양자 오류 완화 연구 개발 동향
Trends in Research and Technologies on Quantum Error Mitigation
- 저자
-
오현수양자컴퓨팅연구실 pypaul@etri.re.kr 황용수양자컴퓨팅연구실 yhwang@etri.re.kr
- 권호
- 41권 3호 (통권 220)
- 논문구분
- 일반논문
- 페이지
- 96-107
- 발행일자
- 2026.06.01
- DOI
- 10.22648/ETRI.2026.J.410309
 본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.
본 저작물은 공공누리 제4유형: 출처표시 + 상업적이용금지 + 변경금지 조건에 따라 이용할 수 있습니다.- 초록
- Near-term quantum computers operate in the presence of high-intensity noise that makes it difficult to obtain reliable computational results without excessive hardware overhead. Therefore, quantum error mitigation (QEM) has therefore emerged as a crucial set of techniques for improving the computational accuracy of noisy intermediate-scale quantum (NISQ) devices without requiring full-fledged quantum error correction. This paper reviews the fundamental principles, performance characteristics, and practical limitations of major QEM techniques proposed to date. We first introduce the concept of expectation-value-based error mitigation and discuss the notion of overhead, with particular emphasis on sampling overhead. Representative methods—including zero-noise extrapolation, probabilistic error cancellation, symmetry verification, virtual distillation, the Pauli check sandwich, and tensor-network-based error mitigation, are systematically analyzed in terms of their underlying mechanisms, experimental feasibility, and scalability. Recent experimental demonstrations and theoretical advances are highlighted, with a focusing on how different mitigation strategies trade accuracy against resource costs. This survey aims to provide a practical guide for selecting and combining QEM techniques tailored to specific hardware platforms and noise characteristics in the NISQ era.
Share
I. 서론
지난 30여 년간 양자정보기술은 전 세계적으로 많은 관심을 받아왔다. 그중에서도 양자컴퓨팅은 소인수분해, 데이터검색 분야에서 기존 컴퓨팅 대비 비약적인 성능 향상이 있을 것으로 주목받았고[1,2], 최근 들어 그 효용성이 신약/신소재 물질 발굴, 금융포트폴리오 최적화 분야에서도 발휘할 것으로 기대받고 있다.
이러한 장밋빛 기대 속에서 미국을 포함한 선진국들이 양자컴퓨터 연구개발에 많은 투자를 하고 있지만, 실생활 문제 해결에 사용될 수준의 양자컴퓨터 개발은 녹록지 않다. 소프트웨어 영역에서는 더 많은 응용 분야 발굴이 필요하고, 하드웨어 영역에서는 신뢰도 높은 큐비트 생성, 제어 및 측정 기술 개발이 필요하다. 일부 물리 큐비트 플랫폼에서는 99.99% 이상의 정확도로 동작하는 게이트 구현 기술을 확보했지만[3], 앞서 언급한 응용 분야에서 양자이득을 확인하기에는 여전히 부족한 수준이다[4].
노이즈에 취약한 양자 하드웨어에서 신뢰도 높은 양자 연산을 수행하기 위해서는 발생한 노이즈가 연산결과에 미치는 영향을 최소화해야 한다. 이를 위해서 그동안 다양한 기술이 제시되었다. 하드웨어 수준에서 오류 발생 자체를 줄이거나 느리게 만드는 양자 오류 억제(Quantum Error Suppression), 양자 연산 결과에 대해 고전적인 후처리를 적용해 연산 결과의 신뢰도를 높이는 양자 오류 완화(Quantum Error Mitigation), 그리고 양자연산 중간 과정에서 오류를 탐지하고 수정을 수행하는 양자 오류 정정(Quantum Error Correction)이 대표적이다[5-7].
양자 오류 완화는 종종 양자 오류 정정과 혼동되지만, 두 접근법은 목적과 구현 방식에서 근본적인 차이를 가지며 둘의 주요 차이점을 정리하면 표 1과 같다.
표 1 QEC와 QEM의 비교
| 목표 | 적용 시점 | 추가 큐비트 | 오류 제거 수준 | 장점 | 한계 | |
|---|---|---|---|---|---|---|
| QEC | 오류의 실시간 탐지 및 수정 | In-circuit | 다수의 큐비트 필요 | 이론적으로 완전한 정정 가능 | 장기적 확장성 | 높은 자원 요구량 |
| QEM | 측정 결과의 통계적 보정 | Post-processing & In-circuit | 대부분 적음 | 부분적 완화 | 구현 용이 & 단기 활용 가능 | 분산 증가 & 정확성 한계 |
양자 오류 정정은 물리 큐비트들을 다수 사용하여 논리 큐비트를 구성하고, 오류를 실시간으로 탐지하고 수정함으로써 오류의 누적을 방지하는 것을 목표로 한다[8-10]. 반면 QEM은 추가적인 논리 큐비트를 사용하지 않고, 제한된 하드웨어 자원하에서 양자 회로 실행 결과를 통계적으로 보정하여 오류의 영향을 감소시키는 데 초점을 둔다.
이러한 차이로 인해 QEC는 이론적으로 임의의 정확도를 달성할 수 있는 반면, 막대한 큐비트 자원과 높은 하드웨어 신뢰도를 요구한다. 반대로 QEM은 오류를 완전히 제거하지는 못하지만, 현재의 중간 규모의 노이즈가 발생하는 양자 시스템, 이른바 NISQ(Noisy-Intermediate Scale Quantum) 하드웨어 환경에서도 비교적 낮은 자원 요구량으로 적용 가능하다는 장점이 있다[11]. 따라서 QEM은 QEC를 대체하는 기술이라기보다는 오류 정정 기술이 실질적으로 구현되기 이전 단계에서 활용할 수 있는 보완적 접근법으로 이해할 수 있다[7].
대규모 범용 양자컴퓨팅을 구현하기 위해서는 물리 큐비트 단계에서는 오류 억제 기술을 적용하면서, 동시에 상위단계에서는 오류 정정 기술의 적용이 필요하다. 하지만, 오류 정정을 온전히 적용하기 위해서는 큰 비용이 요구된다. 오류 정정이 가능한 기준점인 오류임곗값(10-4~10-3)을 만족하는 물리 큐비트가 많이 요구된다. 응용문제의 크기에 따라 다르지만, 2,000비트 소인수분해 문제를 풀기 위해서는 107개 이상의 큐비트가 필요하다.
이러한 규모와 품질의 양자 하드웨어를 개발하기 위해서 양자컴퓨팅 기업들이 많은 투자를 진행하고 있지만, 아직은 가야 할 길이 멀다.
