시계열 파운데이션 인공지능 모델 기술 동향
Technical Trends in Time-Series Foundation Models
- 저자
-
이상준에너지지능화연구실 sjlee85@etri.re.kr 황유민에너지지능화연구실 yumin@etri.re.kr 고석갑에너지지능화연구실 softgear@etri.re.kr
- 권호
- 41권 2호 (통권 219)
- 논문구분
- 일반논문
- 페이지
- 63-72
- 발행일자
- 2026.04.01
- DOI
- 10.22648/ETRI.2026.J.410207
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- Time-series forecasting, which aims to predict future values from historical observations, is fundamental to applications in domains such as weather, energy, and finance. Recent advances in deep learning have shifted research focus from traditional statistical approaches toward neural forecasting models, particularly transformer-based architectures. However, deploying high-performance neural forecasters in real-world settings often requires large, domain-specific datasets, which are difficult to obtain in security- and privacy-sensitive sectors such as energy. Inspired by large-language models that generalize across tasks without domain-specific fine-tuning, recent work has introduced time-series foundation models (TSFMs) trained on large and diverse collections of public time series data to enable zero-shot forecasting across domains. This study surveys the technical evolution of time-series forecasting, from classical statistical models to contemporary AI-based approaches. We review representative TSFMs developed in industry, comparing their architectures, training data scale, feature support, and degree of openness. Our analysis reveals common architectural patterns, data scaling trends, and open challenges in deploying TSFMs, particularly in data-constrained and security-sensitive domains. In addition, we discuss emerging large-scale datasets and benchmarking efforts,and outline practical considerations for adopting TSFMs in real-world forecasting applications.
Share
I. 서론
미래를 예측하고자 하는 인류의 노력은 과학의 발달과 함께 끊임없이 지속되었다. 특히 수치화된 과거의 데이터를 바탕으로 미래의 수치를 예측하고자 하는 시계열 예측은 일기예보, 에너지, 금융 등 수많은 분야에서 중요하게 다뤄졌다. 기존에는 일기예보처럼 복잡한 미분방정식을 기반으로 한 과학적 모델링이나 통계를 이용한 분석을 기반으로 예측이 이루어졌으나, 최근 인공지능 기술의 발달과 함께 이를 활용한 시계열 예측 방식이 주목받고 있다.
시계열 데이터 예측은 더욱 세부적으로 단일 시계열 데이터 예측, 예측 대상 간의 상관관계가 있을 수 있는 다변량 시계열 데이터 예측, 제어 가능한 외부 변량을 고려한 공변량 시계열 데이터 예측 등으로 나뉜다. 기존에는 이러한 예측을 수행하기 위해 해당 도메인의 데이터를 대량으로 확보하여야 했는데, 최근 발전하고 있는 거대 언어 모델(LLM: Large Language Model)이 도메인 특화 데이터 없이도 일정 수준의 성능을 보이는 점에서 영감을 얻어 시계열 예측에 특화된 거대 인공지능에 관한 연구가 진행되었고, 이로 인해 탄생한 시계열 파운데이션 모델(TSFM: Time-Series Foundation Model)이 별도의 학습이나 파인튜닝 과정 없이도 우수한 예측 성능을 보이고 있다[1].
이에 실리콘밸리의 스타트업 기업부터 Google, Amazon 등 세계적인 대기업까지 다양한 곳에서 시계열 파운데이션 모델에 관한 연구를 진행하고 있다. 본고에서는 이와 같은 시계열 파운데이션 모델에 관한 최근 기술 동향을 소개한다.
본고의 구성은 다음과 같다. Ⅱ장에서 기존의 시계열 예측 기술과 인공지능 기반 시계열 예측 기술을 거쳐 트랜스포머 기반 모델에 이르기까지의 연구 동향에 대해 소개한다. Ⅲ장에서는 시계열 파운데이션 모델 연구 동향에 대해서 소개하고, Ⅳ장에서는 시계열 파운데이션 모델 관련 데이터셋 및 벤치마크 기술 동향을 살펴본다. 마지막으로 Ⅴ장에서 결론을 제시한다.
II. 시계열 파운데이션 모델 기술 개요
1. 기존 시계열 예측 기술
인공지능 기술이 적용되기 이전의 시계열 예측은 주로 통계분석 측면에서 이루어졌다. 이때, 미래의 수치 예측을 확률 고려 없이 하나의 고정된 값으로만 예측하는 방식과 일정한 확률 분포로 예측하는 방식을 생각할 수 있다.
고정값 예측에는 과거 데이터를 바탕으로 계산된 평균을 그대로 적용하는 평균 기법, 가장 최근의 데이터값을 그대로 사용하는 단순(Naive) 기법, 데이터의 계절성(Seasonality)을 알고 있을 때 이를 활용하는 계절성 단순 기법, 데이터의 장기적인 추세를 선형으로 분석하여 해당 추세를 따라가는 선형 회귀분석 기법 등이 있다.
확률적 예측에는 과거 데이터의 평균에 더해 분산까지 고려하여 정규 분포와 같은 확률 모델을 예측하는 단순 통계 기반 예측과 비정상적(Nonstationary) 시계열 자료 분석에 널리 쓰이는 ARIMA 모형 기법 등이 있다.
2. 인공지능 기반 시계열 예측 기술
시계열 예측과 같이 과거의 데이터를 기반으로 미래의 데이터를 예측하는 인공지능 기술은 RNN(Recurrent Neural Network)으로부터 시작되었다. 당시 큰 주목을 받던 인공신경망 구조를 순환적으로 변경하여, 시계열 데이터나 자연어와 같은 순차적인 데이터를 처리하는 데 강점을 보인다. 초기 RNN은 오래된 과거 데이터의 영향력이 사라지는 문제가 있어서, 이를 개선하기 위해 LSTM(Long Short Term Memory) 구조는 과거 정보를 장기간 보존할 수 있도록 개발되었다. 이후 과거 데이터 간 상호 의존 문제를 근본적으로 해결하는 어텐션 메커니즘이 제안된 트랜스포머(Transformer) 구조가 큰 주목을 받았으며, BERT나 GPT와 같은 많은 언어 모델들이 트랜스포머 구조를 채택하고 있다. 특히 트랜스포머가 자연어 처리(NLP: Natural Language Processing) 분야에서 혁신을 가져온 부분이 시계열 예측에서도 통용될 수 있다는 관측하에 많은 연구가 진행되었는데, 시계열 데이터에 대한 패칭(Patching) 기법이 가미될 경우에너지, 교통, 기후 등의 도메인에서 기존 방식보다 우수한 예측 정확도를 보인다고 알려져 있다[2].
