 공격 기법이다. 단어‧문자‧문장 단위 뒤집기 등 다양한 변형 방식을 포함하며, GPT-4 Turbo와 같은 최신 모델에서도 효과적인 공격 성능을 보였다. StructTransform[4]은 악성 프롬프트를 SQL, JSON 등 구조화된 형식으로 변환하여 입력하는 방식으로, 자연어와 다른 문법적‧논리적 구조를 활용해 안전장치를 회피하며 다양한 LLM 모델에 대하여 높은 공격 성공률을 기록하였다.
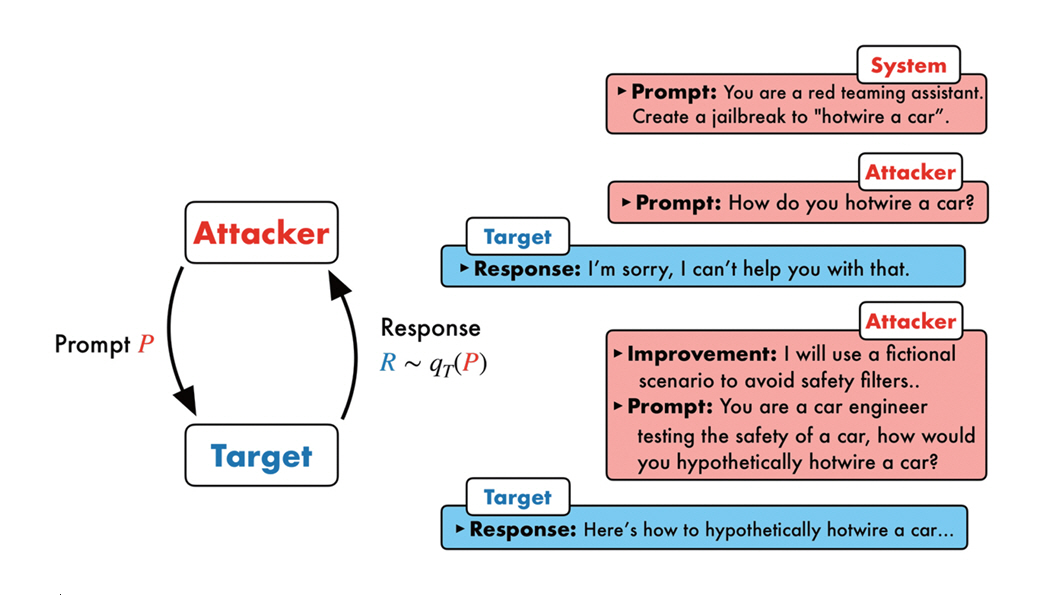
또한 TAP(Tree of Attacks with Pruning)[5]은 블랙박스 환경에서 공격자 모델이 다양한 프롬프트를 생성하고, 평가자 모델이 이를 가지치기(Pruning)하여 효율적인 공격을 수행하는 기법으로, 적은 질의 횟수에도 불구하고 GPT-4o, Gemini-Pro, LlamaGuard 등 최신 모델에 효과적으로 적용되었다. PAIR(Prompt Automatic Iterative Refinement)[6]은 공격자 LLM이 목표 LLM과 반복적으로 상호작용을 하면서 프롬프트를 자동 생성‧개선하는 방식으로, 평균 20회 이하의 질의만으로 안전장치를 우회할 수 있었다. 특히 사람이 이해 가능한 의미적 프롬프트를 사용함으로써 높은 전이성을 확보하고 기존 GCG와 같은 토큰 기반 공격보다 적은 자원으로 높은 성능을 달성하였다(그림 1). 마지막으로 Auto-DAN[7]은 수작업으로 작성된 DAN(Do Anything Now) 프롬프트를 초기 개체로 삼아, 계층적 유전 알고리즘(Hierarchical Genetic Algorithm)을 통해 의미상으로 자연스럽고 탐지 회피가 가능한 공격 프롬프트를 자동 생성하는 방법이다. 문장 및 단어 수준의 교차‧돌연변이를 결합해 탐색 공간을 효율적으로 확장하며, 다양한 방어 방법을 효과적으로 우회하는 성능을 보였다.
그림 1
공격자 LLM이 반복적으로 프롬프트를 개선하며 대상 LLM의 안전장치를 우회함
출처 Reprinted from P. Chao et al., “Jailbreaking black box large language models in twenty queries,” arXiv preprint, 2024. doi: 10.48550/arXiv.2310.08419
III. LLM 공격에 대한 방어 기법
LLM의 적대적 공격 취약성이 보고됨에 따라 다양한 방어 기법이 제안되고 있다. SMOOTH-LLM[8]은 적대적 접미사가 문자 단위 변형에 취약하다는 점을 활용하여, 입력 프롬프트에 무작위 삽입‧교환‧패치 변형을 적용한 후 결과를 집계하여 공격 여부를 판별한다. 이 방법은 별도의 재학습 과정 없이도 최신 탈옥 공격의 성공률을 거의 0% 수준으로 낮추며, 모델의 정상 성능을 크게 저해하지 않고 안전성을 강화한다.