NISQ 시대에는 양자연산의 결과에서 노이즈의 영향을 억제하기 위해서 오류 완화 기술에 관한 연구가 활발하게 이루어지고 있다. 오류 정정 기술 대비 큐비트에 대한 요구사항이 적기 때문에 구현이 가능할 것으로 보이고, 클라우드 양자컴퓨터를 활용하여 오류 완화의 효용성을 입증하는 실험결과들이 지속적으로 발표되고 있다[13,14].
양자 오류 완화는 연산수행 후 측정 결과를 통계적으로 보정하거나, 양자연산을 여러 번 수행한 후 결과를 조합하는 방식으로 오류가 발생하지 않을 때의 연산결과와 최대한 가까운 결과를 얻는 기술이다. 하지만, 최대한 정확한 연산 결과를 얻기 위해서는 양자연산 반복 수행 횟수를 높여야 하며 측정 규모 이상의 양자연산회로에서는 효과가 없기도 하다.
본고에서는 현재까지 제안된 주요한 양자 오류 완화 기법들의 원리와 특징, 그리고 관련 실험 결과들에 대해서 살펴보도록 한다.
II. 양자 오류 완화 개요
양자 회로 실행을 통해 확보하고자 하는 최종 결과는 오류가 없는 이상적인 양자 상태 ρideal에서 특정 관측가능량 O에 대한 기댓값 <O>ideal=Tr(Oρideal)이다. 양자 시스템의 전체적인 물리적 특성과 동역학을 기술하는 해밀토니안(Hamiltonian)은 이러한 관측가능량이다.
양자컴퓨팅에서 기댓값은 동일한 양자 회로를 반복 실행하여 얻은 측정 결과들의 통계적 평균으로 추정된다. 대부분의 양자 알고리즘은 초기 양자 상태(예: ρ∈ = |0>⊗n < 0|⊗n)로부터 일련의 양자 연산을 수행함으로써, 이상적인 기댓값을 계산하는 것을 목표로 한다[2].
그러나 실제 양자 하드웨어에서는 양자 오류가 빈번하게 발생하며, 이에 따라 단일 회로 실행만으로는 정확한 결과를 얻기 어렵다. 양자 회로 실행 과정에서 오류가 발생하면, 이상적인 양자 상태는 여러 상태가 혼합된 혼합 상태(Mixed State) ρ로 변하게 된다. 이 혼합 상태를 측정하게 되면, 결과 Tr(Oρ)는 알고리즘이 의도한 이상적인 기댓값 Tr(Oρideal)과는 멀어지게 된다.
양자 오류 완화는 확보한 결괏값 Tr(Oρ)과 이상적인 기댓값 Tr(Oρideal) 사이의 차이를 줄이기 위한 기술이다[7]. 양자 회로 실행을 통해 확보한 결과에 포함된 오류의 영향을 줄이기 위해, 양자 오류 완화는 다음의 방법론을 적용하여 개발되었다[13].
• 양자 회로의 논리 구조는 유지한 채, 회로를 변형하거나 추가적인 게이트를 삽입하여 노이즈의 크기 또는 특성을 조절한다.
• 동일한 양자 회로를 반복 실행하여 통계적 정보를 수집한다.
• 후처리 알고리즘을 적용하여 노이즈로 인한 편향(Bias)을 제거하거나 감소시킨다.
이러한 과정으로 인해 오류가 완화된 결과를 얻기 위해서는 추가적인 자원 소모가 불가피하며, 다음과 같은 비용이 요구된다[7].
• 양자 회로 실행 횟수 증가
• 회로 깊이 증가
• 추가적인 큐비트 사용
이 중에서도 양자 회로 실행 횟수의 증가는 오류 완화 기법의 실용성을 결정짓는 핵심 요소로 작용하며, 이를 샘플링 오버헤드(Sampling Overhead)라고 부르며 Γ로 표기한다.
많은 연구 결과에 따르면, 오류의 영향을 더 강하게 제거할수록 필요한 샘플링 오버헤드는 급격히 증가하며, 일부 기법에서는 회로 깊이 또는 오류율에 대해 기하급수적으로 증가하는 것이 이론적으로 증명되었다[8]. 이는 양자 오류 완화가 본질적으로 편향 감소(Bias Reduction)와 분산 증가(Variance Amplification) 사이의 절충 관계(Trade-Off)를 가진다는 점을 시사한다.
따라서 NISQ 시스템에서 양자 회로를 효율적으로 실행하기 위해서는 오류 완화의 정확도 향상 효과와 이에 수반되는 오버헤드를 종합적으로 고려하여, 감당 가능한 비용 범위 내에서 최적의 오류 완화 전략을 선택하는 것이 중요하다. 최근의 연구들은 이러한 문제의식을 바탕으로, 고전적 후처리 기법과의 결합, 또는 문제 특화형 오류 완화 전략을 통해 샘플링 오버헤드를 완화하려는 방향으로 발전하고 있다.
III. 여러 양자 오류 완화 기법
1. Zero-Noise Extrapolation
Zero-Noise Extrapolation(ZNE)은 서로 다른 오류율을 갖는 양자 회로들의 실행 결과를 조합하여, 오류율이 0인 이상적인 회로의 기댓값을 추정하는 오류 완화 기법이다[15]. 본 기법은 2017년 K. Temme 등에 의해 제안된 Noise Amplification 개념을 기반으로 하며, 현재까지 가장 널리 연구되고 실험적으로 검증된 QEM 기법 중 하나로 자리 잡고 있다.
ZNE의 기본 가정은 회로의 오류율을 λ라 할 때, 관측값의 기댓값 <O(λ)>이 λ에 대해 매끄러운 함수로 표현될 수 있다는 것이다. 이때 우리가 목표로 하는 값은 오류율이 0인 경우의 기댓값 <O(0)>이며, 이를 직접 측정할 수 없기 때문에 서로 다른 오류율 λi에서 측정한 결과 <O(λi)>를 이용해 외삽(Extrapolation)을 수행한다.