3. 파운데이션 모델 기반 시계열 예측 기술
실제 산업에서 이러한 인공지능 모델을 학습하기 위해서는 충분한 데이터가 필요하다는 문제가 있다. 특히 에너지 분야와 같이 데이터 보안이 중요한 분야에서 이런 문제가 두드러지는데, 이를 해결하기 위해 GPT와 같은 거대 언어 모델을 학습하는 방법과 유사하게 도메인을 가리지 않고 최대한 많은 양의 공개된 시계열 데이터를 학습한 거대 예측 모델을 만들어 타겟 도메인에 대한 별도의 학습 없이도 충분한 제로샷(Zero-shot) 예측 정확도를 달성하는 방법이 제안되었다[3]. 표 1의 시계열 파운데이션 모델별 비교에서 볼 수 있듯이 대부분의 경우 트랜스포머 기반 모델을 사용하지만, LSTM 구조를 확장한 모델을 사용하는 연구 또한 진행되고 있다[4].
표 1 시계열 파운데이션 모델 비교
이와 같이 시계열 파운데이션 모델은 거대 모델로 분류될 수 있지만, 언어나 멀티모달 처리에 비해 훨씬 단순한 시계열 예측에 특화되었다는 특성상 경량 모델로서의 장점을 유지할 수 있다. 최신 GPT나 Gemini 모델이 수조에서 수십조에 달하는 파라미터 숫자를 가지고 대형 데이터 센터에서 구동해야 하는 모델인 반면, 비슷한 원리로 학습된 대부분의 시계열 파운데이션 모델은 1억 미만의 파라미터 숫자를 가지고 가정용 컴퓨터나 엣지 단말과 같은 소형 기기에서도 구동이 가능하다.
트랜스포머 기반 언어 인공지능이 인코더와 디코더를 모두 사용하는 모델, 인코더만 사용하는 모델, 디코더만 사용하는 모델로 나뉘듯이, 시계열 파운데이션 모델 또한 같은 기준으로 분류될 수 있는데, 그중에서도 특히 디코더의 사용 유무 여부가 중요하다.
시계열 데이터를 예측하는 과정에서 디코더를 사용하지 않는 인코더 단독(Encoder-Only) 모델은 예측하고자 하는 미래 시계열을 하나의 확률 분포로 가정하고 해당 분포의 매개변수를 예측하여 반환한다. 반면 디코더를 사용하는 Decoder-Only 혹은 Encoder-Decoder 모델은 디코더의 생성 기능을 활용하여 임의의 미래 시계열 데이터를 다수 생성한 후 이를 모두 반환하거나 이들에 대한 통계적 분석을 반환한다.
인코더 단독 모델은 인공지능이 예측하고자 하는 결과물이 상대적으로 단순하여 계산 속도가 빠르지만 모델 설계 단계에서 상정하지 않은 확률 모델을 예측하는 데에 약점을 보이고, 디코더 모델은 다양한 확률 모델에 대응할 수 있으나 생성형 인공지능의 특성상 계산 속도가 느리다는 약점이 있다.
III. 시계열 파운데이션 모델 기술 연구 동향
1. TimeGPT
미국의 Nixtla에서는 트랜스포머 원논문의 모델 구조를 그대로 차용하고(그림 1) 1,000억 개 이상의 시계열 데이터 포인트를 사용하여 학습한 TimeGPT 모델을 발표하였다[3]. TimeGPT는 상용화를 염두에 두고 개발된 파운데이션 모델로, 기존의 시계열 예측 모델에 비해 뛰어난 제로샷 예측 정확도를 보이는 파운데이션 모델로 주목받았다.
그림 1
TimeGPT-1 개요도
출처 Reprinted with permission from A. Garza et al., “TimeGPT-1,” arXiv preprint, 2023. doi: 10.48550/arXiv.2310.03589
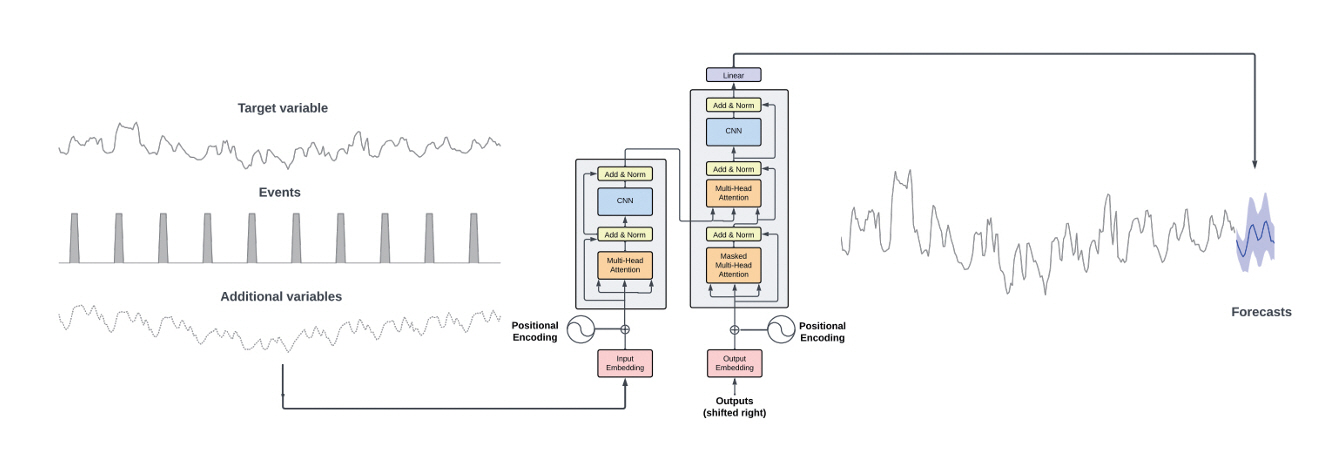
특히 초기 파운데이션 모델임에도 불구하고 공변량 시계열 데이터 예측과 같은 기능을 지원하는 것이 특징으로, 트랜스포머의 인코더 구조를 활용하여 예측하고자 하는 타겟 변수 외에 이벤트 플래그나 외부 변수와 같이 추가로 참조하고자 하는 시계열 값들을 입력으로 받아 타겟 변수의 미래 예측값을 디코더로 생성하고 통계를 내는 모델이다.