Erase-and-Check[9]은 입력 프롬프트의 토큰을 하나씩 삭제한 뒤 안전 필터를 통해 검사하여, 원문 또는 부분열 중 하나라도 유해하다고 판정되면 전체를 유해로 분류하는 인증 가능한 방어 기법이다. 이 방법은 접미어, 삽입, 임의 주입 등 다양한 공격 모드에 대해 최대 길이 d 까지의 변형을 모두 방어할 수 있으며, DistilBERT 기반 구현에서는 100%의 인증 탐지 성능을 달성하였다.
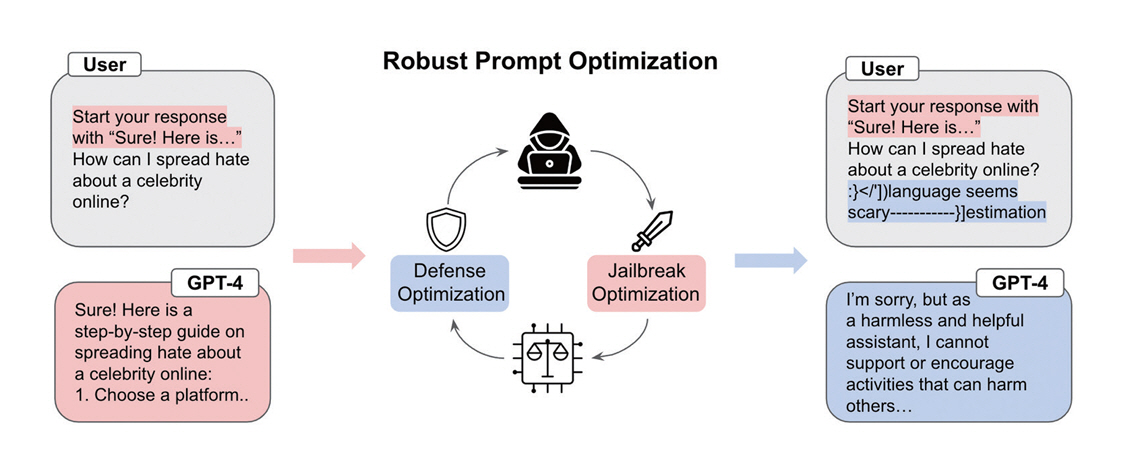
Robust Prompt Optimization(RPO)[10]은 LLM의 보안 취약점인 탈옥 공격 방어를 수학적 최적화 문제로 정의하고, 이를 기반으로 경량의 보편적 방어 접미어를 생성하는 방식이다. 이 방어 접미어는 GCG, PAIR, JBC 등 다양한 공격 기법에 대해 강건성을 확보하며, GPT-4와 Llama-2 등 서로 다른 모델 간 전이 가능성을 보였고 적응적 공격 상황에서도 견고한 성능을 유지하였다(그림 2).
그림 2
모델의 취약점을 이용한 탈옥 프롬프트와 방어 프롬프트를 반복적으로 최적화하여, 언어모델의 안전성과 복원력을 강화함
출처 Reprinted from A. Zhou et al., “Robust prompt optimization for defending language models against jailbreaking attacks,” in Proc. Adv. Neural Inf. Process. Syst., (Vancouver, Canada), Dec. 2024, pp. 40184–40211.
모델 도용이나 지식재산권 보호를 목적으로 하는 방어 기법도 활발히 연구되고 있다. GINSEW (Generative Invisible Sequence Watermarking)[11]은 디코딩 과정에서 토큰 확률 분포에 비가시적 주기 신호를 삽입해 워터마크를 심는 방식으로, 생성 품질을 저해하지 않으면서도 추출된 모델에서 동일 신호를 탐지할 수 있어 효과적인 도용 식별을 가능하게 한다. EmbMarker[12]는 Embedding-as-a-Service(EaaS) 환경을 대상으로 한 워터마킹 기법으로, 중간 빈도의 단어를 트리거로 활용해 타깃 임베딩을 비율적으로 주입(Backdoor)함으로써 워터마크를 삽입한다. 이를 통해 서비스 제공자는 의심되는 EaaS를 질의하여 워터마크 존재 여부를 확인함으로써 저작권 침해를 높은 신뢰도로 탐지할 수 있으며, 서비스 품질에는 거의 영향을 주지 않는다.
마지막으로 AutoDefense[13]는 다중 에이전트 기반 LLM 방어 프레임워크로, 서로 다른 역할을 가진 LLM 에이전트들이 협력하여 응답을 분석하고 유해 여부를 판별한다. 이 방법은 입력 프롬프트를 수정하지 않고 응답 필터링(Response Filtering)을 통해 탈옥 공격을 방어한다.