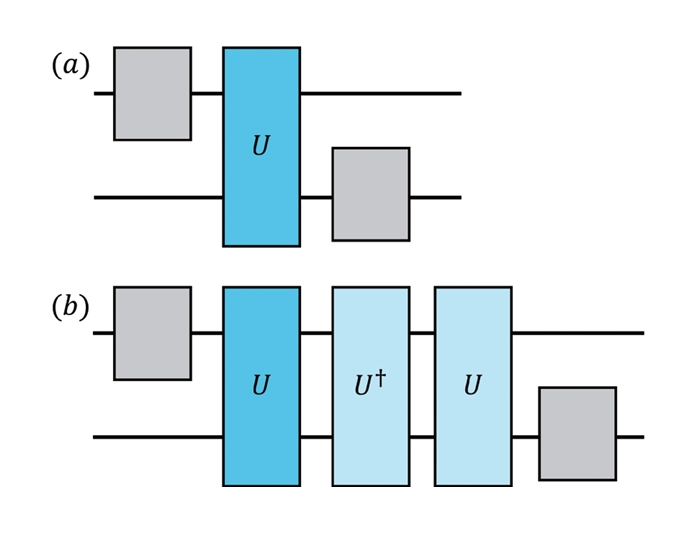
서로 다른 오류율의 양자 회로를 구현하기 위해, ZNE에서는 오류를 인위적으로 증폭시키는 folding 기법을 사용한다. 대표적으로, 전체 회로를 반복하여 오류를 증폭시키는 global folding과 회로의 일부 구간만을 반복하는 local folding이 있으며, 두 방법 모두 회로의 논리적 동작은 유지하면서 물리적 오류율만을 증가시키는 방식이다. 그림 1은 예시를 들며 folding을 통해 오류율을 증폭시키는 개념을 도식적으로 보여준다.
외삽 과정에서는 다항식(Polynomial) 또는 지수 함수(Exponential) 형태의 모델이 주로 사용되며, 사용되는 외삽 모델의 차수와 오류율 샘플 수는 ZNE의 정확도와 안정성에 직접적인 영향을 미친다. 일반적으로 더 많은 오류율 지점을 사용할수록 외삽의 정확도는 향상되지만, 그에 따라 요구되는 측정 비용 역시 급격히 증가한다.
ZNE의 가장 큰 특징이자 한계는 측정 오버헤드가 구조적으로 많이 증가한다는 점이다. 오류율이 서로 다른 여러 회로를 각각 충분한 통계 정확도로 실행해야 하므로, ZNE에서 요구되는 총 측정 횟수는 folding 횟수 및 외삽 차수에 따라 빠르게 증가한다. 동일한 통계적 정밀도를 유지하기 위한 샘플링 오버헤드는 다음과 같이 정의된다.
여기서 ZZNE는 수행을 위해 필요한 전체 측정 횟수이며, N0는 오류가 없는 이상적인 상황에서 동일한 정확도를 얻기 위해 필요한 측정 횟수이다.
보다 정량적으로는 ZNE에서 이상적인 기댓값은 서로 다른 오류율 λi에서 측정한 결과들의 선형 결합
이 표현은 ZNE의 측정 오버헤드가 단순히 여러 회로를 실행해야 한다는 점뿐만 아니라, 외삽 과정에서 필연적으로 등장하는 계수 구조에 의해 본질적으로 증폭됨을 보여준다. 특히 folding 인자가 커지거나 외삽 차수가 증가할수록
이러한 측정 오버헤드 증가는 단순한 계산 비용 증가에 그치지 않는다. 실제 하드웨어 환경에서는 회로 실행 횟수 증가로 인해 장비 드리프트, 시간에 따른 오류 특성 변화, 추가적인 환경 잡음이 발생할 수 있으며, 이는 외삽 모델의 신뢰성을 저하시킬 수 있다. 따라서 ZNE는 비교적 얕은 회로 깊이와 안정적인 오류 특성을 갖는 환경에서 가장 효과적으로 작동하는 것으로 알려져 있다.
그럼에도 ZNE는 하드웨어 독립적이며, 오류 채널에 대한 상세한 사전 정보가 필요하지 않다는 장점이 있다. 종합하면, ZNE는 구현이 비교적 단순하고 범용성이 높은 오류 완화 기법이지만, 측정 오버헤드가 빠르게 증가한다는 구조적 한계를 가진다.
ZNE는 다양한 플랫폼에서 실험적으로 검증되었으며, 2019년에는 IBM에서 6-큐비트 VQE 알고리즘에 대하여 ZNE를 적용하여 효과적으로 오류가 완화되었음을 보였다[16]. 2024년 Quek 연구팀에서 ZNE의 비용 하한을 더욱 정밀하게 분석하는 연구[17]를 진행하는 등 ZNE에 대한 연구가 지속적으로 진행되고 있다.
2. Probabilistic Error Cancellation
Temme, Bravyi, Gambetta에 의해 처음 제안된 Probabilistic Error Cancellation(PEC)은 오류가 없는 이상적인 회로의 실행은 실제 하드웨어에서 실행가능한 부회로(Sub-circuits)들의 선형 결합으로 표현할 수 있다는 이론에 기반한다[15].
PEC의 핵심 아이디어는 노이즈가 포함된 실제 양자 연산을 이상적인 연산과 노이즈 채널의 합성으로 모델링하고, 해당 노이즈 채널의 역연산을 확률적으로 구현하는 것이다. 이를 위해 이상적인 양자 회로는 실제 하드웨어에서 실행 가능한 부회로들의 선형 결합으로 분해되며, 이 과정에서 음의 계수를 포함하는 준확률 분해(Quasi-Probability Decomposition)가 사용된다. 이러한 음의 계수로 인해, PEC는 단순한 확률 샘플링이 아닌 가중치와 부호를 동반한 확률적 재가중(Resampling) 과정이 필요하다.
PEC는 다음과 같은 절차로 수행된다.
첫째, 사전에 정의된 기저 연산 집합으로부터 하나의 부회로를 확률적으로 선택한다.
둘째, 선택된 회로를 실행한 뒤 측정값에 해당 회로에 부여된 가중치와 부호를 곱한다.
셋째, 이러한 과정을 반복하여 평균을 취함으로써 이상적인 기댓값에 근접한 결과를 얻는다.
PEC의 가장 큰 특징이자 동시에 가장 큰 한계는 측정 오버헤드가 구조적으로 지수적으로 증가할 수 있다는 점이다. 준확률 분해 과정에서 등장하는 음의 계수들은 측정 결과의 분산을 크게 증폭시키며, 이에 따라 동일한 통계적 정확도를 확보하기 위해 필요한 측정 횟수는 급격히 증가한다. 일반적으로 PEC의 샘플링 오버헤드는 회로 길이 또는 적용된 오류 채널의 수에 대해 다음과 같은 형태로 증가하는 것으로 알려져 있다.