TimeGPT는 현재 1.0, 2.0 버전을 거쳐 현재 2.1 버전이 발표되었다. 다만, 상용모델이라 접근성이 낮다는 단점이 있다.
2. TimesFM
Google에서는 시계열 데이터에 대한 패칭 기법을 사용해 디코더 단독 구조로 학습한(그림 2) Times-FM 모델을 공개하였다[5]. 입력된 과거의 타겟 시계열 변수를 패치 단위로 토큰화한 후, 과거의 데이터들을 토대로 미래의 데이터를 도출하는 Causal Self-attention 구조를 활용하여 다음 단계의 시계열 변수 토큰을 계산한다. 이렇게 계산된 토큰이 디코더를 통해 미래 시계열 예측값을 생성한다. 학습에 사용된 3,000억 개 이상의 시계열 데이터 포인트 중 구글이 보유하고 있는 인터넷 트렌드 데이터 및 웹 페이지뷰 데이터가 주류를 이루고 있다는 점이 특징이다.
그림 2
TimesFM 1.0 개요도
출처 Reprinted with permission from A. Das et al., “A decoder-only foundation model for time-series forecasting,” in Proc. Int. Conf. Mach. Learn., (Vienna, Austria), vol. 235, July 2024, pp. 10148-10167.
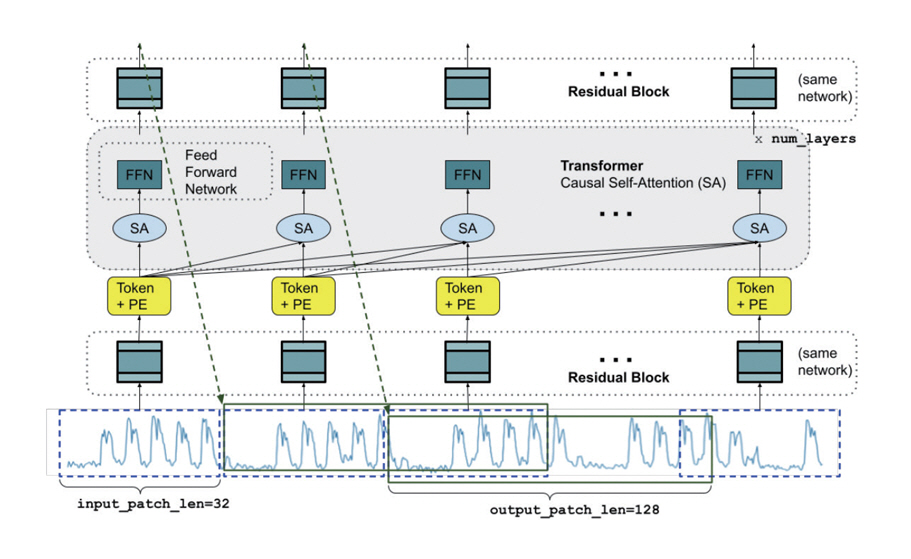
TimesFM은 현재 1.0, 2.0 버전을 거쳐 현재 2.5 버전이 오픈소스로 발표되었다. 최신 버전에서는 예측 입력 및 출력값의 지원 범위를 크게 확정하고, 시계열 데이터의 주기를 자동으로 분류하여 알맞은 세부 모델을 선택하는 기능이 추가되었다. 다양한 사이즈의 모델을 공개하는 다른 시계열 파운데이션 모델과 달리 버전별로 단일 사이즈의 모델만을 공개하고 있다.
3. Chronos
Amazon에서는 T5(Text-to-Text Transfer Transformer) 구조를 사용하여 다양한 사이즈의 모델이 제공되는 Chronos 모델을 공개하였다[6]. 기후 데이터와 에너지 생산 및 소비 데이터를 중심으로 한 840억 개 이상의 시계열 데이터로 학습하였으며, 과거 시계열 데이터 입력 시 데이터의 타임스탬프가 제공되지 않아도 예측 가능하다는 특징이 있다. Chronos 초기 모델의 구조는 TimeGPT-1과 유사하지만, 타겟 변수만을 입력으로 받는다는 한계가 있다.
Chronos는 이후 패칭 기법을 도입하여 예측 속도를 크게 향상시킨 Chronos-Bolt 모델과 인코더 단독 모델로 개량되어 더욱 속도를 향상시키면서도 다변량 및 공변량 시계열 데이터 예측과 같은 고급 기능이나 사용자의 추가적인 데이터를 활용한 파인튜닝 기능 등을 모두 지원하는 Chronos-2 모델(그림 3)이 모두 오픈소스로 발표되었다[7]. 디코더 기반 생성형 구조를 사용하는 대신, 타겟 시계열 데이터의 미래값에 대한 퀀타일 값(0.05부터 0.95까지의 0.05 단위 및 0.01과 0.99)을 직접 예측한다.