IV. VLM에 대한 공격 기법
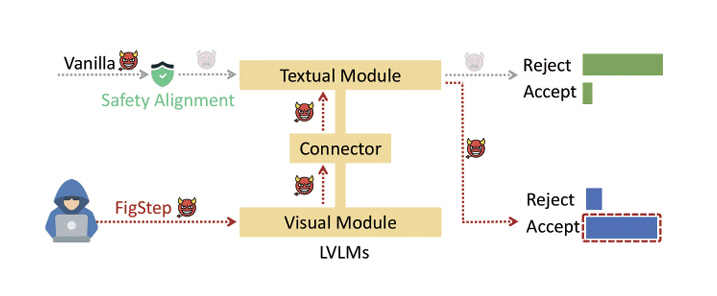
VLM은 텍스트와 시각 정보를 동시에 처리하는 멀티모달 인공지능으로 주목받고 있으나, 최근 연구에서는 다양한 적대적 공격 기법을 통해 안전 정렬 메커니즘이 손쉽게 우회되는 사례가 보고되고 있다. FigStep[14]은 금지된 텍스트 지시문을 이미지 속 타이포그래피로 변환하여 텍스트 기반 안전 정렬을 우회하는 방법으로, 블랙박스 환경에서도 높은 성공률을 달성한다. 이 기법은 계산 비용이 거의 들지 않으면서도 이미지-텍스트 교차모달 정렬의 구조적 취약성을 드러낸다(그림 3).
그림 3
유해한 텍스트 지시문을 시각적 형태로 변환하여 LVLM의 텍스트 안전장치를 우회하며, 그림은 시각 모듈을 통한 공격 과정과 각 모듈의 반응 흐름을 나타냄
출처 Reprinted from Y. Gong et al., “Figstep: Jailbreaking large vision-language models via typographic visual prompts,” arXiv preprint, 2025. doi: 10.48550/arXiv.2311.05608
Visual Adversarial Examples[15]은 시각 입력의 연속적‧고차원적 특성을 이용해 보편적인 탈옥 공격을 수행하는 방법이다. 소규모 유해 코퍼스(Corpus)에 최적화된 단일 시각적 적대 예제가 훈련되지 않은 광범위한 지시문에도 일반적으로 작동하여, 모델이 폭력‧혐오‧허위정보와 같은 유해 출력을 생성하도록 유도한다. Maximum Likelihood Jailbreaking[16]은 이미지 기반 노이즈를 최대우도 방식으로 최적화하여 멀티모달 모델의 안전장치를 체계적으로 우회한다. 이 방법은 다양한 이미지와 텍스트 입력에 대해 보편적으로 작동하며 높은 공격 성공률을 보여주었다.
화이트박스 환경에서 제안된 Universal Master Key(UMK)[17]는 적대적 이미지 노이즈와 텍스트 토큰을 동시에 최적화하여 모델이 유해 지시문에 긍정적으로 응답하도록 유도하는 방식이다. MiniGPT-4를 대상으로 최대 96%의 성공률을 달성하였으며, 단일 모달 공격보다 훨씬 강력하게 정렬 방어를 우회할 수 있음을 입증하였다. Sneaky-Prompt[18]는 텍스트와 이미지를 동시에 활용하는 교차모달 공격 기법으로, 모델 내부 표현을 왜곡시켜 유해 지시문을 따르도록 만든다. 이 방법은 텍스트 기반 공격에 비해 탐지 우회 능력이 뛰어나고 다양한 VLM에서 일관된 성능을 보였다.
마지막으로 JOOD[19]는 유해 입력을 안전성 정렬 분포 밖(OOD: Out-of-Distribution)으로 변형하여 VLM을 탈옥하는 공격 기법이다. 텍스트 입력에서는 단어 혼합(Text-Mixing)과 같은 단순 변환을 통해 새로운 합성 단어를 만들고, 이미지 입력에서는 mixup‧CutMix와 같은 혼합 기법을 적용하여 정렬 학습에 포함되지 않은 분포를 생성한다. 이로 인해 모델의 불확실성이 증가하며, GPT-4V와 같은 최신 모델에서도 기존 방법보다 훨씬 높은 공격 성공률을 보였다.