여기서 k는 회로 내 오류 채널이 적용되는 연산의 수이며, λ는 회로 내 평균 오류율을 나타낸다.
이와 같은 지수적 샘플링 오버헤드는 PEC가 이론적으로는 매우 강력한 오류 완화 기법임에도 불구하고, 실제 NISQ 환경에서의 적용을 제한하는 가장 중요한 요인으로 작용한다.
실험적으로는 2023년 Van Den 연구팀에서 IBM의 양자 프로세서를 활용한 연구에서 PEC 적용이 성공적으로 시연되었다[18]. 해당 연구에서는 효율적인 오류 채널 추정 기법을 도입하여 PEC의 실험적 구현 가능성을 보였으나, 여전히 측정 오버헤드가 실질적인 한계로 작용함이 함께 보고되었다. 이러한 문제를 완화하기 위해 최근에는 머신러닝 기반의 PEC 변형 기법들이 제안되고 있으며, 대표적으로 2024년 IBM Liao 연구팀은 학습 기반 재가중 방식을 통해 측정 오버헤드를 약 40~50% 수준으로 감소시키는 데 성공하였다[19].
3. Symmetry Verification
Symmetry Verification(SV)은 양자 알고리즘이 생성하는 이상적인 양자 상태가 특정한 대칭성(Symmetry)을 만족한다는 점에 착안한 오류 완화 기법이다[20]. ZNE나 PEC가 오류의 크기를 조절하거나 확률적으로 상쇄하는 방식이지만, SV는 물리적으로 허용되지 않는 상태를 측정 단계에서 제거함으로써 오류의 영향을 억제한다는 점에서 개념적으로 다른 접근법을 취한다.
보다 구체적으로, 관심 있는 양자 알고리즘의 해밀토니안 H가 어떤 대칭 연산자 S와 교환 관계를 만족한다고 가정하자. 이때 이상적인 양자 상태 ρideal는 S의 특정 고윳값(일반적으로 +1)에 대응하는 고유공간에 속한다. 그러나 실제 하드웨어에서 발생하는 노이즈는 이 대칭성을 깨뜨리는 상태 성분을 생성할 수 있으며, 이러한 성분은 알고리즘적으로 의미 없는 오류 상태로 해석할 수 있다.
SV는 양자 회로 실행 후 대칭 연산자 에 대한 측정을 수행하고, 해당 측정 결과가 목표 고윳값을 만족하는 경우만을 선택(Post-Selection)하여 기댓값을 계산한다. 수식적으로는, 대칭 연산자 S의 목표 고유공간으로의 사영 연산자 P를 적용함으로써 다음과 같은 상태를 얻는다.
이때 분모 Tr(Pρnoisy)는 사영 조건을 만족하는 측정 결과가 얻어질 확률을 나타내며, SV의 측정 오버헤드를 결정하는 핵심 요소로 작용한다. 이러한 대칭성 측정은 실제 구현에서는 일반적으로 보조 큐비트(Ancilla)와 제어 연산을 이용하여 수행되며, 그림 2와 같이 회로를 도식적으로 보여준다. 이러한 Ancilla 측정 결과에 따라 SV는 특정 대칭 고유공간으로의 투영을 실현하는 방식으로 구현된다.
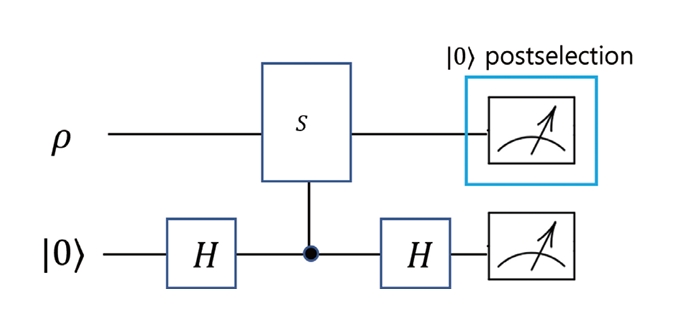
SV의 가장 중요한 특징은 ZNE나 PEC와 달리 측정 결과의 분산을 인위적으로 증폭시키지 않는다는 점이다. 대신, 전체 측정 결과 중 일부를 버리는 방식으로 오류를 억제하기 때문에, 샘플링 오버헤드는 사영 성공 확률의 역수에 비례하여 증가한다.
이는 SV의 측정 오버헤드가 회로 깊이나 오류 채널 수에 대해 직접적으로 지수적으로 증가하지 않으며, 대칭성이 비교적 잘 보존되는 환경에서는 상대적으로 완만하게 증가할 수 있음을 의미한다. 이러한 특성으로 인해 SV는 측정 효율성 측면에서 ZNE나 PEC보다 유리한 경우가 많다[16].
다만, SV의 성능은 활용 가능한 대칭성의 존재 여부와 품질에 크게 의존한다. 적용 가능한 대칭성이 많고 해당 대칭성이 노이즈에 대해 비교적 강인할수록 사영 성공 확률은 높아지고 측정 오버헤드는 감소한다. 반대로, 대칭성이 쉽게 깨지는 환경에서는 유효 샘플 수가 급격히 감소하여 SV의 효용성이 제한될 수 있다.
SV는 2019년 A. Kandala 연구팀에 의해 변분 양자 고윳값 추정(VQE) 실험에서 처음으로 실험적 검증이 이루어졌으며, 실제 하드웨어 환경에서도 대칭성 기반 오류 완화가 효과적으로 작동할 수 있음을 보였다. 이후 2020년에는 J. McClean 연구팀이 SV와 ZNE를 결합하여 측정 결과의 분산을 감소시키는 하이브리드 오류 완화 전략을 제안하였고[21], 2022년에는 Van Den 연구팀이 SV가 특히 측정 오류에 대해 효과적임을 보고하였다[22].
4. Virtual Distillation
Virtual Distillation(VD)은 동일한 오류 특성을 갖는 양자 상태의 여러 복제본을 이용하여, 노이즈로 인해 혼합된 상태로부터 이상적인 순수 상태 성분을 강조하는 오류 완화 기법이다[23,24]. ZNE, PEC, SV가 단일 회로 실행 결과의 통계적 처리에 초점을 두지만, VD는 상태의 스펙트럼 구조 자체를 이용하여 오류를 억제한다는 점에서 개념적으로 구별된다.
이상적인 양자 알고리즘은 오류가 없는 순수 상태 |ψ >를 생성하지만, 실제 하드웨어 환경에서는 노이즈로 인해 출력 상태가 혼합 상태 ρ로 변한다. 해당 혼합 상태는 다음과 같은 고윳값 분해로 표현할 수 있다.