그림 3
Chronos-2 개요도
출처 Reprinted with permission from A. F. Ansari et al., “Chronos-2: From Univariate to Universal Forecasting,” arXiv preprint, 2025. doi: 10.48550/arXiv.2510.15821
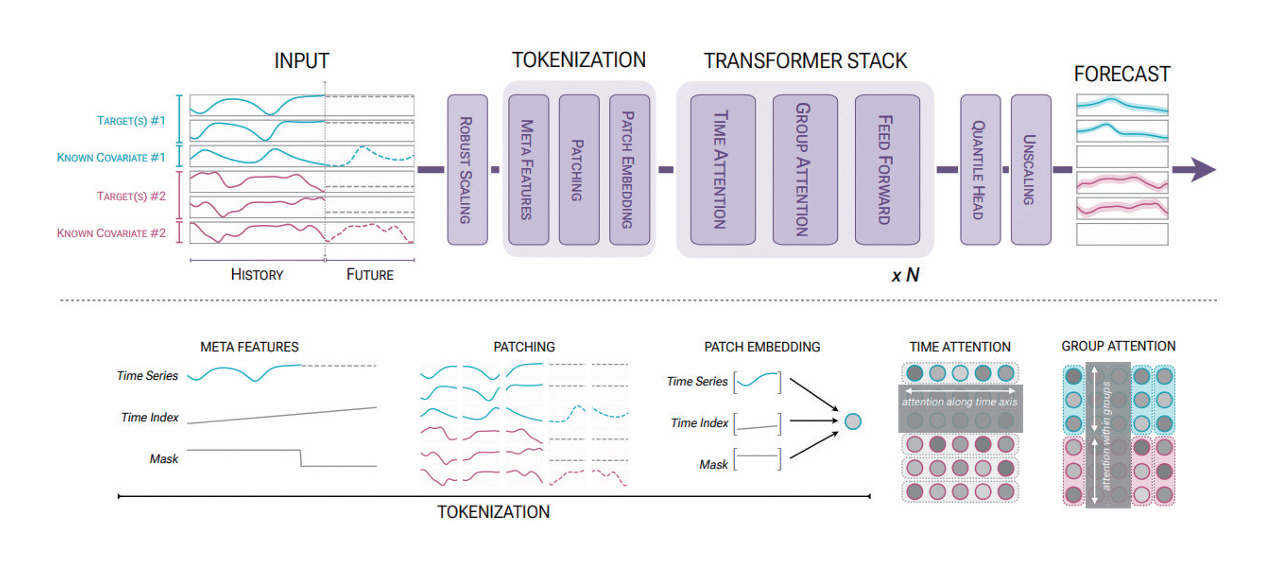
4. Moirai
미국의 Salesforce에서는 PyTorch 기반 거대 스케일 시계열 데이터 학습 라이브러리인 Uni2TS(Unified Training of Universal Time Series Transformers)를 개발하였으며, 이를 활용한 시계열 파운데이션 모델인 Moirai를 공개하였다[8]. 인코더 단독 구조 모델로, 다차원 시계열 데이터를 패칭 및 직렬연결 처리하고 Full Self-attention 구조를 통해 학습하여 다변량 시계열 데이터 예측이 가능하다는 특징이 있다. 빌딩 에너지 데이터를 위주로 하는 2,300억 개 이상의 시계열 데이터로 학습하였으며, 해당 데이터셋 또한 오픈소스로 공개되어 있다. 디코더 기반 생성형 예측 모델이나 퀀타일 기반 Chronos-2와 달리, Moirai 모델은 타겟 시계열 데이터의 미래값을 네 가지 확률 분포(t분포, 로그 정규 분포, 음이항 분포, 정규 분포)의 합성 분포로 예측한다.
Moirai는 이후 1.1 버전과 Moirai-MoE, Moirai 2.0 버전으로 개량되어 오픈소스로 발표되었다. Moirai-MoE 이후의 모델은 디코더 단독 모델로 변경되었으며, 특히 Moirai-MoE는 다양한 종류의 시계열 데이터를 분류하여 각각의 세부 모델을 학습시킨 후, 예측하고자 하는 시계열 데이터의 분류 과정을 거쳐 해당되는 세부 모델만을 사용하여 예측하는 MoE(Mixture of Experts, 그림 4) 구조를 사용하였다[9].
그림 4
Moirai(좌), Moirai-MoE(우) 개요도
출처 Reprinted from X. Liu et al., “Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts,” in Proc. Int. Conf. Mach. Learn., (Vancouver, Canada), vol. 267, July 2025, pp. 38940-38962.
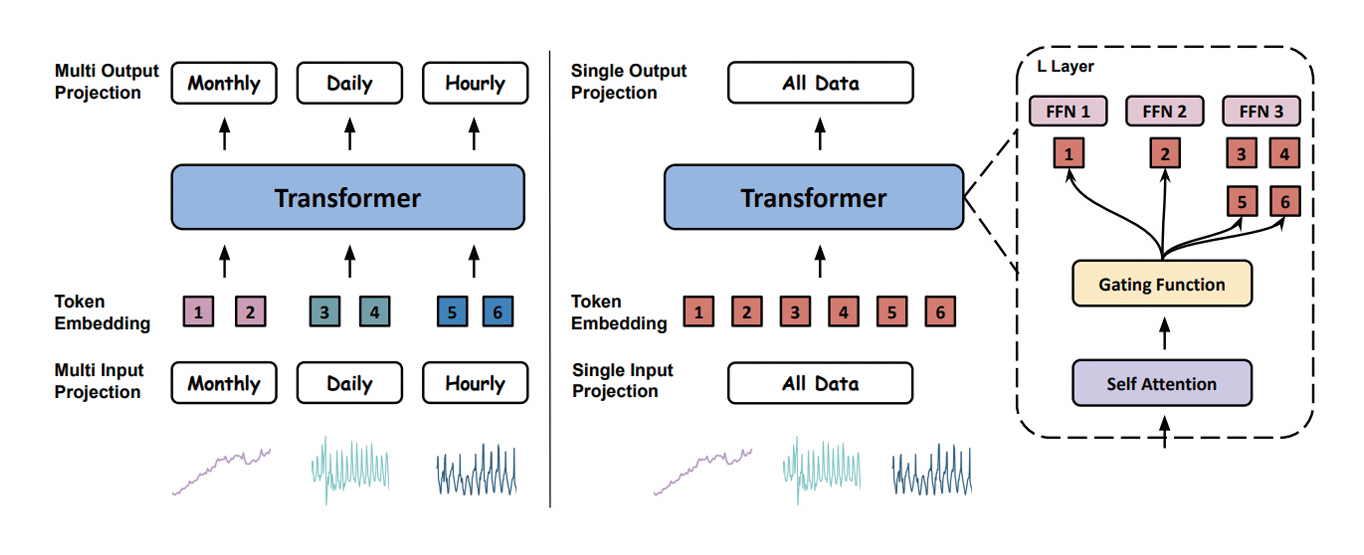
Moirai-MoE를 제외한 다른 Moirai 모델들은 기반이 되는 Uni2TS 라이브러리를 활용한 파인튜닝 기능이 지원된다.
5. 시계열 파운데이션 모델의 장점 및 한계
시계열 파운데이션 모델이 가지는 가장 큰 장점은 사용하고자 하는 도메인에서 별도의 데이터가 없는 경우에도 최소한의 과거 데이터를 통한 제로샷 예측만으로 기존 통계 기반 예측 대비 준수한 성능을 보인다는 점이다. 다만, 특정 도메인에 대한 전문 지식을 기반으로 하는 모델이 아니기 때문에 간헐적으로 급증하거나 급감하는 시계열 데이터에 대한 예측 성능은 필연적으로 떨어지게 된다.
TimeGPT 계열이나 Chronos-2와 같은 최신 모델들은 병행하는 제어 변수의 변화를 고려한 공변량 예측이 가능하기에 현실에 반영될 수 있는 예측이 더욱 용이하다. 다만, 다변량 예측이나 공변량 예측의 경우 모든 시계열 데이터가 같은 시간축을 공유한다는 전제가 필요하므로 임퓨테이션이나 인터폴레이션과 같은 데이터 전처리가 필요할 수 있다.