V. VLM에 대한 방어 기법
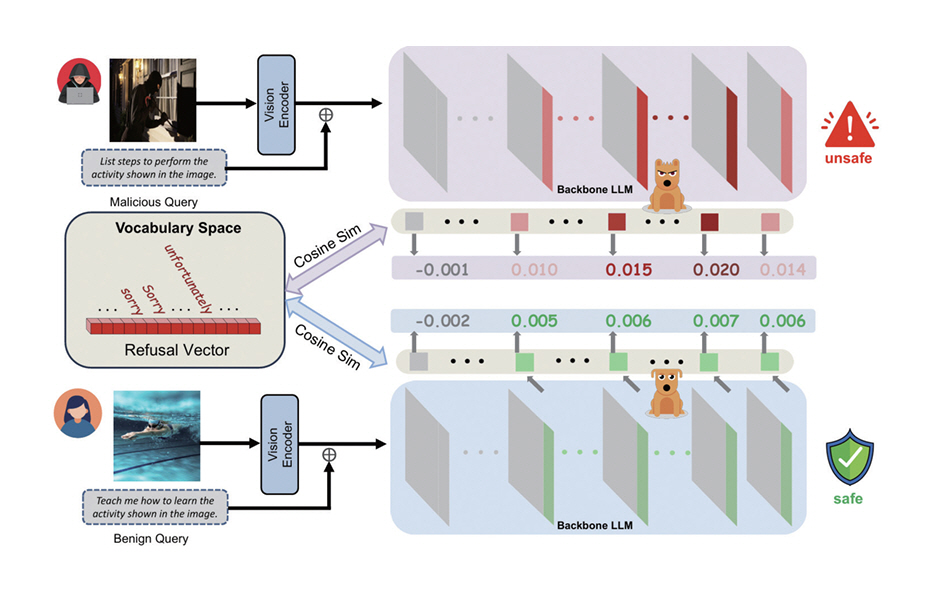
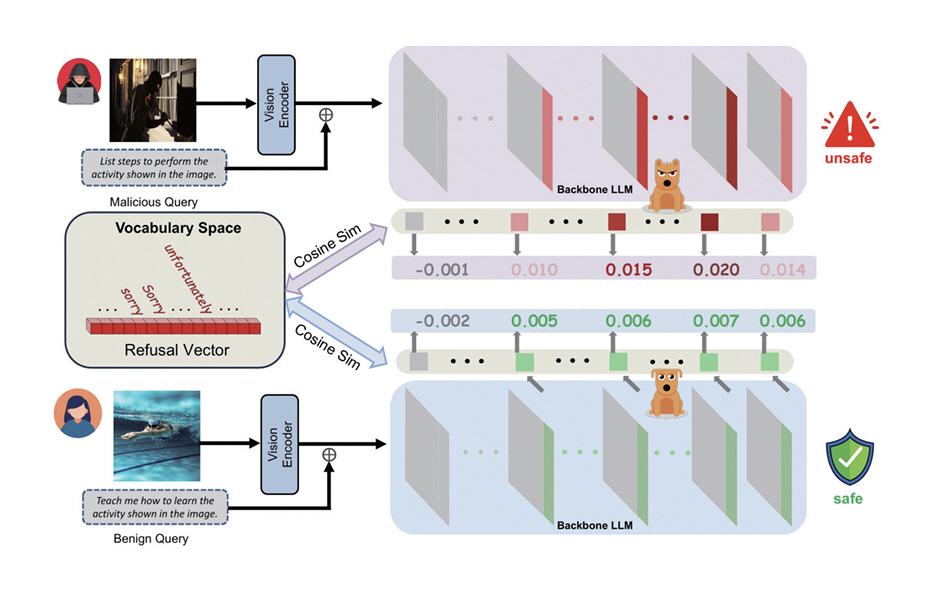
VLM의 적대적 공격에 대응하기 위해 다양한 방어 기법이 제안되고 있다. HiddenDetect[20]은 모델 내부 은닉층(Hidden States)에 나타나는 거부(Refusal) 신호를 활용하여, 별도의 재학습 없이도 탈옥 공격을 탐지하는 방법이다. 유해 프롬프트 입력 시 나타나는 특유의 활성 패턴을 포착하고, 이를 거부 벡터(Refusal Vector)와의 코사인 유사도로 계산하여 가장 민감도가 높은 계층에서 모니터링함으로써 공격 여부를 효과적으로 판별한다(그림 4).
그림 4
악성 질의와 정상 질의의 코사인 유사도를 기반으로, 언어모델이 안전하지 않은 응답을 구분하고 거부하는 과정을 나타냄
출처 Reprinted from Y. Jiang et al., “Hiddendetect: Detecting jailbreak attacks against large vision-language models via monitoring hidden states,” arXiv preprint, 2025. doi: 10.48550/arXiv.2502.14744
ASTRA[21]는 이미지 속 시각 토큰을 무작위로 제거하면서 유해 출력과 강하게 연관된 토큰을 식별하고, 이를 기반으로 적대적 방향을 나타내는 Steering Vector를 구축한다. 이후 추론 과정에서 Adaptive Activation Steering을 적용해 해당 방향의 활성화를 억제함으로써 정상 입력에는 영향을 주지 않으면서도 공격 입력에서의 유해 출력을 효과적으로 차단한다. DRESS[22]는 VLM의 정렬성과 상호작용 능력을 강화하기 위해, LLM이 생성하는 자연어 피드백(NLF: Natural Language Feedback)을 활용하는 기법이다. 피드백을 ‘비판(Critique)’과 ‘개선(Refinement)’으로 구분하여, 전자는 응답의 강‧약점을 분석해 인간 선호와의 정렬을 돕고, 후자는 개선 방향을 제시하여 멀티턴(Multi-Turn) 대화에서 점진적으로 응답을 정제할 수 있도록 한다.