여기서 λi는 고윳값이며, 이상적인 상태에 대응되는 고윳값 λ0가 가장 큰 값을 갖는다고 가정한다. VD의 핵심 아이디어는 동일한 상태 ρ의 여러 복제본을 결합함으로써 λ0에 해당하는 성분을 상대적으로 증폭시키는 것이다.
VD에서는 동일한 양자 회로를 M번 실행하여 얻은 상태 ρ⊗M에 대해 순환 연산자(Cyclic Permutation)를 적용한다. 그림 3은 이러한 과정의 VD 회로를 도식적으로 보여준다. 이 과정을 통해 얻은 정화된 상태는 효과적으로 ρM에 비례하는 형태를 가지며, 고윳값 구조에 따라 다음과 같은 성질을 갖는다.
이로부터 M가 증가할수록
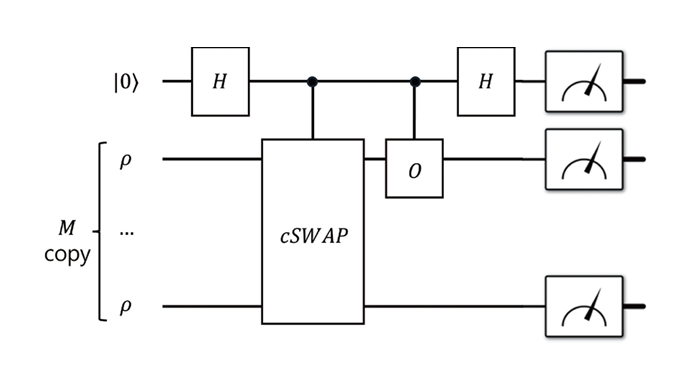
VD의 중요한 특징은 ZNE나 PEC처럼 측정 결과의 분산을 인위적으로 증폭시키지 않는 대신, 추가적인 회로 자원과 복제본 수를 요구한다는 점이다. 동일한 상태의 여러 복제본을 동시에 다루기 위해서는 회로 깊이 증가와 다수의 큐비트가 필요하며, 이는 VD의 실험적 적용에 있어 주요 제약으로 작용한다.
또한, VD는 기댓값 계산을 위해 두 가지 측정 과정이 필요하다. 하나는 정화된 상태 ρM의 정규화 계수를 추정하는 과정이며, 다른 하나는 해당 상태에서 관측자 O의 기댓값을 측정하는 과정이다. 이 두 측정값의 비율을 취하는 후처리 과정에서, 측정 오버헤드는 회로 오류율과 복제본 수 M에 따라 다음과 같이 증가한다.
이는 VD에서 측정 오버헤드가 분산 증폭보다는 상태 정화 성공 확률에 의해 결정됨을 의미하며, SV의 Post-Selection 기반 오버헤드 증가와 개념적으로 유사한 구조를 가진다. 다만, SV가 단일 대칭성 조건에 의존하는 반면, VD는 상태의 고윳값 구조에 기반하므로 보다 일반적인 상황에 적용 가능하다는 장점이 있다.
2024년 Xiao Yuan 연구팀은 VD는 이상적인 상태 정화 이론과 달리, 실제 회로 노이즈가 존재할 경우 성능이 저하될 수 있다는 문제점을 분석하고, 이를 개선하기 위한 Circuit-Noise-Resilient Virtual Distillation (CNR-VD) 기법을 제안하였다[25]. 이후 동일한 Xiao Yuan 연구팀이 VD의 비용 구조를 정밀하게 분석하고, 측정 오버헤드와 복제본 수 사이의 경계를 제시함으로써 VD의 이론적 이해를 크게 진전시켰다[26].
5. Pauli Check Sandwich
Pauli Check Sandwich(PCS)는 확률적 오류 상쇄 계열의 양자 오류 완화 기법으로, 회로 실행 중 오류의 구조를 국소적으로 검증하고 이를 측정 단계에서 선별적으로 제거하는 접근법이다[27]. PCS는 앞서 소개한 PEC와 달리 준확률 분해에 따른 분산 폭증을 피하고, SV 및 VD와 마찬가지로 검증 성공 확률을 통해 측정 오버헤드를 제어한다는 특징을 가진다.
PCS의 핵심 아이디어는 양자 회로를 구성하는 각 기본 연산 주위에 보조 큐비트(Ancilla)를 이용한 검증 연산을 삽입하는 것이다. 구체적으로, 회로 내의 각 양자 연산 U에 대해 그 앞뒤로 제어된 검증 연산을 배치함으로써, 해당 연산 구간에서 발생한 오류가 특정 검증 조건을 위반하는지를 측정할 수 있도록 한다. 이때, 오류가 발생하더라도 검증 연산을 통해 오류 성분의 일부가 상쇄되거나 식별 가능해진다.
이러한 검증 연산은 여러 층(Layer)으로 반복 적용될 수 있으며, 각 층은 서로 독립적인 오류 성분을 검사하도록 설계된다. 그림 4는 이러한 과정의 PCS 회로를 도식적으로 보여준다. 결과적으로, 여러 검증 층을 쌓을수록 오류에 대한 판별 능력은 향상되지만, 동시에 검증 조건을 만족하는 측정 결과의 비율은 감소하게 된다. PCS는 이 중에서 모든 검증 조건을 만족한 측정 결과만을 선택하거나, 후처리 알고리즘을 통해 가중치를 부여함으로써 기댓값을 추정한다.
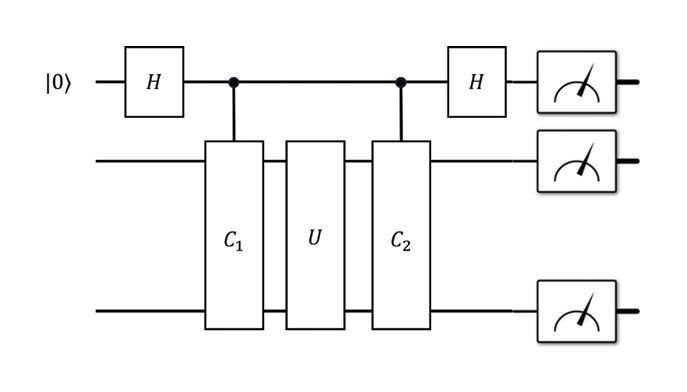
PCS에서 측정 오버헤드는 검증 성공 확률에 의해 직접적으로 결정된다. 각 검증 층에서 Ancilla가 정상 상태로 측정될 확률을 p라고 할 때, m개의 검증 층을 적용하면 전체 검증을 통과할 확률은 pm에 비례한다. 따라서 PCS의 샘플링 오버헤드는 다음과 같이 증가한다.