표 1에서 볼 수 있듯이 시계열 파운데이션 모델은 LLM보다 확연히 작은 모델 크기 덕분에 일반 가정용 단말에서도 문제없이 구동할 수 있다는 장점이 있다. 하지만 CPU만으로 구동하려고 할 경우 연산 속도가 확연히 느려지기 때문에[10], 안정적인 구동을 위해서는 경량화 NPU와 같은 솔루션이 고려되어야 할 수 있다.
시계열 파운데이션 모델을 개발하고자 하는 관점에서 보면, 모델 구조 구축 및 학습 데이터 처리 방식이 LLM과 상당 부분 호환되기 때문에, 새로운 LLM 모델 구조를 개발하는 과정에서 시계열 파운데이션 모델을 경량화된 파일럿 모델로 검증 가능하다는 특징을 가진다.
시계열 파운데이션 모델이 제공하는 확률적 예측 기능은 미래 예측 결과를 활용하는 면에 있어서 보다 고도화된 분석 및 최적화 기능을 제공한다. 다만 디코더 모델을 사용할 경우 생성형 모델의 특성상 예측 시간이 상대적으로 길어지고, 인코더 단독 모델을 사용할 경우 예측 분포가 개발 단계에서 정해진 확률 분포에 종속된다는 한계가 있다.
IV. 시계열 파운데이션 모델 학습용 데이터셋 및 벤치마크 기술 동향
1. 시계열 데이터셋 동향
LLM과 마찬가지로 시계열 파운데이션 모델 개발에서는 모델의 구조만큼이나 학습을 위한 데이터 확보가 중요한 이슈이다. 시계열 예측의 중요성이 대두된 이후 인공지능 학습을 위한 거대 시계열 데이터셋을 제공하기 위한 노력들이 있었다. 현재 오픈소스로 공개된 대규모 데이터셋으로는 Monash[11], LOTSA[8], Time-300B[12] 등이 있다. 표 2에서 볼 수 있듯이 시계열 파운데이션 모델을 학습하기 위해서는 기후, 에너지, 교통, 의료, 소비, 경제, 금융, 인터넷, 관광 등 모든 분야를 망라하는 시계열 데이터가 필요하다.
표 2 Monash Dataset 상세
최근에는 거대 모델 학습을 위한 실제 시계열 데이터 증가가 어려워짐에 따라, 다양한 이론 모델을 기반으로 인공적인 시계열 데이터를 생성하여 시계열 파운데이션 모델을 학습하는 방법이 연구되고 있다. Prior Labs[13]와 Amazon[7]의 연구에 따르면, 인공 데이터만으로 학습한 모델이 인공 데이터와 실제 데이터를 모두 사용하여 학습한 모델과 크게 성능 차이가 나지 않는 것으로 나타났다. 향후 시계열 데이터 확보가 어려운 분야를 시계열 파운데이션 모델에 반영하기 위해서는 이러한 인공 데이터 작성 기술이 중요해질 것으로 생각된다.
2. 시계열 예측 모델 벤치마크 기술 동향
다양한 시계열 파운데이션 모델이 개발되면서 모델 간 성능 비교를 하기 위한 공개 벤치마크 플랫폼들이 제공되고 있다. 시계열 파운데이션 모델 개발 초기에는 가장 다양한 도메인이 조합된 Monash 데이터셋에 대한 자체 벤치마크가 주류였으나, 단변량 시계열 데이터에 한정되어 있다는 한계가 있었다. 이후 다변량 시계열 데이터가 포함된 벤치마크인 TFB가 제안되었으며[14], 이후 확률적 예측 결과에 대한 평가가 가능한 ProbTS가 제안되었다[15].
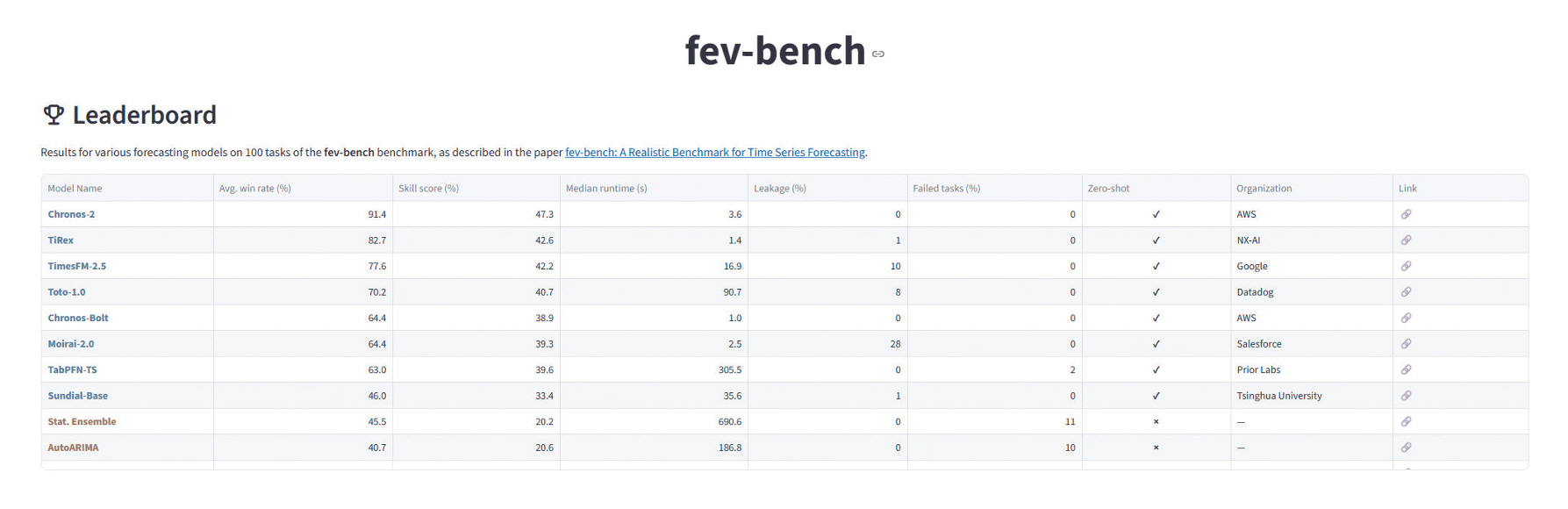
이후 다변량 및 확률예측 평가 기능을 포괄하면서 시계열 데이터 도메인을 확장시킨 GIFT-Eval 벤치마크가 리더보드 기능을 제공함과 함께 Hugging-face에 공개되어 모델 간 성능 비교를 더욱 쉽게 할 수 있도록 하였다[16]. 특히 GIFT-Eval은 도메인, 예측주기, 예측종류 등 다양한 조건에 대한 세부 벤치마크 기능 또한 제공하고 있다. 가장 최근에 발표된 fev-bench는 데이터 도메인을 더 확장하였으며, 그림 5와 같이 임의의 두 예측 모델을 직접 비교하는 방식으로 벤치마킹한다. 특히, 공변량 시계열 예측 평가가 가능한 데이터셋을 추가하여 해당 성능을 측정할 수 있도록 하였다[17].