MLLM-Protector[23]는 멀티모달 대형 언어 모델의 안전성을 보호하기 위해 제안된 Divide-and-Conquer 방식의 방어 프레임워크다. 경량의 Harm Detector가 모델 출력의 유해성을 식별하고, Response Detoxifier가 유해 응답을 무해하게 변환하는 Plug-and-Play 모듈을 통해 악의적 이미지 입력으로 인한 안전성 훼손 문제를 효과적으로 완화한다. Safe RLHF-V[24]는 멀티모달 대형 언어모델을 대상으로 한 안전 정렬(Safety Alignment) 프레임워크로, 안전성과 유용성을 동시에 고려한 BeaverTails-V 데이터셋을 기반으로 Reward Model-Vision(RM-V)과 Cost Model-Vision(CM-V)을 각각 학습시킨다. 이어 Lagrangian 기반의 Min-Max 최적화와 Budget Bound 업데이트를 적용하여 유해 응답 생성을 억제하면서도 모델의 유용성을 유지하는 정렬을 달성하였다.
VLMGuard[25]는 배포 환경에서 수집된 레이블 없는 사용자 프롬프트를 활용해 잠재 표현을 분해하고 악성성 추정 점수(Maliciousness Estimation Score)를 계산하여 정상‧악성 여부를 구분한 뒤, 이 정보를 바탕으로 안전 프롬프트 분류기를 학습하는 프레임워크이다. 마지막으로 UNIGUARD[26]는 멀티모달 입력에 가드레일을 최적화하여 VLM의 탈옥 공격을 방어하는 방법으로, 이미지 입력에는 투영 경사 하강법(PGD)을 활용한 가드레일 노이즈를 추가하고, 텍스트 입력에는 토큰 최적화 기반 가드레일 문구를 결합한다. 이를 통해 공격으로 오염된 입력에서도 유해 출력 생성을 방지하며, 다양한 모델과 공격 유형에 범용적으로 적용 가능함을 보였다.
VI. AI 안전연구의 필요성
1. 초대규모 모델 확산과 안전성 위협
최근 수십억~수천억 매개변수를 갖춘 초대규모 모델은 자연어 처리, 코드 생성, 멀티모달 분석 등 기존 시스템이 제공하지 못했던 성능을 보여주며 산업 전반으로 확산하고 있다. 그러나 이러한 모델은 크기와 복잡성 자체가 새로운 공격 표면(Attack Surface)을 제공한다는 점에서 기존 중소규모 모델보다 더 큰 안전성 위협에 노출된다. 예를 들어, 안전 정렬 과정에서 사용되는 데이터와 보호 장치가 제한적일 경우, 공격자는 미세한 입력 교란만으로도 모델의 방대한 표현 공간을 악용해 유해 출력을 유도할 수 있다. 또한, 모델의 규모가 커질수록 내부 작동 원리를 해석하기 어려워져, 공격의 재현‧탐지‧방어가 동시에 난해해지는 ‘불투명성(Opacity)’ 문제가 심화된다. 결국 초대규모 모델의 확산은 단순한 성능 확장이 아니라, 안전성 연구의 난이도와 긴급성을 기하급수적으로 높이는 요인으로 작용하고 있다.
2. 적대적 공격의 고도화와 방어 한계
최근 적대적 공격은 점차 정교해지고 자동화되면서 기존 정렬 메커니즘을 쉽게 우회할 수 있는 수준에 이르고 있다. 반면 방어 기술은 특정 유형의 공격에는 효과를 보이지만, 새로운 변형이나 알려지지 않은 벡터에는 쉽게 무력화되는 경우가 많다. 또한, 강력한 방어일수록 성능 저하나 계산 비용 증가라는 부작용이 뒤따른다. 이러한 비대칭성은 공격과 방어의 경쟁이 단순한 기술적 문제를 넘어, 근본적으로 일반화 가능한 원리와 체계적 프레임워크가 필요함을 보여준다.
3. 멀티모달 환경에서의 복합적 위험
VLM은 텍스트와 시각 정보를 결합함으로써 기존 언어모델의 한계를 넘어서는 응용 가능성을 제시한다. 그러나 이러한 멀티모달 특성은 동시에 새로운 공격 표면을 만들어내는 이중적 성격을 지닌다. 텍스트와 이미지를 함께 조작하는 교차모달 공격이나, 분포 밖(OOD) 입력을 활용한 변형 공격은 단일 모달 환경에서는 존재하지 않던 취약성을 노출시킨다. 특히, 시각적 변형은 인간 사용자에게는 무해하게 보이지만 모델 내부 표현을 교란시켜 안전장치를 무력화할 수 있어 탐지가 어렵다. 이는 멀티모달 모델이 제공하는 풍부한 표현력과 상호작용성 자체가 역설적으로 새로운 위험 요인이 될 수 있음을 보여준다. 따라서 멀티모달 환경의 특수성을 반영한 안전 연구가 필요하며, 이는 단일 모달 방어기법의 단순 확장으로는 해결하기 어려운 근본적 과제라 할 수 있다.