이는 PCS가 측정 오버헤드를 분산 증폭이 아닌 확률적 선택의 형태로 지불함을 의미하며, SV 및 VD와 유사한 구조를 가진다. 다만, SV가 전역적인 대칭성에 의존하는 반면, PCS는 회로의 국소적 연산 단위에서 오류를 검증할 수 있어 더욱 세밀한 오류 제어가 가능하다는 차별점을 가진다.
PCS의 또 다른 장점은 복잡하고 예측하기 어려운 실제 하드웨어 오류를 직접적으로 역산하지 않고도, 검증 가능한 오류 성분만을 통계적으로 제거할 수 있다는 점이다. 이로 인해 PEC에서 요구되는 정밀한 오류 채널 추정 없이도 오류 완화 효과를 얻을 수 있으며, 측정 결과의 분산 역시 상대적으로 안정적으로 유지된다.
최근에는 PCS의 실용성을 확장하려는 연구도 활발히 진행되고 있다. 2025년 Lucas Dagguerre 연구팀은 양자 연산을 중단하지 않고도 PCS 구조를 활용하여 오류 채널과 관련된 정보를 추출할 수 있음을 보였으며, 이를 통해 PCS가 오류 완화뿐만 아니라 오류 특성 분석 도구로도 활용될 수 있음을 제시하였다[28].
6. Tensor Network Mitigation
Tensor-Network Error Mitigation(TEM)은 양자 회로 실행 결과를 정보완비 측정(Informationally Complete Measurement)으로 수집한 뒤, 고전적인 텐서 네트워크 계산을 통해 오류의 영향을 제거하는 오류 완화 기법이다[29,32]. TEM은 앞서 소개한 ZNE, PEC, SV, VD, PCS와 달리, 오류 완화의 핵심 부담을 측정 오버헤드가 아닌 고전적 후처리 계산으로 이전한다는 점에서 독특한 접근법을 취한다[30].
TEM의 기본 아이디어는 다음과 같다. 주어진 양자 회로를 반복 실행하여 정보완비 양의 연산자값 측정(IC-POVM: Informationally Complete Positive Operator-Valued Measurement)을 수행하면, 측정 결과로부터 출력 상태에 대한 충분한 통계적 정보를 확보할 수 있다[32]. 이 측정 결과들을 이용해 측정 연산자의 역변환을 적용함으로써 노이즈가 포함된 출력 상태 ρnoisy를 고전적으로 추정한다.
이후 TEM에서는 오류 채널의 역연산을 직접 구현하는 대신, 해당 역연산을 단순한 구조의 텐서 네트워크로 표현하고 이를 고전적으로 수축(Contract)함으로써 관측가능량의 기댓값을 계산한다. 이 과정을 반복하여 얻은 결과를 평균함으로써 이상적인 기댓값에 근접한 추정치를 얻는다.
중요한 점은 TEM에서 사용되는 오류 역연산이 물리적으로는 완전히 양의 연산이 아닐 수 있지만, 고전적 계산 과정에서는 이러한 제약이 문제가 되지 않는다는 것이다. 이로 인해 TEM은 PEC와 달리 준확률 분해에 따른 분산 폭증을 피할 수 있으며, 측정 오버헤드를 근본적으로 줄일 가능성을 제공한다.
실제로 TEM의 가장 큰 장점은 측정 오버헤드의 스케일링에 있다. PEC의 경우, 측정 오버헤드가 회로 길이에 대해 지수적으로 증가하는 반면, TEM에서는 동일한 정밀도를 유지하기 위해 필요한 측정 횟수가 PEC의 제곱근 수준으로 증가하는 것으로 알려져 있다. 즉, 샘플링 오버헤드는 다음과 같은 형태를 가진다.
이러한 특성은 TEM이 측정 비용 측면에서 PEC 및 ZNE 대비 구조적으로 유리함을 의미한다.
다만, 이러한 측정 오버헤드 감소는 고전적 계산 비용의 증가를 대가로 한다. 텐서 네트워크 수축 과정은 회로 구조와 시스템 크기에 따라 계산 복잡도가 급격히 증가할 수 있으며, 따라서 TEM의 실용성은 회로의 얽힘 구조, 국소성, 그리고 텐서 네트워크 표현의 효율성에 크게 의존한다. 즉, TEM은 모든 양자 회로에 보편적으로 적용 가능한 기법이라기보다는 구조적 제약이 있는 회로에 적합한 오류 완화 기법으로 이해할 수 있다.
텐서 네트워크 자체는 오래전부터 양자 다체계 시뮬레이션 분야에서 활발히 연구됐으나, 이를 양자 오류 완화에 본격적으로 적용하려는 시도는 비교적 최근에 이루어졌다[31]. 특히 2024년 Filippov 연구팀은 TEM이 PEC 및 ZNE와 비교하여 더 낮은 측정 오버헤드를 가지면서도 유사한 오류 완화 성능을 달성할 수 있음을 수학적으로 분석하였으며, 이를 통해 TEM이 독립적인 오류 완화 기법으로 자리 잡을 수 있는 이론적 근거를 제시하였다[12].
IV. 결론 및 제언
본고에서는 NISQ 시대의 현실적인 제약하에서 주목받고 있는 양자 오류 완화 기법들의 개념과 주요 연구 동향을 정리하고, 특히 측정 오버헤드 관점에서 QEM 기법들의 특성과 한계를 분석하였으며 기법별 오버헤드들을 표 2에 정리하였다.
표 2 오류 완화 기법별 오버헤드 비교
| ZNE | PEC | SV | VD | Pauli sandwich | TEM | |
|---|---|---|---|---|---|---|
| Qubit overhead | 0 | 0 | 1 | M | m | 0 |
| Sampling overhead |
| e4kλ | Tr(Pρnoisy)-1 |
| p-m | e2kλ |
| Reference | Quek, Yihui, et al.[17] | Van Den, Ewout, et al.[18] | McClean, Jarrod R., et al.[21] | Huggins, William J., et al.[23] | Gonzales, Alvin, et al.[27] | Filippov, Sergei, et al.[31] |
QEM은 QEC와 달리 논리 큐비트를 요구하지 않으며, 회로 실행 결과에 대한 고전적 후처리를 통해 오류의 영향을 줄이는 접근법이다. 이러한 특성으로 인해 QEM은 현재의 양자 하드웨어 환경에서도 적용 가능하다는 장점을 가지지만, 그 대가로 측정 횟수 증가, 회로 자원 확대, 또는 고전적 계산 비용 증가와 같은 다양한 형태의 오버헤드를 수반한다. 본고에서 살펴본 바와 같이, QEM의 실용성은 이러한 오버헤드를 얼마나 효율적으로 제어할 수 있는지에 의해 크게 좌우된다.