V. 결론
본고에서는 시계열 파운데이션 모델과 관련 기술 및 최신 연구 동향에 대해 살펴보았다. 시계열 파운데이션 모델은 대규모 데이터로 사전학습된 모델로서, 적용 대상이 되는 다양한 현장에서 별도의 대량 학습 데이터 없이도 비교적 손쉽게 적용할 수 있다는 장점이 있다. 기존의 시계열 파운데이션 모델 개발은 트랜스포머 구조를 활용한 단일 시계열 데이터의 장기적 예측을 수행하는 연구가 진행되었으며, 최근에는 상호 관련성이 있을 수 있는 다변량 및 공변량 예측 기능을 제공하는 모델 연구가 시작되고 있다. 구체적으로, 기후, 에너지, 교통, 금융, 소매, 의료, 인터넷 등 시계열 분석이 필요한 다양한 분야에 적용하는 연구가 활발히 진행되고 있으며, Amazon, Google, Salesforce, Alibaba와 같은 대기업뿐만 아니라 많은 스타트업 기업 또한 연구에 참여하고 있다.
시계열 파운데이션 모델은 활용성 면에서는 엣지 컴퓨팅 환경에서도 구동 가능할 정도의 경량 모델이라는 장점이 있다. 하지만 모델을 직접 개발하는 면에서는 여전히 어느 정도의 컴퓨팅 환경이 필요하며, 특히 기존 공개 데이터의 한계를 넘어 한국 환경에 특화된 연구를 하려면 학습 데이터로 최소 수 십억 단위의 국산 시계열 데이터가 필요할 것으로 예상된다.
많은 시계열 파운데이션 모델이 개발되면서 이들을 비교할 수 있는 벤치마크 기술도 같이 발전하였으나, 특정한 용도로 시계열 파운데이션 모델을 사용하기 위해서는 해당 도메인의 데이터를 사용하여 직접 예측 성능을 검증해 보는 것이 바람직하다[10]. 또한, 성분 분석 기법과 같이 인공지능 외적인 면에서도 주어진 시계열 파운데이션 모델의 예측 정확도를 개선시킬 수 있는 기술 연구가 필요하다[18]. 마지막으로 예측된 미래의 결과를 유용하게 활용할 수 있도록 다양한 분야의 추가적인 연구가 필요하다.
용어해설
다변량 시계열 데이터 예측 상관관계가 있을 것으로 예상되는 복수의 시계열 데이터를 동시에 예측하는 방법
공변량 시계열 데이터 예측 별개의 예측 혹은 제어 가능한 시계열 데이터를 참고하여 목표 시계열 데이터를 예측하는 방법
제로샷(Zero-shot) 별도의 프롬프트 또는 학습데이터 없이 과거 시계열 데이터만으로 미래 데이터를 예측하는 방법
패칭(Patching) 짧은 기간 동안의 시계열 데이터를 하나의 블록으로 보고 이러한 블록들이 서로 겹치며 이어지게 하여 전체 시계열 데이터를 분석하는 방법
O. B. Mulayim et al., "Are Time Series Foundation Models Ready to Revolutionize Predictive Building Analytics?," in Proc. ACM Int. Conf. Syst. Energy-Efficient Buildings, Cities, Transp., (Hangzhou, China), Nov. 2024, pp. 169-173.
Y. Nie et al., "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers," in Proc. Int. Conf. Learn. Representations, (Kigali, Rwanda), May 2023.
A. Auer et al., "TiRex: Zero-Shot Forecasting Across Long and Short Horizons with Enhanced In-Context Learning," in Proc. Adv. Neural Inf. Process. Syst., (San Diego, CA, USA), Dec. 2025.
A. Das et al., "A decoder-only foundation model for time-series forecasting," in Proc. Int. Conf. Mach. Learn., (Vienna, Austria), vol. 235, July 2024, pp. 10148-10167.
A. F. Ansari et al., "Chronos: Learning the Language of Time Series," Trans. Mach. Learn. Res., 2024.
A. F. Ansari et al., "Chronos-2: From Univariate to Universal Forecasting," arXiv preprint, 2025. doi: 10.48550/arXiv.2510.15821
G. Woo et al., "Unified Training of Universal Time Series Forecasting Transformers," in Proc. Int. Conf. Mach. Learn., (Vienna, Austria), vol. 235, July 2024, pp. 53140-53164.
X. Liu et al., "Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts," in Proc. Int. Conf. Mach. Learn., (Vancouver, Canada), vol. 267, July 2025, pp. 38940-38962.
S. Lee et al., "Comparison of Time-Series Foundation Models onpower plant emission data," in Proc. Int. Conf. ICT Convergence, (Jeju Island, Republic of Korea), Oct. 2025, pp. 1-4.
R. Godahewa et al., "Monash Time Series Forecasting Archive," in Proc. Adv. Neural Inf. Process. Syst., Track on Datasets and Benchmarks, 2021.
X. Shi et al., "Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts," in Proc. Int. Conf. Learn. Representations, (Singapore), Apr. 2025.
S. B. Hoo et al., "From Tables to Time: How TabPFN-v2 Outperforms Specialized Time Series Forecasting Models," in Proc. Adv. Neural Inf. Process. Syst. Workshop: Time Ser. Age Large Models, (Vancouver, Canada), Dec. 2024.
X. Qiu et al., "TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods," Proc. VLDB Endow., vol. 17, no. 9, 2024, pp. 2363-2377.
J. Zhang et al., "ProbTS: Benchmarking Point and Distributional Forecasting across Diverse Prediction Horizons," in Proc. Adv. Neural Inf. Process. Syst., Track: Datasets Benchmarks, (Vancouver, Canada), Dec. 2024.