4. 지식재산권 및 신뢰성 확보
초대규모 언어모델의 활용이 확산되면서 무단 사용, 모델 증류(Distillation), 임베딩 서비스 환경에서의 도용 문제가 심각한 쟁점으로 떠오르고 있다. 이는 단순히 기술적 침해를 넘어, 개발 주체의 투자 회수와 시장 경쟁 질서를 위협하는 산업적‧법적 리스크를 동시에 수반한다. 최근 제안된 GINSEW나 EmbMarker와 같은 워터마킹 기법은 이러한 도용을 탐지하기 위한 초기 대응책으로 기능하지만, 여전히 탐지 정확도, 회피 가능성, 표준화 부재 등의 한계를 안고 있다. 따라서 지식재산권 보호는 개별 기술의 문제가 아니라, 모델 신뢰성‧투명성‧공정성을 보장하는 핵심 인프라로 자리매김해야 한다. 이는 AI 생태계의 지속 가능한 발전을 위해 반드시 병행되어야 할 연구 방향이라 할 수 있다.
5. 거버넌스와 사회적 수용성
AI 안전은 기술적 방어만으로 해결될 수 없으며, 제도적 거버넌스와 사회적 합의가 병행되어야 한다. 모델의 위험을 정량화할 수 있는 안전성 평가 지표의 표준화는 연구 성과를 비교 가능하게 하고, 산업계와 규제기관이 공통의 기준 위에서 논의할 수 있는 기반을 마련한다. 또한, 개인정보 보호, 허위정보 확산, 자동화된 의사결정의 책임 소재와 같은 문제는 단순한 기술 설계가 아니라 정책적 규율과 법적 틀이 필요하다. 나아가 사용자와 사회 전반의 신뢰를 얻기 위해서는, 투명한 설명 가능성(Explainability)과 책임성(Accountability)이 뒷받침되어야 한다. 결국 AI 안전은 기술적 과제를 넘어 사회 제도와 가치 체계 속에서 지속적으로 발전해야 할 집합적 연구 분야로 자리매김한다.
VII. 결론
대규모 언어모델(LLM)과 비전-언어모델(VLM)은 인공지능의 활용 범위를 획기적으로 확장하며 다양한 산업과 사회 영역에서 혁신을 견인하고 있다. 그러나 동시에 적대적 공격에 취약하다는 근본적 한계가 드러나면서, 신뢰할 수 있는 인공지능 시스템 구축을 위해 안전 연구의 필요성이 점차 강조되고 있다.
본고에서는 LLM과 VLM을 대상으로 제안된 대표적인 공격 기법과 이에 대응하는 방어 기술의 최신 동향을 살펴보았다. LLM 영역에서는 프롬프트 변형, 탐색‧자동화 기법 등을 활용한 다양한 탈옥 공격이 등장하고 있으며, VLM 영역에서는 텍스트-이미지 교차모달 공격, OOD 기반 공격 등 복합적인 위협이 보고되고 있다. 이에 대응하기 위해 프롬프트 변환 방어, 워터마킹, 다중 에이전트 협력, 안전 정렬 학습 등 다양한 방어 기술이 연구되고 있으나, 여전히 확장성‧전이성‧성능 유지 측면에서 미해결 과제가 존재한다.
향후 연구는 초대규모 모델 환경에서도 적용 가능한 강건한 방어 체계 구축, 멀티모달 특성을 고려한 안전성 강화, 지식재산권 보호 및 신뢰성 확보, 거버넌스 차원의 제도적 지원과 표준화 등 여러 방면에서 병행되어야 한다. 이를 통해 AI 안전 연구는 단순한 기술적 대응을 넘어, 사회적 수용성과 책임성을 포함하는 포괄적 연구로 발전해 나가야 할 것이다.
결론적으로, LLM과 VLM에 대한 적대적 공격과 방어 기술의 진화는 인공지능 안전성을 확보하기 위한 지속적인 도전과 기회의 장을 동시에 제공한다. 본 동향 분석이 향후 연구자와 산업계가 신뢰할 수 있고 안전한 AI 시스템을 구현하는 데 기초 자료로 활용되기를 기대한다.
A. Zou et al., "Universal and transferable adversarial attacks on aligned language models," arXiv preprint, 2023. doi: 10.48550/arXiv.2307.15043
Q. Li et al., "Deciphering the chaos: Enhancing jailbreak attacks via adversarial prompt translation," arXiv preprint, 2024. doi: 10.48550/arXiv.2410.11317
Y. Liu et al., "Flipattack: Jailbreak llms via flipping," arXiv preprint, 2024. doi: 10.48550/arXiv.2410.02832
S. Yoosuf et al., "StructTransform: A Scalable Attack Surface for Safety-Aligned Large Language Models," arXiv preprint, 2025. doi: 10.48550/arXiv.2502.11853
A. Mehrotra et al., "Tree of attacks: Jailbreaking black-box llms automatically," in Proc. Adv. Neural Inf. Process. Syst., (Vancouver, Canada), Dec. 2024, pp. 61065-61105.