최근 QEM 연구의 핵심 방향은 오류를 완전히 제거하는 이상적인 보정보다는 제한된 자원하에서 통계적 안정성과 실질적인 성능 향상을 달성하는 방향으로 이동하고 있음을 알 수 있다.
향후 QEM 연구 및 실제 적용에 있어서는 다음과 같은 점들이 특히 중요해질 것으로 판단된다.
첫째, 오류 완화 성능을 측정 오버헤드 관점에서 체계적으로 이해하고 해석하려는 이론적 프레임워크의 정교화가 필요하다. 많은 오류 완화 기법들이 실험적으로 유효함이 입증되었으나, 각 기법에서 측정 오버헤드가 어떤 메커니즘에 의해 발생하고, 회로 깊이‧오류율‧관측자 선택에 따라 어떻게 스케일링되는지에 대한 통합적인 이해는 여전히 제한적이다. 이러한 분석은 기법 간 비교뿐만 아니라 실제 실험 설계 단계에서의 의사결정을 돕는 데 중요한 역할을 할 것이다.
둘째, 오류 완화 기법의 효과를 단일 성능 지표가 아닌 다차원적 자원 비용 관점에서 평가하는 시각의 확립이 요구된다. 기존 연구에서는 주로 편향 감소 여부나 최종 기댓값의 정확도에 초점이 맞추어져 왔으나, 측정 횟수, 회로 깊이, 추가 큐비트 수, 그리고 고전적 후처리 계산 비용을 함께 고려한 종합적 평가가 점차 중요해지고 있다. 이러한 관점은 특정 기법의 이론적 우수성과 실제 적용 가능성 사이의 간극을 보다 명확히 드러내는 데 이바지할 수 있다.
셋째, 머신러닝 기반 기법이나 고전적 최적화 기법과의 결합을 통해, 제한된 측정 데이터로부터 최대한의 정보를 추출하려는 연구가 더욱 중요해질 것으로 보인다. 특히 데이터 기반 접근법은 오류 모델에 대한 강한 가정을 요구하지 않으면서도, 측정 오버헤드를 완화할 수 있는 잠재력을 지니고 있어 향후 QEM 연구의 핵심 축 중 하나로 자리 잡을 가능성이 크다.
결론적으로, 양자 오류 완화는 양자 오류 정정을 대체하는 기술이 아니라, 대규모 범용 양자컴퓨팅이 실현되기 이전 단계에서 필수적인 보조 기술로 자리매김하고 있다. 향후 양자 하드웨어의 발전과 함께, 측정 오버헤드를 중심으로 한 자원 효율적 오류 완화 전략은 양자컴퓨팅의 실질적 활용 가능성을 결정짓는 핵심 요소가 될 것이다.
P.W. Shor, "Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer," SIAM Rev., vol. 41, no. 2, 1999, pp. 303-332.
M.A. Nielsen and L.C. Isaac, "Quantum computation and quantum information," Cambridge university press, 2011.
Y.C. Zhou et al., "High-fidelity geometric quantum gates exceeding 99.9% in germanium quantum dots," Nat. Commun., vol. 16, no. 7953, 2025.
I.D. Kivlichan et al., "Improved fault-tolerant quantum simulation of condensed-phase correlated electrons via trotterization," Quantum, vol. 4, 2020.
P.W. Shor, "Scheme for reducing decoherence in quantum computer memory," Phys. Rev. A, vol. 52, no. 4, 1995.
A.R. Calderbank and P.W. Shor, "Good quantum error-correcting codes exist," Phys. Rev. A, vol. 54, no. 2, 1996.
D. Gottesman, "Fault-tolerant quantum computation with constant overhead," Quantum Inf. Comput., vol. 14, 2014, pp. 1339-1371.
I. Dinur et al., "Locally testable codes with constant rate, distance, and locality," in Proc. Annu. ACM Symp. Theory Comput., (Rome, Italy), June 2022, pp. 357-374.
P. Panteleev and G. Kalachev, "Asymptotically good Quantum and locally testable classical LDPC codes," in Proc. Annu. ACM Symp. Theory Comput., (Rome, Italy), June 2022, pp. 375-388.
S.N. Filippov et al., "Scalability of quantum error mitigation techniques: from utility to advantage," arXiv preprint, 2024. doi: 10.48550/arXiv.2403.13542
V. Leyton-Ortega et al., "Quantum error mitigation by hidden inverses protocol in superconducting quantum devices," Quantum Sci. Technol., vol. 8, no. 1, 2023.
S. Zhang et al., "Error-mitigated quantum gates exceeding physical fidelities in a trapped-ion system," Nat. Commun., vol. 11, no. 587, 2020.
K. Temme et al., "Error mitigation for short-depth quantum circuits," Phys. Rev. Lett., vol. 119, no. 18, 2017.
A. Kandala et al., "Error mitigation extends the computational reach of a noisy quantum processor," Nature, vol. 567, no. 7749, 2019, pp. 491-495.
Y. Quek et al., "Exponentially tighter bounds on limitations of quantum error mitigation," Nat. Phys., vol. 20, no. 10, 2024, pp. 1648-1658.
E. van den Berg et al., "Probabilistic error cancellation with sparse Pauli-Lindblad models on noisy quantum processors," Nat. Phys., vol. 19, no. 8, 2023, pp. 1116-1121.
H. Liao et al., "Machine learning for practical quantum error mitigation," Nat. Mach. Intell., vol. 6, no. 12, 2024, pp. 1478-1486.
X. Bonet-Monroig et al., "Low-cost error mitigation by symmetry verification," Phys. Rev. A, vol. 98, no. 6, 2018.
J.R. McClean et al., "Decoding quantum errors with subspace expansions," Nat. Commun., vol. 11, no. 1, 2020.
E. van den Berg et al., "Model-free readout-error mitigation for quantum expectation values," Phys. Rev. A, vol. 105, no. 3, 2022.