T. Aksu et al., "GIFT-Eval: A Benchmark For General Time Series Forecasting Model Evaluation," arXiv preprint, 2024. doi: 10.48550/arXiv.2410.10393
O. Shchur et al., "fev-bench: A Realistic Benchmark for Time Series Forecasting," arXiv preprint, 2025. doi: 10.48550/arXiv.2509.26468
그림 1
TimeGPT-1 개요도
출처 Reprinted with permission from A. Garza et al., “TimeGPT-1,” arXiv preprint, 2023. doi: 10.48550/arXiv.2310.03589
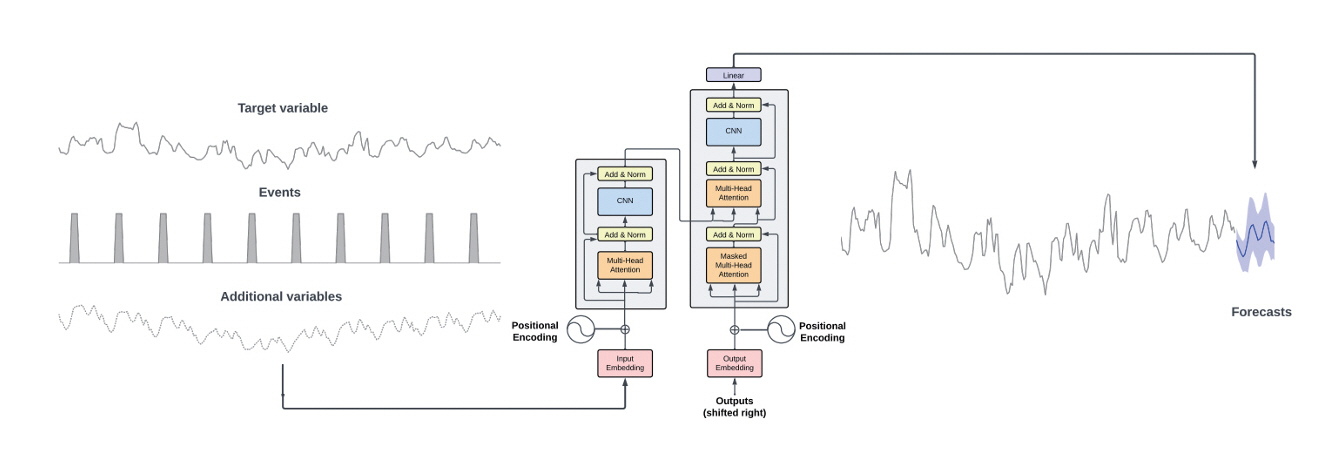
그림 2
TimesFM 1.0 개요도
출처 Reprinted with permission from A. Das et al., “A decoder-only foundation model for time-series forecasting,” in Proc. Int. Conf. Mach. Learn., (Vienna, Austria), vol. 235, July 2024, pp. 10148-10167.
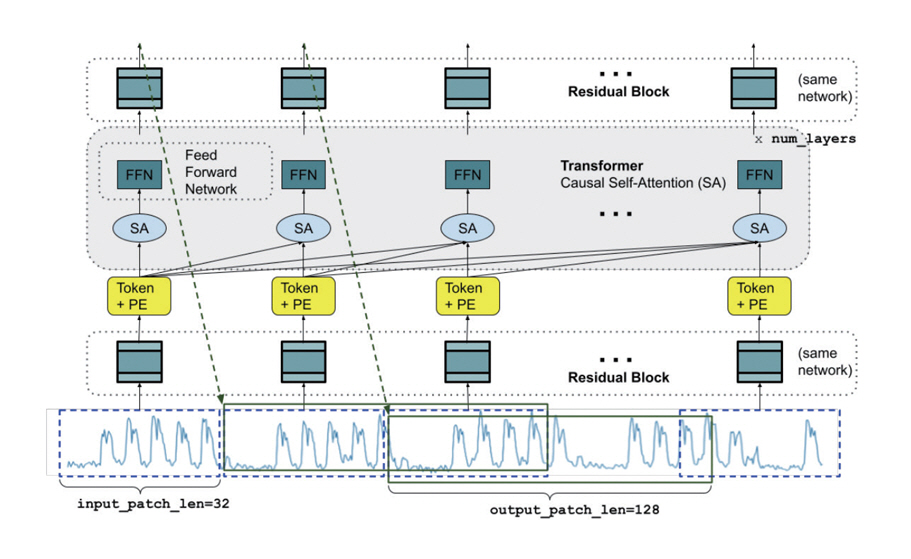
그림 3
Chronos-2 개요도
출처 Reprinted with permission from A. F. Ansari et al., “Chronos-2: From Univariate to Universal Forecasting,” arXiv preprint, 2025. doi: 10.48550/arXiv.2510.15821
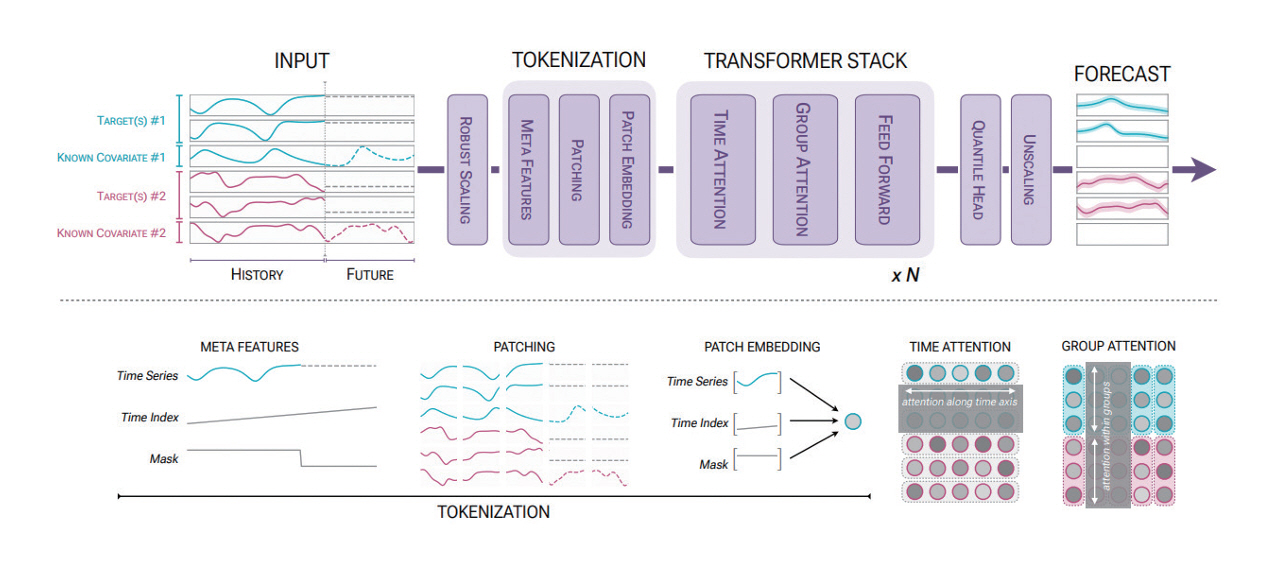
그림 4
Moirai(좌), Moirai-MoE(우) 개요도
출처 Reprinted from X. Liu et al., “Moirai-MoE: Empowering Time Series Foundation Models with Sparse Mixture of Experts,” in Proc. Int. Conf. Mach. Learn., (Vancouver, Canada), vol. 267, July 2025, pp. 38940-38962.