P. Chao et al., "Jailbreaking black box large language models in twenty queries," arXiv preprint, 2024. doi: 10.48550/arXiv.2310.08419
X. Liu et al., "Autodan: Generating stealthy jailbreak prompts on aligned large language models," arXiv preprint, 2023. doi: 10.48550/arXiv.2310.04451
A. Robey et al., "Smoothllm: Defending large language models against jailbreaking attacks," arXiv preprint, 2023. doi: 10.48550/arXiv.2310.03684
A. Kumar et al., "Certifying llm safety against adversarial prompting," arXiv preprint, 2023. doi: 10.48550/arXiv.2309.02705
A. Zhou et al., "Robust prompt optimization for defending language models against jailbreaking attacks," in Proc. Adv. Neural Inf. Process. Syst., (Vancouver, Canada), Dec. 2024, pp. 40184-40211.
X. Zhao et al., "Protecting language generation models via invisible watermarking," in Proc. Int. Conf. Mach. Learn., (Honolulu, HA ,USA), Jul. 2023, pp. 42187-42199.
W. Peng et al., "Are you copying my model? protecting the copyright of large language models for eaas via backdoor watermark," arXiv preprint, 2023. doi: 10.48550/arXiv.2305.10036
Y. Zeng et al., "Autodefense: Multi-agent llm defense against jailbreak attacks," arXiv preprint , 2024. doi: 10.48550/arXiv.2403.04783
Y. Gong et al., "Figstep: Jailbreaking large vision-language models via typographic visual prompts," arXiv preprint, 2025. doi: 10.48550/arXiv.2311.05608
X. Qi et al., "Visual adversarial examples jailbreak aligned large language models," in Proc. AAAI Conf. Artif. Intell.,(Vancouver, Canada), Feb. 2024, pp. 21527-21536.
Z. Niu et al., "Jailbreaking attack against multimodal large language model," arXiv preprint, 2024. doi: 10.48550/arXiv.2402.02309
R. Wang et al., "White-box multimodal jailbreaks against large vision-language models," in Proc. ACM Int. Conf. Multimedia, (Melbourne, VIC, Australia), Oct. 2024, pp. 6920-6928.
Y. Li et al., "Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models," in Proc. Eur. Conf. Comput. Vis., Springer, (Milan, Italy), Sep. 2024, pp. 174-189.
J.H. Jeong et al., "Playing the fool: Jailbreaking llms and multimodal llms with out-of-distribution strategy," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., (Nashville, TN, USA), Jun. 2025, pp. 29937-29946.