W.J. Huggins et al., "Virtual distillation for quantum error mitigation," Phys. Rev. X, vol. 11, no. 4, 2021.
B. Koczor, "Exponential error suppression for near-term quantum devices," Phys. Rev. X, vol. 11, no. 3, 2021.
X.Y. Xu et al., "Circuit-noise-resilient virtual distillation," Commun. Phys., vol. 7, no. 1, 2024.
X. Yuan et al., "Virtual quantum resource distillation," Phys. Rev. Lett., 132.5 (2024): 050203.
A. Gonzales et al., "Quantum error mitigation by Pauli check sandwiching," Sci. Rep., vol. 13, no. 1, 2023.
J. Gao et al., "Pauli check sandwiching for quantum characterization and error mitigation during runtime," in Proc. IEEE Int. Conf. Quantum Comput. Eng., (Montreal, Canada), Sep. 2024, pp. 478–479.
Y. Guo and S. Yang, "Quantum error mitigation via matrix product operators," PRX Quantum, vol. 3, no. 4, 2022.
A.J. Ferris and D. Poulin, "Tensor networks and quantum error correction," arXiv preprint, 2013. doi: 10.48550/arXiv.1312.4578
S. Filippov et al., "Scalable tensor-network error mitigation for near-term quantum computing," arXiv preprint, 2023. doi: 10.48550/arXiv.2307.11740
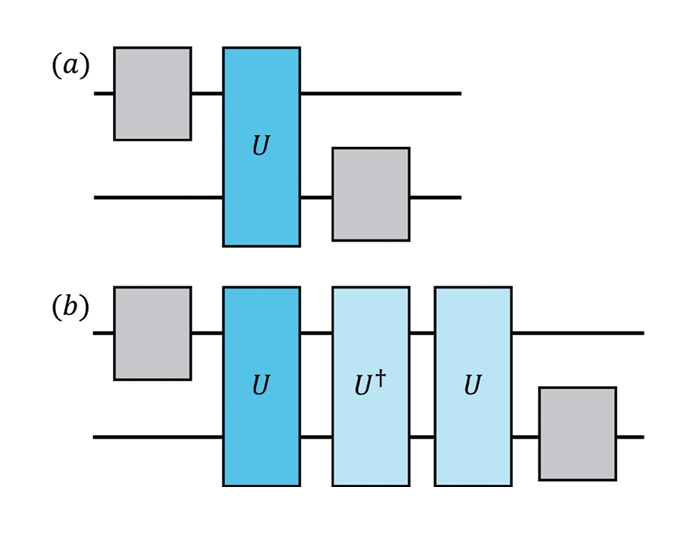
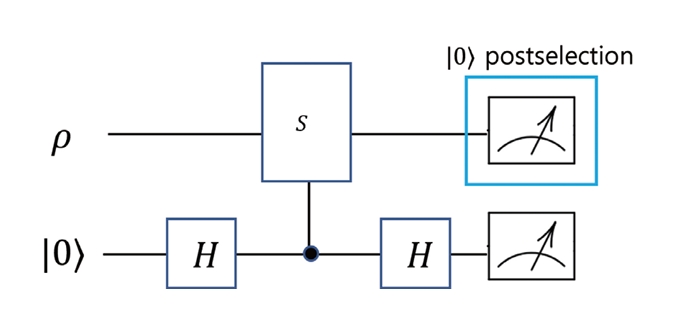
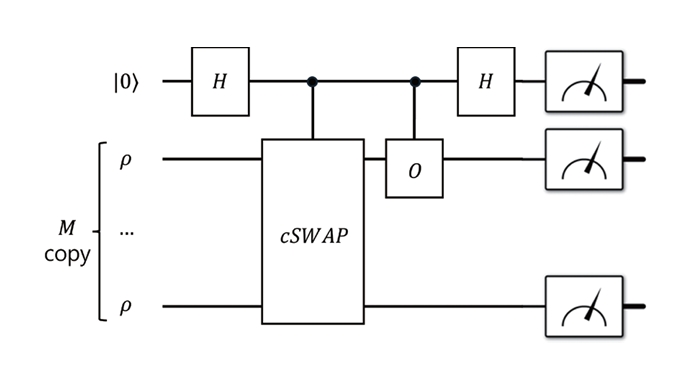
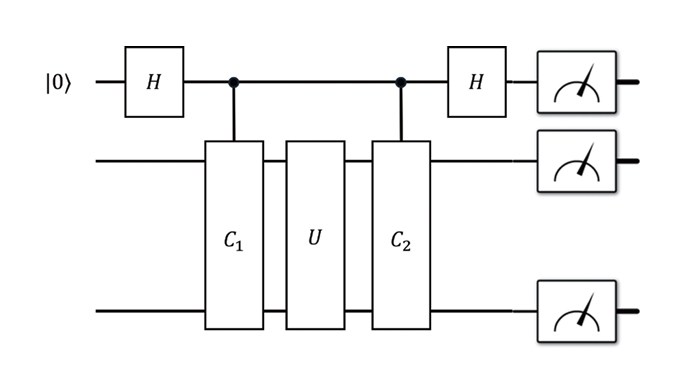
표 1 QEC와 QEM의 비교
| 목표 | 적용 시점 | 추가 큐비트 | 오류 제거 수준 | 장점 | 한계 | |
|---|---|---|---|---|---|---|
| QEC | 오류의 실시간 탐지 및 수정 | In-circuit | 다수의 큐비트 필요 | 이론적으로 완전한 정정 가능 | 장기적 확장성 | 높은 자원 요구량 |
| QEM | 측정 결과의 통계적 보정 | Post-processing & In-circuit | 대부분 적음 | 부분적 완화 | 구현 용이 & 단기 활용 가능 | 분산 증가 & 정확성 한계 |
표 2 오류 완화 기법별 오버헤드 비교
| ZNE | PEC | SV | VD | Pauli sandwich | TEM | |
|---|---|---|---|---|---|---|
| Qubit overhead | 0 | 0 | 1 | M | m | 0 |
| Sampling overhead |
| e4kλ | Tr(Pρnoisy)-1 |
| p-m | e2kλ |
| Reference | Quek, Yihui, et al.[17] | Van Den, Ewout, et al.[18] | McClean, Jarrod R., et al.[21] | Huggins, William J., et al.[23] | Gonzales, Alvin, et al.[27] | Filippov, Sergei, et al.[31] |
- Sign Up
- 전자통신동향분석 이메일 전자저널 구독을 원하시는 경우 정확한 이메일 주소를 입력하시기 바랍니다.