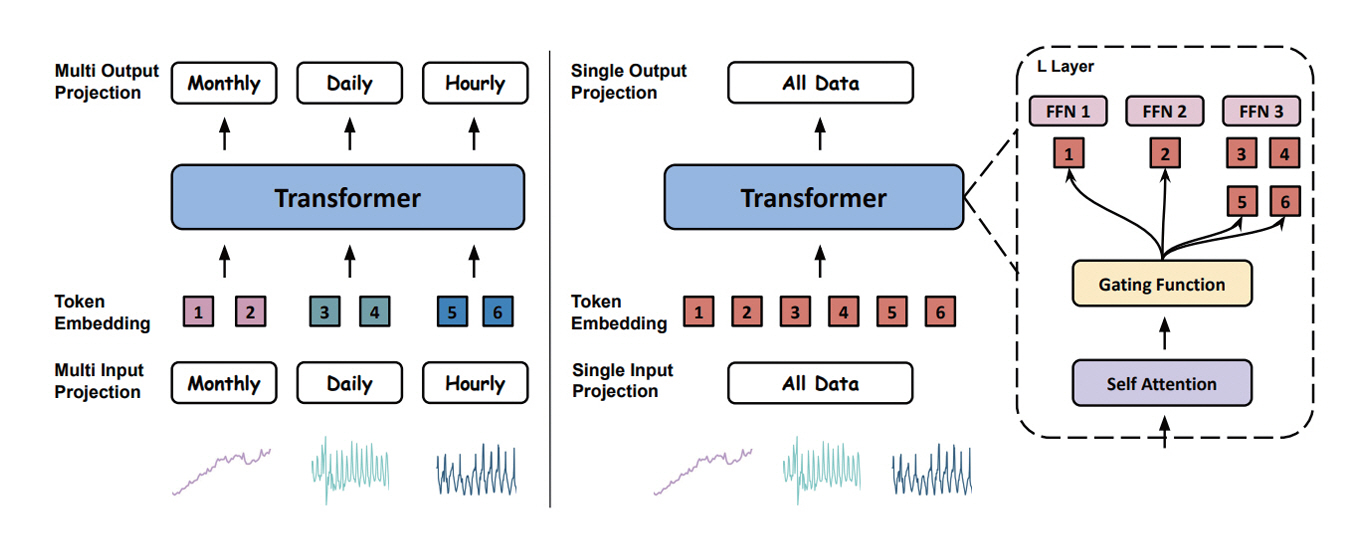
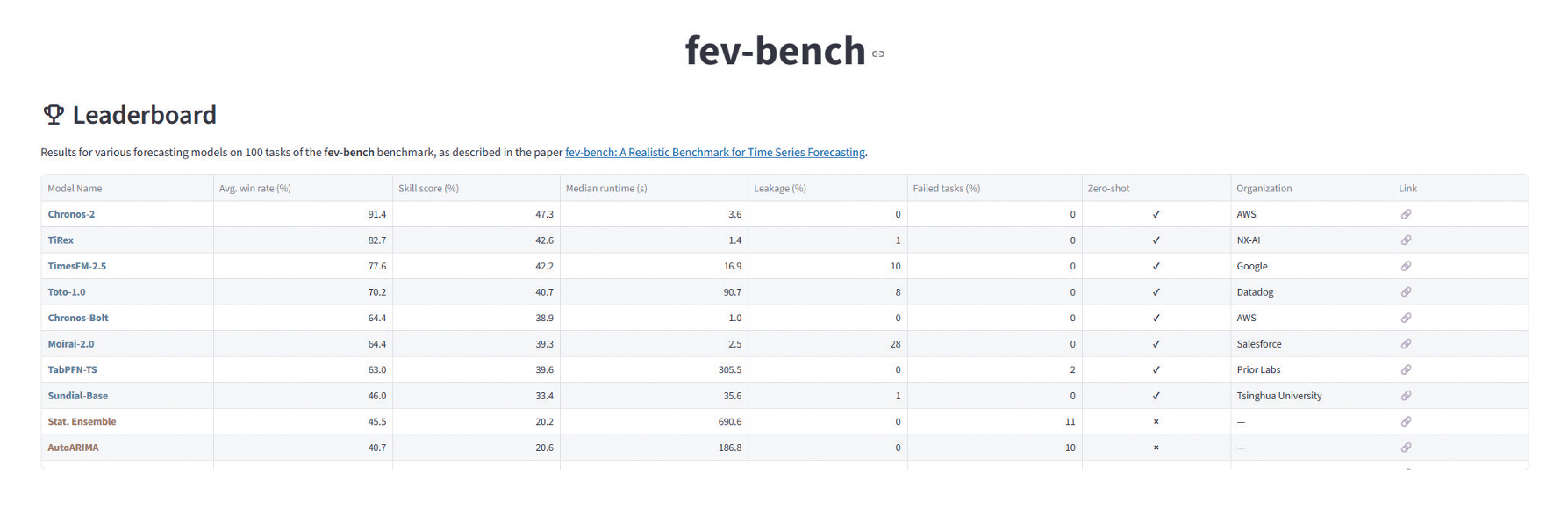
표 1 시계열 파운데이션 모델 비교
표 2 Monash Dataset 상세
출처 Reprinted with permission from R. Godahewa et al., “Monash Time Series Forecasting Archive,” in Proc. Adv. Neural Inf. Process. Syst., Track on Datasets and Benchmarks, 2021.
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.