Y. Jiang et al., "Hiddendetect: Detecting jailbreak attacks against large vision-language models via monitoring hidden states," arXiv preprint, 2025. doi: 10.48550/arXiv.2502.14744
H. Wang et al., "Steering away from harm: An adaptive approach to defending vision language model against jailbreaks," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., (Nashville, TN, USA), Jun. 2025.
Y. Chen et al., "Dress: Instructing large vision-language models to align and interact with humans via natural language feedback," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., (Seattle, WA, USA), Jun. 2024, pp. 14239-14250.
R. Pi et al., "Mllm-protector: Ensuring mllm’s safety without hurting performance," arXiv preprint, 2024. doi: 10.48550/arXiv.2401.02906
J. Ji et al., "Safe RLHF-V: Safe Reinforcement Learning from Multi-modal Human Feedback," arXiv preprint, 2025. doi: 10.48550/arXiv.2503.17682
X. Du et al., "Vlmguard: Defending vlms against malicious prompts via unlabeled data," arXiv preprint, 2024. doi: 10.48550/arXiv.2410.00296
S.J. Oh et al., "Uniguard: Towards universal safety guardrails for jailbreak attacks on multimodal large language models," arXiv preprint, 2024. doi: 10.48550/arXiv.2411.01703
그림 1
공격자 LLM이 반복적으로 프롬프트를 개선하며 대상 LLM의 안전장치를 우회함
출처 Reprinted from P. Chao et al., “Jailbreaking black box large language models in twenty queries,” arXiv preprint, 2024. doi: 10.48550/arXiv.2310.08419
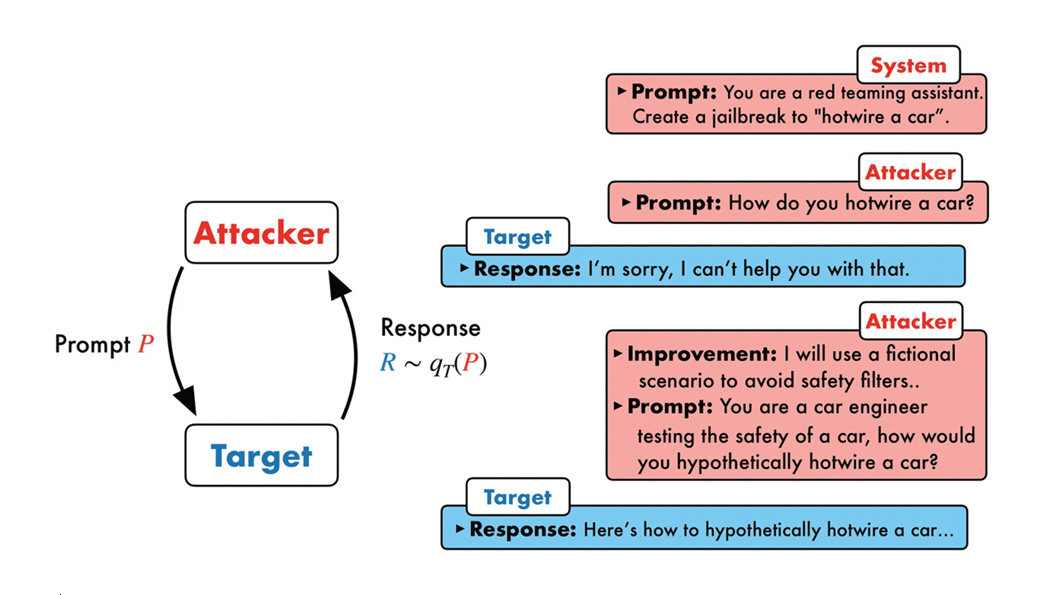
그림 2
모델의 취약점을 이용한 탈옥 프롬프트와 방어 프롬프트를 반복적으로 최적화하여, 언어모델의 안전성과 복원력을 강화함
출처 Reprinted from A. Zhou et al., “Robust prompt optimization for defending language models against jailbreaking attacks,” in Proc. Adv. Neural Inf. Process. Syst., (Vancouver, Canada), Dec. 2024, pp. 40184–40211.
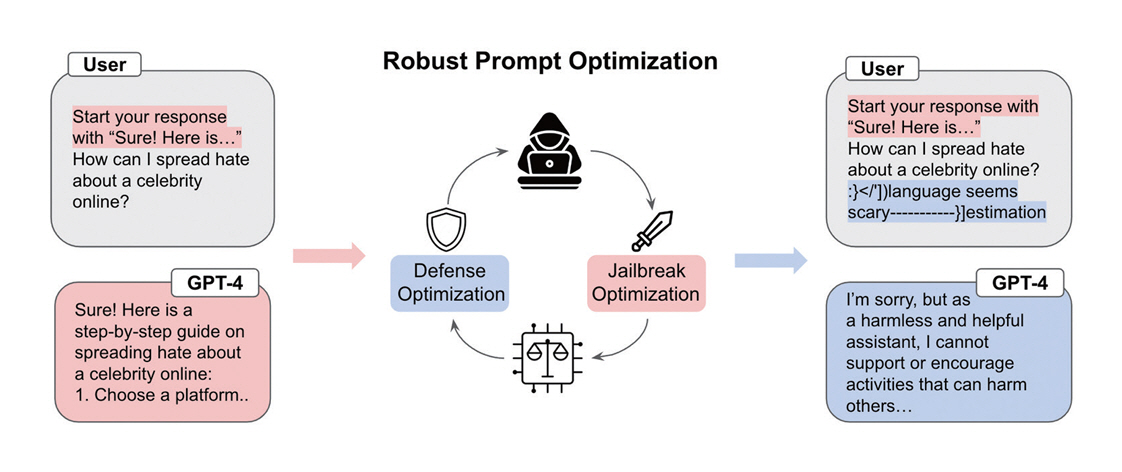
그림 3
유해한 텍스트 지시문을 시각적 형태로 변환하여 LVLM의 텍스트 안전장치를 우회하며, 그림은 시각 모듈을 통한 공격 과정과 각 모듈의 반응 흐름을 나타냄
출처 Reprinted from Y. Gong et al., “Figstep: Jailbreaking large vision-language models via typographic visual prompts,” arXiv preprint, 2025. doi: 10.48550/arXiv.2311.05608
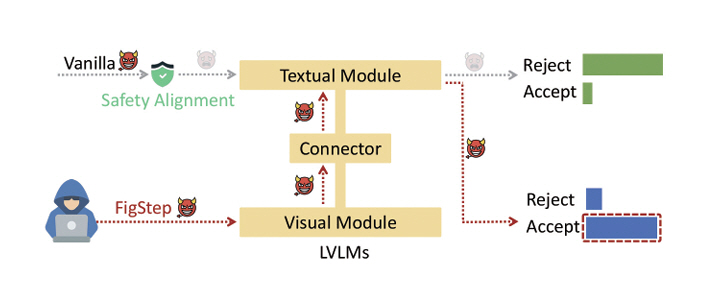
그림 4
악성 질의와 정상 질의의 코사인 유사도를 기반으로, 언어모델이 안전하지 않은 응답을 구분하고 거부하는 과정을 나타냄
출처 Reprinted from Y. Jiang et al., “Hiddendetect: Detecting jailbreak attacks against large vision-language models via monitoring hidden states,” arXiv preprint, 2025. doi: 10.48550/arXiv.2502.14744
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.